
© Nanduu, Photocase.com
Die Reaktionszeit ausgelasteter Internetzugänge steht und fällt mit dem Vorhandensein und der Art des Traffic Shaping im eigenen Gateway. Beim Zusammentreffen des stadtbekannten Wondershaper und einer selbst entwickelten Lösung des Magazin-Autors Martin Stern bleibt nur einer in der Senkrechten.
Auch die Besitzer eines schnellen oder gar symmetrischen DSL-Anschlusses kennen den Effekt: Während die Bürokollegen dicke E-Mails verschicken, ISO-Images runterladen und Videos schauen, gerät das eigene VoIP-Telefonat zur von Aussetzern und akustischen Artefakten geprägten Tortour – dagegen hilft nur Traffic Shaping [1]. Damit lassen sich die Latenzzeiten zeitkritischer Übertragungen auf ein Drittel bis ein Sechstel verringern. Das Bandbreitenmanagement hilft auch die Reaktionszeit von interaktiven SSH-, Rdesktop und ähnlichen Verbindung deutlich zu optimieren.
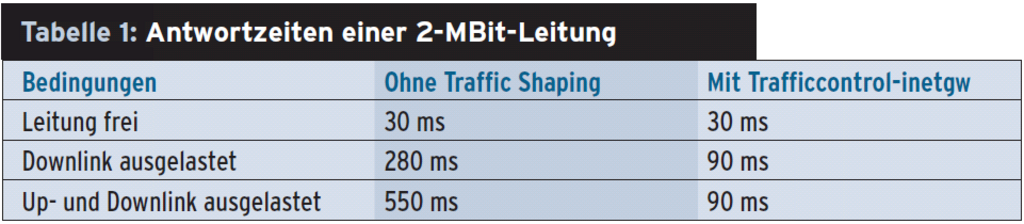
Tabelle 1 vergleicht die Ping-Zeiten auf einer symmetrischen 2-MBit/s-Internetstandleitung zwischen einem Debian Lenny ohne Traffic Shaping und der später in diesem Artikel vorgestellten Shaping-Lösung Trafficcontrol-inetgw. Die Nutzdatenrate lag während der Messung jeweils bei knapp 1,9 MBit/s, Gegenstelle war [www.google.de].
Warteschlangen vermeiden
Der beliebte Wondershaper [2] dient hier funktionell und in Sachen Performance als Referenz. Er verwendet für den Paketversand eine CBQ-QDisc [3] mit drei Warteschlangen. Dies erfüllt zwei Aufgaben:
- Es verhindert einen Stau im Modem, der normalerweise deshalb
entsteht, weil DSL-Router und Kabelmodems Datenpakete wesentlich
schneller aus dem LAN empfangen als diese sich ins Internet
versenden lassen. Der Router verwaltet daher eine manchmal mehrere
Sekunden lange Warteschlange, die sich der Kontrolle des
Linux-Kernels entzieht (Abbildung 1). Die CBQ-QDisc dagegen
gestattet den Paketversand in Richtung Router nur, solange dort
eine bestimmte Bandbreite unterschritten ist. Die hat der
Administrator so zu konfigurieren, dass sich gerade keine
Warteschlange aufbaut. (Der Kasten “Glossar” und [4]
helfen beim Navigieren durch die etwas komplizierte
Begriffswelt.) - Zum anderen kann der Kernel Pakete auf die drei Warteschlangen
den gewünschten Antwortzeiten entsprechend verteilen. Die
CBQ-QDisc arbeitet die Warteschlangen nach ihrer Priorität ab
und bevorzugt Latenz-empfindliche Pakete damit deutlich. Das hat
mehrere Vorteile. So kommen ACK-Pakete schneller auf den Weg,
wodurch ein Upload einen Download weniger ausbremst. Auch SSH- und
ICMP-Pakete erfahren bevorzugte Abfertigung, weitere Protokolle
lassen sich leicht ergänzen. Sinnvoll ist das natürlich
nur, solange keine zusätzliche Warteschlange im Modem
existiert.
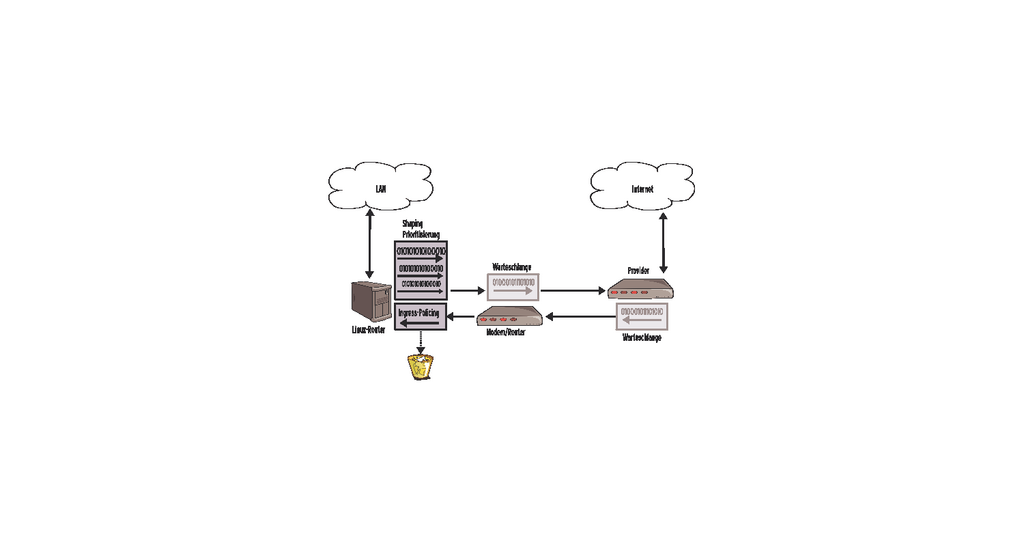
Abbildung 1: Beim Up- und Download bilden sich an mehreren Stellen Warteschlangen. Wer die Reaktionszeit optimieren will, sollten ihr Entstehen beim Provider und im eigenen DSL-Modem oder -Router vermeiden. Der Linux-Kernel hilft mit Shaping und Policing dabei.
|
Glossar |
|---|
|
Ingress: Eingehender Datenstrom. Egress: Ausgehende Datenstrom. Classifying: Pakete mit Filtern priorisieren und einer Warteschlange zuweisen [7]. Shaping: Hält Pakete in einer Warteschlange zurück, sobald der ausgehende Datenstrom (Egress) eine bestimmte Bandbreite überschreitet. Läuft die Warteschlange voll, werden neue Pakete verworfen. QDisc: Im Linux-Kernel gibt es verschiedene Queueing Disciplines, also Regeln, nach denen ausgehende Pakete Schlange stehen. Einige QDiscs sind hierarchisch aufgebaut und dürfen weitere Klassen und QDiscs enthalten. Man spricht dann von “classful”. CBQ: Das Class Based Queueing ist einer von mehreren Mechanismen, um priorisierte Pakete abzuarbeiten. Dazu gibt es mehrere unterschiedlich priorisierte Queues, die ein Weighted-Round-Robin-Prozess (WRR) abklappert. Zum Beispiel versendet er zehn Pakete von Queue 1, anschließend fünf Pakete von Queue 2, eines von Queue 3 und dann wieder zehn von Queue 1 und so weiter [3]. HTB: Die seit Kernel 2.4.20 fest in den Kernel integriert Discipline “Hierarchical Token Bucket” funktioniert ähnlich wie Class Based Queueing, aber mit einem Token-Bucket-Filter: Wie CBQ teilt HTB die verfügbare Bandbreite auf mehrere Klassen auf und garantiert jeder Klasse auch bei starker Auslastung eine gewisse Bandbreite. Überschüssige Bandbreiten verteilt HTB auf die anderen Klassen [10]. Policing: Verwirft bestimmte Ingress-Pakete. |
Für eingehende Datenpakete bietet der Kernel leider deutlich weniger Möglichkeiten als für den Versand – warum auch, schließlich ergibt es keinen Sinn, ein gerade eingetroffenes Paket erst mal in einer Warteschlange zu deponieren. Eine Warteschlange bildet sich im Downstream trotzdem: beim Provider. Während eines Downloads treffen dort Pakete nämlich deutlich schneller ein, als sie sich an den Kunden weiterleiten lassen.
Um den Stau in der Warteschlange beim Provider zu minimieren, bleibt dem Kunden nur, diesen um einen langsameren Versand zu bitten. Dazu bietet der Linux-Kernel die Ingress-QDisc [5]. Sie erlaubt es, nur bestimmte Pakete zu verwerfen. Der Absender einer TCP-Verbindung schickt das Paket daraufhin erneut und drosselt die Transferrate.
Auch der Wondershaper benutzt die Ingress-QDisc, um Pakete zu verwerfen, sobald der eingehende Datenstrom eine vom Administrator gewählte maximale Bandbreite überschreitet. Leider verwirft die Ingress-QDiscs so gelegentlich auch ACK-Pakete eines Uploads oder andere empfindliche Pakete, was die Latenzen für interaktive Anwendungen erhöht.
Einige noch wenig bekannte Optionen im TC-Subsystem des Kernels versprechen jedoch Hilfe, um Pakete differenzierter zu behandeln, als Wondershaper und andere Traffic-Shaping-Software das tun. Das jetzt vorstellte Trafficcontrol-inetgw [6] ist als Komplettlösung zur Latenzoptimierung auf Internetgateways mit dynamischer Overhead-Berechnung und differenziertem Ingress-Policing ausgelegt.
Dynamischer Overhead
Um die Warteschlangen im lokalem Modem und beim Provider zu vermeiden, muss der Linux-Kernel die übertragenen Paketgrößen inklusive aller Overheads kennen. Daraus ergibt sich die Bandbreite, die wirklich über den Internetzugang läuft. Beim Versand eines TCP-Pakets über DSL kommen zu den Nutzdaten die Header für TCP, IP, PPP, PPPoE, Ethernet und ATM. Besonders trickreich ist, dass ein Ethernet-Paket mindestens 64 Bytes groß sein muss und eine ATM-Zelle immer genau 53 Bytes umfasst. Bei ATM gibt es noch eine Besonderheit. Die letzte für ein Ethernet-Paket verwendete Zelle fasst nur 40 Bytes Nutzdaten, alle vorher 48. Das Modem füllt die fehlenden Bytes mit Nullen auf. Tabelle 2 verdeutlicht die quantitativen Zusammenhänge.
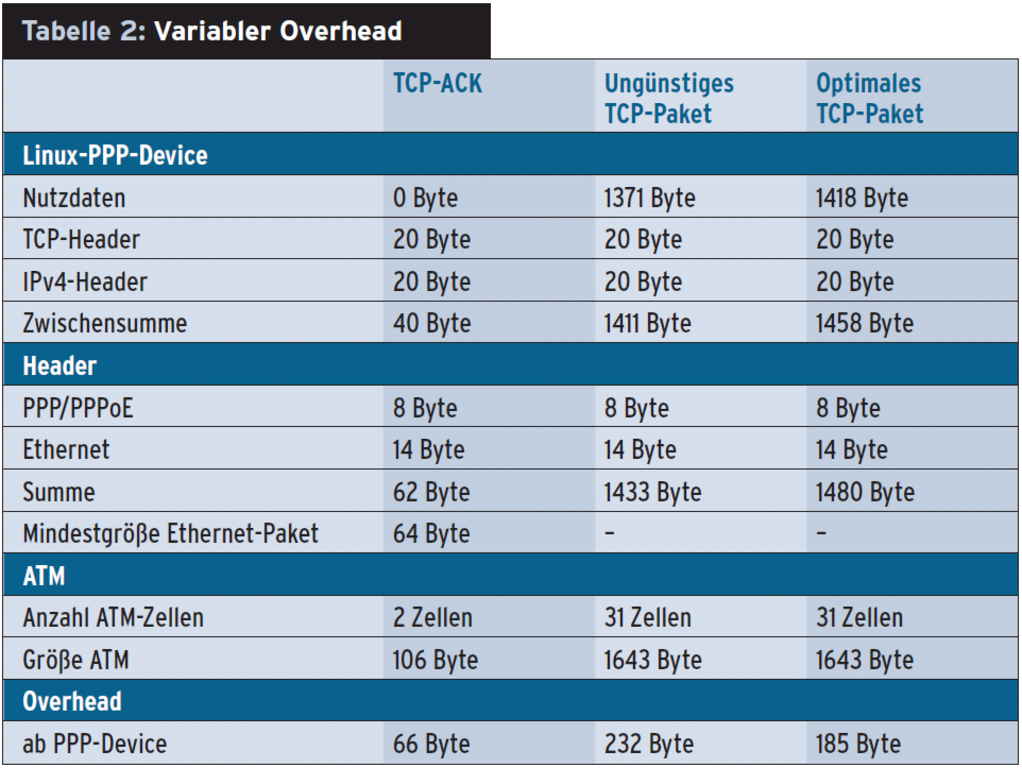
Der Overhead eines Datenpakets ist also nicht konstant, sondern abhängig von der Nutzdatenmenge. Erst neuere Linux-Kernel zusammen mit neueren IProute-Versionen können die Rohdatenmenge im ATM-Netz korrekt berechnen ([8], [9]) – vorausgesetzt man verwendet eine QDisc, die das unterstützt, etwa Hierarchical Token Bucket (HTB, [10]). Dort gibt es den neuen Parameter »linklay«, der die ATM-Rohdatenmenge korrekt berechnet. Für die Root-HTB-Klasse zum Beispiel sieht das so aus:
tc class add dev ppp0 parent 1: classid 1:1 htb rate 205kbit ceil 205kbit linklay atm
(Siehe Listing 1, ab Zeile 77.) Auch beim Ingress-Policing (Empfang) ist der Parameter erlaubt:
tc filter add dev ppp0 parent ffff: protocol ip prio 110 u32 match ip src 0.0.0.0/0 flowid :1 police rate 1710kbit burst 6k linklay atm conform-exceed continue/ok
(Siehe Listing 1, ab Zeile 144.) Außer ATM unterstützt »linklay« zurzeit Ethernet als Übertragungsschicht.
|
Listing 1: |
|---|
001 #!/bin/bash
002 #Latenzoptimierung für Internetgateways
003 #Martin Stern, 2010 Lizenz: GPL
004 PATH=/usr/sbin:/usr/bin:/sbin:/bin
005
006 #IPTables Bibliotheksverzeichnis gegebenen-
007 #falls für tc überschreiben.
008 #export IPTABLES_LIB_DIR=/usr/local/lib/...
009
010 # Hilfe ausgeben
011 if [ $# -eq 0 -o -$# -gt 3 ]; then
012 echo -e "Usage:"
013 echo -e "$0 [device]"
014 echo -e " Statistiken anzeigenn"
015 echo -e "$0 [device] clear"
016 echo -e " Trafficcontrol deaktivierenn"
017 echo -e "$0 [device] [downlink] [uplink]"
018 echo -e " Trafficcontrol einrichten."
019 echo -e " Downlink/Uplink in Kilobit/s,"
020 exit 1
021 fi
022
023 # Statistic ausgeben
024 if [ $# -eq 1 ]; then
025 echo -e "nQDisc Statistik:"
026 echo -e "-------------------------"
027 tc -s qdisc ls dev $1
028 echo -e "nClass Statistik:"
029 echo -e "-------------------------"
030 tc -s class ls dev $1
031 echo -e "nFilter Statistik:"
032 echo -e "-------------------------"
033 tc -s filter ls dev $1
034 echo -e "nIngress Filter Statistik:"
035 echo -e "-------------------------"
036 tc -s filter ls parent ffff: dev $1
037 exit
038 fi
039
040 # Konfiguration zurücksetzten
041 if [ $# -eq 2 ]; then
042 tc qdisc del dev $1 root
043 tc qdisc del dev $1 ingress
044 exit
045 fi
046
047 ###########################################
048 #Neue Konfiguration erstellen
049 DEV=$1
050 DOWN=$2
051 UP=$3
052
053 #Alte Konfiguration löschen
054 tc qdisc del dev $DEV root &> /dev/null
055 tc qdisc del dev $DEV ingress &> /dev/null
056
057
058 ###########################################
059 #Uplink konfigurieren (egress)
060
061 #Minimales Quantum festlegen
062 SmallQ=""; BigQ=""
063 z=$((${UP}/10*128/3))
064 if [ $z -lt 1500 ]; then
065 SmallQ="quantum 1500"
066 fi
067 z=$((${UP}/10*128))
068 if [ $z -lt 1500 ]; then
069 BigQ="quantum 1500"
070 fi
071
072 #Root HTB QDisc
073 tc qdisc add dev $DEV root handle 1: htb
074 default 11
075
076 #Root HTB Klasse
077 tcc="tc class add dev $DEV parent"
078 $tcc 1: classid 1:1 htb
079 rate ${UP}kbit ceil ${UP}kbit
080 linklay atm $BigQ
081
082 #HTB Klasse 1:10 "Low Latency"
083 $tcc 1:1 classid 1:10 htb
084 rate $(($UP/3))kbit ceil ${UP}kbit
085 prio 0 linklay atm $SmallQ
086
087 #HTB Klasse 1:11 "Bulk and Default"
088 $tcc 1:1 classid 1:11 htb
089 rate $(($UP/3))kbit ceil ${UP}kbit
090 prio 1 linklay atm $SmallQ
091
092 #HTB Klasse 1:12 "Second-Order Bandwidth"
093 $tcc 1:1 classid 1:12 htb
094 rate $(($UP/3))kbit ceil ${UP}kbit
095 prio 2 linklay atm $SmallQ
096
097 #Stochastic Fairness Qdisc für alle drei
098 tcq="tc qdisc add dev $DEV parent"
099 $tcq 1:10 handle 10: sfq perturb 10
100 $tcq 1:11 handle 11: sfq perturb 10
101 $tcq 1:12 handle 12: sfq perturb 10
102
103 #Pakete den HTB Klassen zuweisen.
104 #Der erste passende Filter gilt.
105 #ACK -> "Low Latency"
106 tcf="tc filter add dev $DEV parent"
107 $tcf 1: protocol ip prio 22 u32
108 match ip protocol 6 0xff
109 match u8 0x05 0x0f at 0
110 match u16 0x0000 0xffc0 at 2
111 flowid 1:10
112
113 #TOS Minimum Delay -> "Low Latency"
114 $tcf 1: protocol ip prio 10 u32
115 match ip tos 0x10 0xff flowid 1:10
116
117 #IPTables fwmark 10 -> "Low Latency"
118 $tcf 1: protocol ip prio 16
119 handle 10 fw flowid 1:10
120
121 #IPTables fwmark 11 -> "Bulk and Default"
122 $tcf 1: protocol ip prio 18
123 handle 11 fw flowid 1:11
124
125 #IPTables fwmark 12 -> "Second-Order B.w."
126 $tcf 1: protocol ip prio 20
127 handle 12 fw flowid 1:12
128
129 #ICMP -> "Low Latency"
130 $tcf 1: protocol ip prio 24 u32
131 match ip protocol 1 0xff flowid 1:10
132
133 #DEFAULT -> "Bulk and Default"
134 $tcf 1: protocol ip prio 50 u32
135 match ip dst 0.0.0.0/0 flowid 1:11
136
137 ###########################################
138 #Downlink konfigurieren (ingress)
139
140 #Ingress Root Qdisc anlegen.
141 tc qdisc add dev $DEV handle ffff: ingress
142
143 #Wenn über 98% Auslastung ...
144 $tcf ffff: protocol ip prio 110 u32
145 match ip src 0.0.0.0/0 flowid :1
146 police rate $((${DOWN}*98/100))kbit
147 burst 6k linklay atm
148 conform-exceed continue/ok
149
150 #... dann überzählige Pakete markieren.
151 $tcf ffff: protocol ip prio 111 u32
152 match u32 0 0 flowid :1
153 action ipt -j MARK --set-mark 20
154 action continue > /dev/null
155
156 #Wenn mehr als 1 weiteres % Auslastung ...
157 $tcf ffff: protocol ip prio 120 u32
158 match ip src 0.0.0.0/0 flowid :1
159 police rate $((${DOWN}*1/100))kbit
160 burst 8k linklay atm
161 conform-exceed continue/ok
162
163 #... dann große Pakete verwerfen.
164 $tcf ffff: protocol ip prio 121 u32
165 match u16 0x0400 0x0400 at 2 flowid :1
166 police rate 0kbit burst 2k linklay atm
167 conform-exceed drop/drop
168 $tcf ffff: protocol ip prio 122 u32
169 match u16 0x0800 0x0800 at 2 flowid :1
170 police rate 0kbit burst 2k linklay atm
171 conform-exceed drop/drop
172
173 #Wenn noch 1% Auslastung => verwerfen.
174 $tcf ffff: protocol ip prio 130 u32
175 match ip src 0.0.0.0/0 flowid :1
176 police rate $((${DOWN}*1/100))kbit
177 burst 10k linklay atm
178 conform-exceed drop/drop
|
Auch mit betagtem Kernel
Wenn die gewünschte QDisc »linklay« nicht unterstützt, der Kernel zu alt ist oder gar eine exotische Übertragungsschicht im Spiel ist, gelingt es mit zwei Parametern dem Kernel oft, trotzdem die Rohdatenmenge zu berechnen:
- »mpu« gibt die minimale Größe in Bytes
an, die ein IP-Paket beim Übertragen hat. Für einen
DSL-Anschluss sind das 106 (zwei ATM-Zellen). - »overhead« gibt die Byte-Anzahl an, die zur
Paketgröße des verwendeten Linux-Netzwerkdevice zu
addieren ist. Für den PPP- und Ethernet-Header müsste der
Wert 22 Bytes sein. Der Autor hat jedoch experimentell ermittelt,
dass auf einem ADSL-Anschluss »14« eine kürzere
Antwortzeit erzielt.
Hier ein Beispiel für eine Root-HTB-Klasse mit beiden Parametern:
tc class add dev ppp0 parent 1: classid 1:1 htb rate 205kbit ceil 205kbit mpu 106 overhead 14
Versuche zeigten, dass »mpu« und »overhead« mit »linklay atm« zu kombinieren die Reaktionszeit tendenziell erhöht.
Performance-Vergleiche
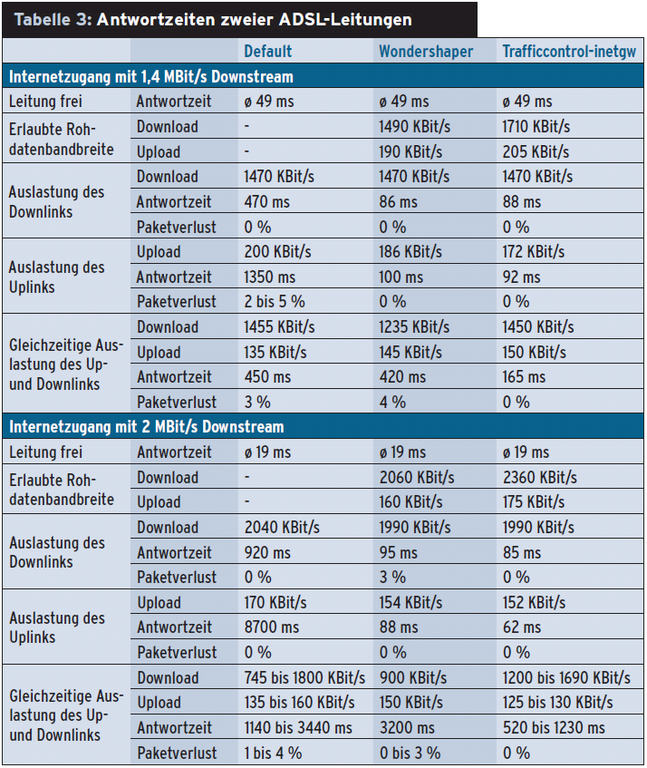
Wie in der oberen Hälfte von Tabelle 3 zu sehen ist, erreicht das Skript »trafficcontrol-inetgw« mit HTB als QDisc und »linklay atm« kürzere Reaktionszeiten bei leicht höherer Bandbreite als der Wondershaper. Die Messungen liefen mit 100 Ping-Paketen bei einem Paket pro Sekunde zu einem möglichst nahen Router im Internet. Deutlich weicht die erzielte Nutzdatenbandbreite von der erlaubten Rohdatenbandbreite ab.
Bei separaten Up- oder Downloads leidet der Wondershaper noch nicht an der fehlenden Overhead-Berechnung, da die durch Shaping begrenzte Bandbreite eine ausreichende Lücke zur Rohbandbreite lässt. Die Differenz entspricht dem Overhead. Die kleinen ACK-Pakete lasten die andere Übertragungsrichtung nicht aus. Gleichzeitige Up- und Downloads machen jedoch den Vorteil einer dynamischen Overhead-Berechnung deutlich. Jetzt kommt der prozentual sehr große Overhead der ACK-Pakete zum Tragen. Ohne dynamische Berechnung des Overheads will das Gateway mehr Daten übertragen, als der Anschluss bewältigen kann, und es bilden sich Warteschlangen.
Die untere Hälfte von Tabelle 3 zeigt das Ergebnis für einen anderen Internetzugang. Dort ist zu sehen, dass einige ADSL-Zugänge empfindlich auf gleichzeitige Up- und Downloads reagieren und stark schwankende Ergebnisse liefern. Leider hat der Linux-Kernel keine Möglichkeit, sich diesem Verhalten anzupassen.
So funktioniert Trafficcontrol-inetgw
Die Zeilen 61 bis 101 von Listing 1 richten Egress-Shaping für den Upload ein. Initial berechnet der Algorithmus ab Zeile 61 ein minimales Quantum für die HTB-Klassen. HTB-Klassen leihen sich gegenseitig Bandbreite, wenn eine Klasse weniger benötigt, als ihr »rate« zuweist, und eine andere gerade Bedarf hat. Quantum gibt dabei die minimale Anzahl auf einmal verleihbarer Bytes an. Es muss größer als die MTU sein, aber so klein wie möglich. Leider berechnet HTB bei den kleinen Upstream-Bandbreiten einiger ADSL-Anschlüsse ein zu kleines Quantum. Das führt zu einer Fehleinschätzung der genutzten Rohdatenbandbreite und damit zu einer Warteschlange im Modem.
Zeile 76 legt die Root-HTB-Klasse an. Sie hat die Aufgabe, die genutze Upstream-Rohdatenbandbreite per »rate« und »ceil« auf das vom Administrator konfigurierte Maß zu beschränken. Die Zeilen 82 bis 95 legen drei priorisierte HTB-Klassen für die einzelnen Verbindungstypen an. Die Klasse 1:10 “Low Latency” hat die höchste Priorität und 1:12 “Second-Order Bandwidth” die niedrigste. Der Parameter »ceil« bestimmt dabei die Bandbreite, die eine Klasse maximal nutzen darf. Dagegen beschreibt »rate« die für sie reservierte Bandbreite.
Jede Klasse darf immer so viel Bandbreite nutzen, wie ihr »rate« beschreibt. Benötigt sie mehr, kann sie bis zu »ceil« Bandbreite von anderen Klassen leihen – vorausgesetzt dort sind Kapazitäten frei. Wollen mehrere Klassen Bandbreite leihen, erfährt die mit der niedrigeren Priorität eine Bevorzugung.
Ab Zeile 97 legen »tc«-Aufrufe in jeder der drei HTB-Klassen eine Stochastic Fairness Qdisc (SFQ) an [11], was die verschiedenen Verbindungen innerhalb einer Klasse gleichberechtigt behandelt – normalweise sind Verbindungen mit hohem Bandbreitenbedarf nämlich implizit bevorzugt.
Feingranulare Filter
Die nun folgende Filter-Sektion weist ausgehenden Pakete einer der drei HTB-Klassen zu. Klasse 1:10 “Low Latency” erhält alle, die eine niedrige Latenz benötigen und voraussichtlich wenig Bandbreite belegen. Das sind kleine TCP-ACK- und alle ICMP-Pakete (Zeilen 106 und 129). Dazu kommen solche, deren IP-Header im TOS-Feld das “Low Latency”-Bit enthält (Zeile 113) oder denen IPtables »10« als Marke verpasst hat (Zeile 117).
Die »u8«- und »u16«-Filterausdrücke ab Zeile 109 prüfen, ob bestimmte Bits im IP-Header gesetzt sind [12]. Das erfasst alle Pakete mit weniger als 64 Bytes, in der Regel ACK-Pakete. Da sich die bis zu 80 Bytes großen SACK-Pakete nur aufwändig herausfiltern ließen, erhalten sie in Listing 2 ab Zeile 22 einfach die Marke »10« aufgedrückt. Die Klasse 1:11 “Bulk and Default” ist für Datenpakete gedacht, die entweder keine besonders niedrige Antwortzeit benötigen oder für “Low Latency” zu viel Bandbreite verbrauchen. HTTP-Pakete, die beim interaktiven Surfen entstehen, gehören hierhin. Zeile 133 erfasst alle Pakete, auf die kein anderer Filter angesprochen hat.
|
Listing 2: |
|---|
01 #IPtables-Regeln (egress) 02 #Letzte passende Regel gilt. 03 04 /sbin/iptables -t mangle -F 05 ipt1="/sbin/iptables -A POSTROUTING " 06 ipt="$ipt1 -t mangle -o $DEV -p tcp" 07 08 $ipt -m multiport --port 3389 09 -j MARK --set-mark 10 #RDesktop 10 $ipt -m multiport --port 5900:5902 11 -j MARK --set-mark 10 #VNC 12 $ipt -m multiport --port smtp,ssmtp 13 -j MARK --set-mark 12 #Mailversand 14 15 #Uploads > 10MB => "Second-Order Bandwidth" 16 $ipt -m connbytes --connbytes-dir both 17 --connbytes-mode bytes 18 --connbytes 10485760: 19 -m multiport --port www,https,ftp-data 20 -j MARK --set-mark 12 21 22 #Große TCP-ACK-Pakete => "Low Latency" 23 $ipt -m conntrack --ctstate ESTABLISHED 24 -m length --length 0:128 25 --tcp-flags ACK ACK 26 -j MARK --set-mark 10 |
Für Pakete, die ruhig ein paar Millisekunden warten dürfen, gibt es die Klasse 1:12 “Second-Order Bandwidth”, die Zeile 125 erfasst. Die Klasse für Pakete mit der Marke »12« ist vor allem für große Uploads gedacht, die nicht den oft knappen Upstream verstopfen sollen. Um große Uploads vom Surfen zu unterscheiden, markiert Listing 2 ab Zeile 15 Pakete der Typen HTTP und FTP genau dann mit »12«, wenn sie zu einer Verbindung gehören, die schon mehr als 10 MByte Nutzdaten transportiert hat.
In Listing 2 kann der Administrator weitere Protokolle einer der drei HTB-Klassen zuweisen. Wie das Beispiel der großen Uploads zeigt, geht die Granularität von IPtables dabei weit über die von »tc filter« hinaus. Zu beachten ist, dass beim Markieren im IPtables-Skript die letzte Regel greift, während bei »tc filter« in Listing 1 die erste Regel signifikant ist.
Policing
Eine Besonderheit von Trafficcontrol-inetgw ist das differenzierte Ingress-Policing: Statt lediglich beliebige Pakete zu verwerfen, sobald der Downstream die Rohdatenbandbreite überschreitet, analysiert Trafficcontrol-inetgw den Typ des Pakets und verwirft nur solche, auf die es weniger ankommt. Wegen der reduzierten Möglichkeiten des Linux-Kernels beim Ingress, arbeitet Trafficcontrol-inetgw anders als bei Egress ohne Warteschlangen. Jedes Paket durchläuft eine Reihe von Filtern, danach entscheidet Trafficcontrol-inetgw über Annahme oder Verweigerung.
Zeile 143 von Listing 1 prüft für jedes eingehende Paket, ob insgesamt 98 Prozent der vom Administrator konfigurierten Rohdatenbandbreite überschritten sind. Ist das nicht der Fall, nimmt das System das Paket ohne weitere Prüfung an. Die Anweisung »conform-exceed continue/ok« beschreibt, was zu tun ist, wenn der Filter zutrifft (»continue«: weiter mit dem nächsten Filter) oder nicht zutrifft (»ok«: Paket annehmen).
Sind 98 Prozent der Rohdatenbandbreite überschritten, bekommen bis zu 2 Prozent der Pakete ab Zeile 150 die IPtables-Marke »20« aufgedrückt. Diese Pakete verarbeitet dann das Skript »iptables-ingress« (Listing 3) weiter. Es verwirft einzelne Pakete, wenn sie zu einem HTTP- oder FTP-Download gehören, der bereits mehr als 10 MByte Nutzdaten transportiert hat. Die Strategie: Besser schon bei 98 Prozent große Downloads etwas abbremsen, als später das ACK-Paket einer ausgehenden Verbindung verwerfen müssen.
Bei dem Filter ab Zeile 156 kommen nur die Pakete an, die den Filter in Zeile 143 passiert haben. Hier klärt sich, ob diese Pakete 1 Prozent der Rohdatenbandbreite überschreiten, der Downstream also zu 99 Prozent ausgelastet ist. Wenn ja, gehen ab Zeile 163 einzelne, mindestens 1024 Bytes große Pakete über den Jordan. Das begünstigt ACK-, SSH- und ähnliche Pakete auch dann, wenn die IPtables-Regel in Listing 3 nicht greift, weil keine großen Downloads vorliegen. Erst wenn der Downlink trotzdem zu 100 Prozent ausgelastet ist, verwirft ein Algorithmus ab Zeile 173 auch beliebige Pakete.
|
Listing 3: |
|---|
01 # IPTables Regeln (ingress) 02 for CHAIN in FORWARD INPUT; do 03 /sbin/iptables -A $CHAIN -i $DEV -p tcp 04 -m connbytes --connbytes-dir both 05 --connbytes-mode bytes 06 --connbytes 10485760: 07 -m multiport --port www,https,ftp-data 08 -m mark --mark=20 09 -m length --length 500: 10 -j DROP 11 done |
Die Software installieren
Das in Listing 1 abgedruckte »trafficcontrol-inetgw« fußt auf Wondershaper, erweitert ihn aber in einigen Punkten. Das Skript benötigt mindestens Kernel 2.6.24 [8] und IProute 20080725. Zur Installation lädt der Administrator die vier in Tabelle 4 genannten Dateien von [6] herunter und kopiert sie nach »/usr/local/bin/«. Dann erweitert er seine Firewall um die Regeln aus Listing 2. Liegt sie als Bash-Skript vor, genügt die folgende Ergänzung:
DEV="Device " source /usr/local/bin/iptables-egress
Danach empfiehlt sich ein Testlauf mit »trafficcontrol-inetgw Device geschätzte_Uplink-Rohdatenbandbreite geschätzte_Downlink-Rohdatenbandbreite«. Kommt keine Fehlermeldung, hat alles geklappt. Dann kann man mit »trafficcontrol-inetgw Device« Statistiken abrufen und das System mit »trafficcontrol-inetgw Device clear« wieder dekonfigurieren.

Mit einigen Versionen von IPtables, zum Beispiel 1.4.2 in Debian Lenny, tritt das Problem auf, dass Tc aus dem IProute-Paket die IPtables-Bibliotheken nicht findet, da sie nach »/lib/xtables« verschoben und umbenannt sind. Wer »trafficcontrol-inetgw« aufruft, erhält dann bei Zeile 153 die Meldung »/lib/iptables/libipt_mark.so: cannot open shared object file: No such file or directory failed to find target MARK«. Als Workaround kann der Administrator das »/lib/iptables«-Verzeichnis einer älteren Version nach »/usr/local/lib/oldiptables« kopieren und das »tc« in Zeile 8 mit der Umgebungsvariablen »IPTABLES_LIB_DIR« bekanntgeben.
Die Suche nach einem geeigneten Partner
Zum Testen des Setups benötigt der Administrator einen Host zum Anpingen, der nur wenige Hops entfernt im Internet steht. Die Antwortzeit der Ping-Pakete soll die Latenz des Internetzugangs messen und möglichst wenig vom sonstigem Verkehr im Internet beeinflusst sein. Wenn der Point-to-Point-Partner beim eigenen Provider nicht auf Ping reagiert, lässt der Admin sich mit »mtr -ntrc3 www.google.de« alle Router auf dem Weg zu Google anzeigen. Anschließend probiert er nacheinander, ob sie auf Ping reagieren. Der erste Router, der ohne Paketverluste auf »ping IP-Nummer« antwortet, empfiehlt sich als Gegenstelle.
Das Skript »trafficcontrol-searchbw« (hier nicht abgedruckt, aber bei [6] zu finden) unterstützt den Administrator beim Suchen der Rohdatenbandbreite. Statt vieler Testläufe mit »trafficcontrol-inetgw« und anschließendem Ping reicht ein Aufruf zum Untersuchen eines Bandbreitenintervalls. Zuerst ergänzt er in Zeile 18 des Skripts die gerade ermittelte IP-Nummer in der Variablen »PingHost«. Nun startet er einige große Downloads, um den Downlink konstant auszulasten. Mit
trafficcontrol-searchbwDevice DOWNUntergrenze-Obergrenze Schrittweite Ping-Anzahl Upstream
startet eine erste Übersichtsmessung. Die einzelnen Parameter in korrekter Reihenfolge erklärt Tabelle 5. Ein Beispiel: »trafficcontrol-searchbw ppp0 DOWN 1300-1800 50 5 210«. Das Intervall von 1300 bis 1800 KBit/s Downlink-Rohdatenbandbreite entspricht dabei einer ersten Schätzung das Anwenders. Die 210 KBit/s für den Upstream sind ebenfalls geraten, aber bei dieser Messung nicht wichtig. Abbildung 2 zeigt das Ergebnis.

Abbildung 2: Eine Übersichtsmessreihe von erzielten Nutzbandbreiten und Ping-Zeiten. Deutlich zu sehen ist der Latenzsprung zwischen 1700 und 1750 KBit/s – in diesem Bereich liegt die optimale Bandbreite.
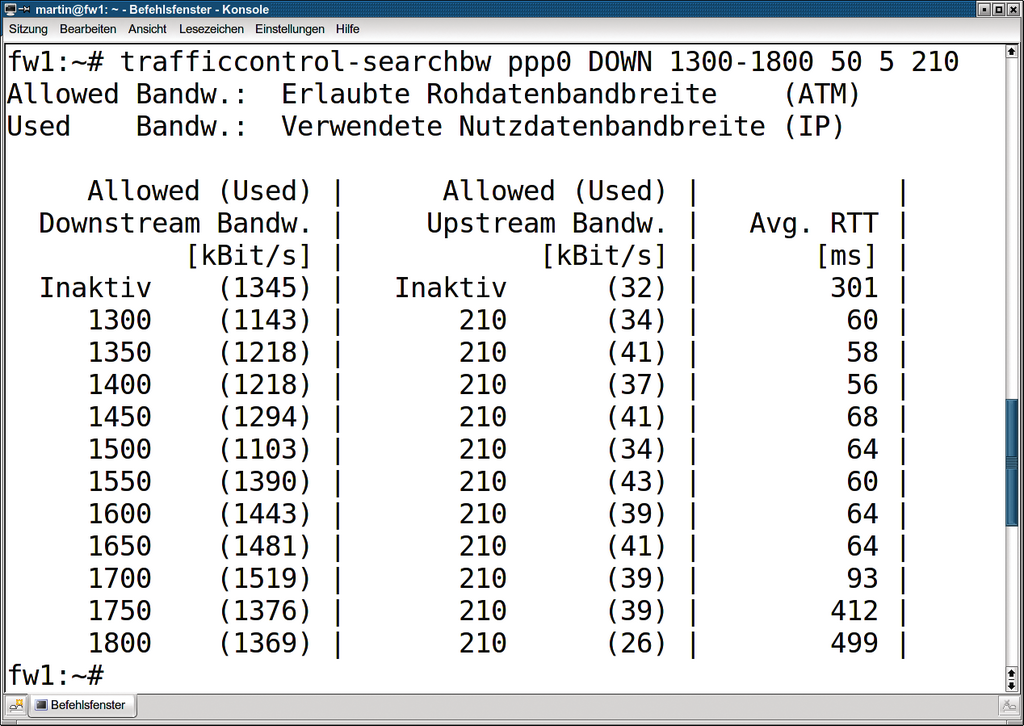
Abbildung 2: Eine Übersichtsmessreihe von erzielten Nutzbandbreiten und Ping-Zeiten. Deutlich zu sehen ist der Latenzsprung zwischen 1700 und 1750 KBit/s – in diesem Bereich liegt die optimale Bandbreite.
Nach der Übersichtsmessung startet der Administrator eine Detailmessung des interessanten Intervalls. Wie in Abbildung 3 zu sehen, reduziert er dabei die Schrittweite und erhöht die Anzahl der Pings: »trafficcontrol-searchbw ppp0 DOWN 1650-1750 20 100 210«.
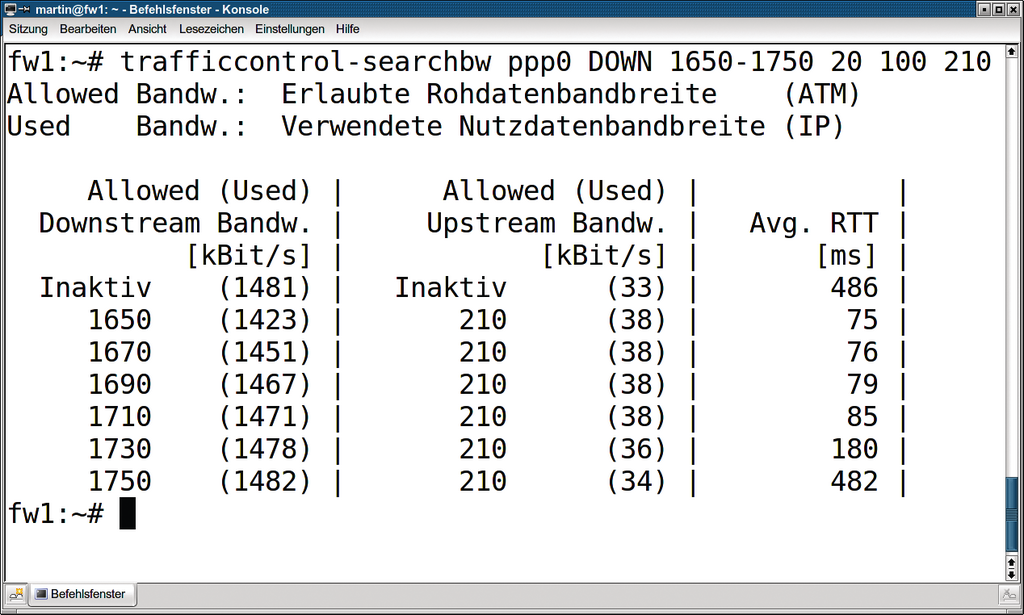
Abbildung 3: Detailmessreihe für das in Abbildung 2 ermittelte Rohbandbreiten-Intervall. Die optimale Rohbandbreite liegt bei 1710 KBit/s, da hier die Latenz bei ausgelastetem Downlink noch unter 100 ms liegt. Damit liefert der Router 1471 KBit/s Nutzdaten. Die Ergebnisse sind genauer als in Abbildung 2, da hier wesentlich länger gemessen wurde.
Da diese Messung recht lange läuft, muss der Admin darauf achten, dass die Downloads stabil bleiben. Die jeweils gemessene Nutzdatenbandbreite sieht er in der Ausgabe. Bricht sie ein, muss er die Messung wiederholen. Außerdem darf der Uplink nicht nennenswert anderweitig genutzt sein. Dies erhöht die Latenz und verfälscht damit das Ergebnis. Auch hier sollte er in der Ausgabe die Upstream-Bandbreite prüfen und die Messung gegebenenfalls wiederholen.
Nun kann der Administrator seine optimale Rohdatenbandbreite für den Downlink ablesen. Es ist die letzte Zeile, die noch eine akzeptable Antwortzeit unter 100 Millisekunden erzielt. Anschließend wiederholt er die Messungen für den Uplink. Steht kein FTP-Server zum Hochladen der Daten ins Internet bereit, kann er sich selbst E-Mails mit sehr großen Attachments schicken. Die Messung muss aber abgeschlossen sein, bevor das System die E-Mails wieder herunterlädt. Ein Beispielkommando für eine Uplink-Übersichtsmessung lautet: »trafficcontrol-searchbw ppp0 UP 150-250 10 5 1710«.
Der Systemstart
Um das System beim Booten zu konfigurieren, fügt der Administrator das Kommando »trafficcontrol-inetgw« zu einem seiner Startskripte hinzu. Bei einem DSL-Zugang zum Beispiel empfiehlt es sich
#!/bin/sh case "$PPP_IFACE" inDevice ) /usr/local/bin/trafficcontrol-inetgw.shDevice Up Down ;; esac
unter »/etc/ppp/ip-up.d/trafficcontrol« abzulegen. Nun kann er auch seine Firewall um die Regeln aus IPtables-ingress ergänzen. Diese müssen vor den üblichen Regeln für das Connection Tracking stehen, damit IPtables-ingress alle Pakete einer Verbindung auswerten kann. Dazu ergänzt der Admin »source /usr/local/bin/iptables-ingress« in seinem Firewallskript. Diese Regeln werden erst nach der Messung aktiv, da sie Downloads ab dem 10. MByte um zirka zwei Prozent ausbremsen. Dies hätte die maximale Bandbreite verfälscht.
Kurze Latenzen bei beidseitiger Last
Beim Traffic Shaping auf einem Linux-Gateway ist es kein in Stein gemeißeltes Gesetz, dass bei gleichzeitig ausgelastetem Up- und Downstream die Antwortzeiten in den Keller gehen. Denn neue Features des Linux-Kernels und des IProute-Pakets erlauben die Rohdatenbandbreite dynamisch zu berechnen.
Auch beim oft vernachlässigten Ingress-Policing gelingt es, zwischen Verbindungstypen zu differenzieren. Da der Kernel auf diese Weise keine ACK-Pakete von Uploads mehr zu verwerfen braucht, beeinflussen sich die beiden Übertragungsrichtungen weniger. Lange Downloads lassen sich um wenige Prozent abbremsen, was anderen Verbindungen genug Spielraum eröffnet.
Das hier vorgestellte Trafficcontrol-inetgw macht sich diese Mechanismen erfolgreich zu eigen. Wie Wondershaper benutzt es ein klassenbasiertes Queueing, jedoch keine CBQ-QDisc, sondern HTB-QDisc, die einfacher zu verstehen ist. (jk)
|
Infos |
|---|
|
[1] Schwerpunkt über Traffic Shaping, Linux-Magazin 02/05 [2] Wondershaper: [http://lartc.org/wondershaper/] [3] CBQ-QDisc: [http://lartc.org/howto/lartc.qdisc.classful.html#AEN939] [4] Begriffsbestimmung: [http://lartc.org/howto/lartc.qdisc.terminology.html] [5] Ingress-QDisc: [http://lartc.org/howto/lartc.adv-qdisc.ingress.html] [6] Trafficcontrol-Skripte: [ftp://www.linux-magazin.de/pub/listings/magazin/2010/12/TC] [7] “Classifying packets with filters”: [http://lartc.org/howto/lartc.qdisc.filters.html] [8] “Final ADSL-optimizer patch series”: [http://kerneltrap.org/mailarchive/linux-netdev/2008/4/9/1386524] [9] “Optimization of TCP/IP Traffic Across ADSL”: [http://www.adsl-optimizer.dk] [10] HTB: [http://luxik.cdi.cz/~devik/qos/htb/] [11] SFQ-Manpage: [http://lartc.org/manpages/tc-sfq.html] [12] U32-Classifier: [http://b42.cz/notes/u32_classifier/] und [http://lartc.org/lartc.html#LARTC.ADV-FILTER.U32] |
|
Der Autor |
|---|
|
Martin Stern ist selbstständiger Netzwerk-Administrator. Zwei seiner Schwerpunkte sind Open-VPN-Systeme zur Filialvernetzung mit hochverfügbaren Knoten und Nagios-Monitoringsysteme. Gerne arbeitet er aber auch mit anderen Servern, Routern und Firewalls unter Debian GNU/Linux. |





