
Sergey Pterman, 123rf.com
Gilt es, große Dateisysteme zu verwalten und Speicherplatz verfügbar zu halten, erweist sich die Robinhood Policy Engine als Retter des Admins.
Jedem Administrator, der mehr als eine Handvoll Anwender und ein paar Terabyte Speicherplatz verwaltet, dürften diese Fragen bekannt vorkommen: Wohin ist eigentlich der freie Speicher verschwunden? Welche Anwender belegen den meisten Speicherplatz? Wo liegen lange nicht mehr angefasste Dateien, die ausgelagert werden könnten? Wie viele ISO-Images schlummern eigentlich auf unseren File-Servern?
Wer versucht, diese Fragestellungen mit den bewährten Hausmitteln “du” und “find” zu erschlagen, sieht sich schnell mit einem großen Skalierungsproblem konfrontiert. Der zur Verfügung stehende Speicherplatz steigt kontinuierlich, die durchschnittlichen Dateigrößen wachsen hingegen deutlich zurückhaltender. Dies hat zur Konsequenz, dass pro Dateisystem deutlich mehr Dateien abgelegt sind als früher, und die klassischen Tools sich in Frustbringer verwandeln.
Die Laufzeit eines einzigen Find-Aufrufs über den kompletten Verzeichnisbaum eines Dateisystems mit wenigen TByte kann sich schnell im Stundenbereich bewegen und setzt das System zusätzlich noch unter I/O-Last. Werden mehrere Suchen auf einmal abgesetzt, ist die Schmerzgrenze schnell erreicht, und man sehnt sich nach einer effizienteren Lösung.
Retter der Administratoren
Hier schickt sich die von der französischen Atomenergiebehörde CEA unter einer LGPL-kompatiblen Lizenz veröffentlichte Software Robinhood an, zum Retter der leidgeplagten Administratoren zu werden.
Bei der “Robinhood Policy Engine”, so der vollständige Name der Lösung, handelt es sich um ein vielseitig einsetzbares Werkzeug, das sich zur Verwaltung von beliebigen Posix-kompatiblen Dateisystemen einsetzen lässt.
Das Konzept hinter Robinhood ist so einfach wie genial: Die Metadaten werden in regelmäßigen Intervallen durch Scan-Läufe ermittelt und in einer MySQL-Datenbank abgelegt. Sämtliche Abfragen, die der Administrator sonst auf Dateisystemebene durchführen würde, richtet er danach unter Verwendung von SQL an eine Datenbank, die deutlich schneller eine Antwort liefert. Außerdem lässt sich die Ausgabe direkt unter Verwendung der SQL-Syntax aufbereiten – gerade die Anweisungen “order by” und “group by” tun hier gute Dienste, die Ergebnisse zu sortieren oder zu gruppieren.
Zwar ist die Laufzeit des Robinhood-Scans, der die Datenbank befüllt, auch zeitaufwändig, doch arbeitet der Scan multithreaded und somit deutlich flotter als ein schnöder Find-Lauf. Da nach dem Abschluss des Scans die Einträge in der Datenbank vorliegen, sind die Abfragen im Vergleich zu Find rasend schnell. Sie geschehen interaktiv und ohne Erzeugung weiterer I/O-Last auf dem zu untersuchenden Dateisystem – selbst bei mehreren Millionen Dateien.
Es ist allerdings zu beachten, dass die Informationen in der Datenbank nicht unbedingt den aktuellen Stand des Dateisystems widerspiegeln: In der Zeit zwischen zwei Scans können Dateien modifiziert worden sein. Allerdings liefert ein mehrere Stunden laufender Find-Prozess bei großen Dateisystemen auch keine aktuelleren oder konsistenteren Ergebnisse.
Für Planungs- und Abrechnungzwecke, etwa das Erstellen einer Aufschlüsselung, welcher Anwender wieviel Speicherplatz innerhalb eines Dateisystems belegt, ist ein solches Werkzeug ideal. So lässt sich ein performanter Ersatz für “du -s” zum Ermitteln des Platzbedarfes einzelner Teilbäume eines Dateisystems schnell realisieren.
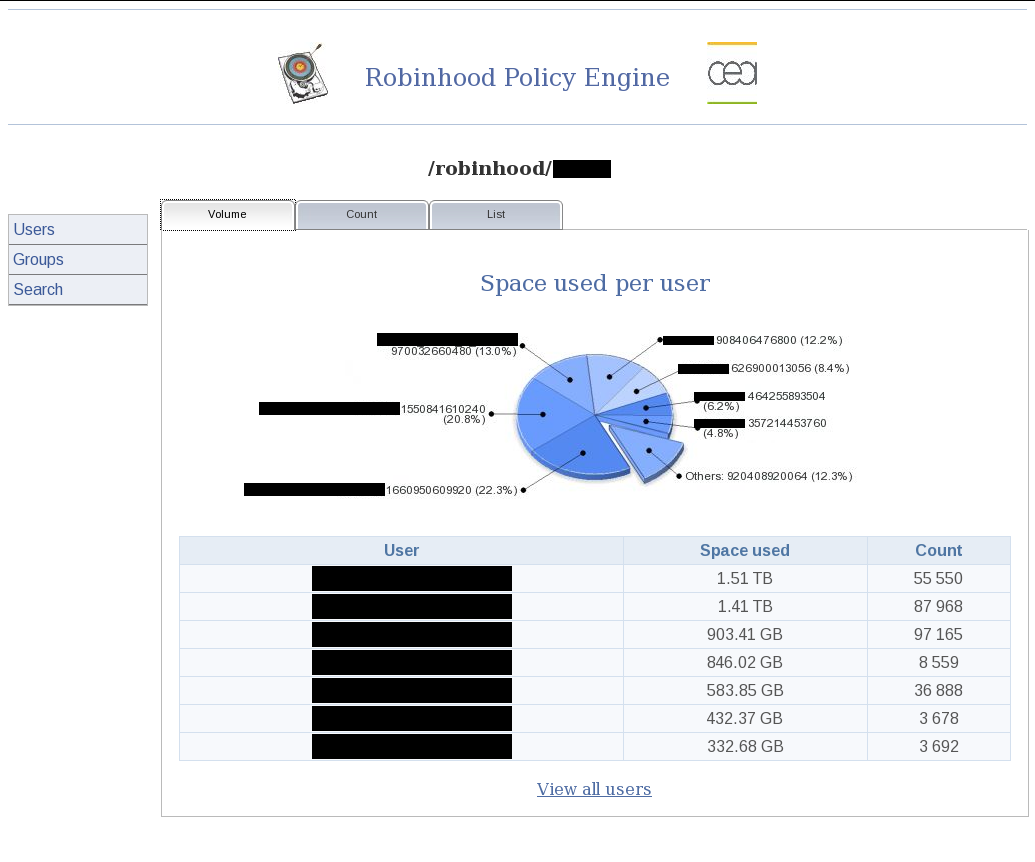
Robinhood bietet auch ein Webfrontend: Hier wird der belegte Speicherplatz auf Anwender-Basis aufgeschlüsselt.
Administratoren, deren SQL-Kenntnisse ein wenig eingerostet sind, bietet das mitgelieferte “rbh-report”-Kommando eine Reihe von vorgefertigten, häufig benötigten Abfragen. So lassen sich exemplarisch mit “rbh-report –top-size” die größten Dateien anzeigen. In der kommenden Version 2.4 wollen die Entwickler auch “du”- und “find”-Klone veröffentlichen, die im Hintergrund die Robinhood-Datenbank abfragen sollen.
Robinhood im HPC
Seinen Ursprung hat Robinhood im High Performance Computing (HPC). In den Bereichen, die der Artikel über leistungsfähige parallele Dateisysteme vorstellt, wo der verfügbare Speicherplatz oft in Petabyte statt Terabyte gemessen wird, sind derartige Werkzeuge besonders wichtig.
Dort können aus einigen Stunden Laufzeit bei Find schnell einige Tage werden. Außerdem kommen regelmäßig automatisierte Aufräumarbeiten zum Einsatz. So sollten von Berechnungsjobs hinterlassene temporäre Scratch-Dateien aufgeräumt werden und länger nicht mehr angefasste Dateien auf günstigeren Speicher ausgelagert oder zumindest komprimiert werden. Robinhoods initiale Rolle war die eines Werkzeugs zum Bereinigen temporärer Pfade nach vom Administrator definierten Regeln. Auch wenn dies an sich schon sehr nützlich ist, bietet Robinhood noch weitere Funktionen, die zu einer deutlichen Komfortsteigerung bei der Administration führen.
Robinhood kann beispielsweise per E-Mail die Verantwortlichen informieren, wenn sich bestimmte Dateitypen nicht an Konventionen halten und am falschen Speicherort liegen. Es könnten zum Beispiel umfangreiche temporäre Daten in einem Pfad abgelegt worden sein, der zur Ergebnis-Sicherung dient und langfristig im Backup landet. Solchen Versehen möchte man entgegenwirken.
Die folgende Konfigurationsdatei “/etc/robinhood.d/tmpfs/myfs.conf” verschickt eine E-Mail, falls sie eine Datei größer als 1 TByte außerhalb des Verzeichnisses “/fs/big_files” findet (aus der Robinhood-Quick-Tour):
Alert large_file_in_bad_place {
type == file
and size > 1TB
and tree != "/fs/big_files"
}
Auch ein Ansatz für den berüchtigten “Bastard Operator from Hell” ist möglich. Er rüstet sozusagen fehlende Quotas auf Verzeichnisebene nach. Statt einer Benachrichtigung, dass eine Anwendergruppe mehr belegt, als sie sollte, werden einfach so lange alte Dateien der Gruppe gelöscht oder archiviert, bis sie wieder unter dem Schwellwert ist. Hierzu geben der Admin Guide und das Configuration Tutorial von Robinhood weiterführende Konfigurationshinweise.
Lustre und Robinhood im Duett
In einer Umgebung, in der Robinhood in Kombination mit Lustre [8] zum Einsatz kommt, kann es weitere Trümpfe ausspielen. Ab Lustre 2.0, das allerdings noch eher wenig verbreitet ist, bietet Robinhood die Möglichkeit, an den Lustre-Changelog-Mechanismus anzudocken und somit regelmäßige Scans einzusparen, da es so unmittelbar mitbekommt, welche Dateien sich geändert haben. Hiervon profitiert insbesondere das Backup, da es auf Basis von Informationen in der Robinhood-Datenbank gezielt nur die Dateien sichern muss, bei denen es zu Änderungen gekommen ist.
Bedingt durch diese mächtige Funktion stehen dem Duo nun einige Szenarien offen, für die man zuvor zwingend ein GPFS-Setup erwartet hätte. Stichworte hierzu sind Informationslebenszyklus (IML) und hierarchisches Speichermangement (HSM), bei dem nicht benötigte Dateien nach und nach transparent von den schnellen und teureren Speichersystemen auf langsamere Speichersysteme ausgelagert werden.
Entsprechende Komponenten, namentlich “robinhood-hsm” und “robinhood-backup”, sind momentan in mehreren größeren Installationen im Testbetrieb [10], so dass hier in Zukunft mit einer brauchbaren Lösung zu rechnen ist.
Fazit
Robinhood zeigt, wie einfach Lösungen für große Probleme manchmal sein können. Indem es Dateisystem-Metadaten in einer Datenbank ablegt, kann es typische Fragestellungen deutlich schneller beantworten als dies mit reinen Linux-Bordmitteln möglich wäre und sorgt so an mehreren Fronten für Entlastung.
Es bietet einerseits die Möglichkeit, Dateisysteme automatisch auf Basis von Policies zu bereinigen, andererseits schont es die Nerven des Administrators, da dieser nicht stundenlang auf das Resultat seiner Abfragen warten muss. Die Option, in neueren Versionen auf den Lustre-Changelog-Mechanismus zuzugreifen, ermöglicht den Verzicht auf regelmäßige Scan-Läufe und bietet quasi eine Echtzeit-Abfragemöglichkeit per Datenbank. Das bedeutet, dass die Ergebnisse der Datenbank genauso aktuell sind wie das, was Find liefert – nur eben um ein Vielfaches schneller.
Aber auch Administratoren, die bislang kein Lustre im Einsatz haben, sondern nur klassische Dateisysteme verwalten, können je nach Dateisystemgröße deutlich vom Einsatz von Robinhood profitieren. (mhu)
|
Der Autor |
|
|---|---|
|
|
Holger Gantikow hat an der Hochschule Furtwangen Informatik studiert und ist seit 2009 bei der Science + Computing AG in Tübingen als System Engineer tätig. Dort beschäftigt er sich mit der Komplexität heterogener Systeme im CAE-Berechnungsumfeld. |



