
© Evgeniy Pavlenko, 123rf
In der Wikipedia stehen viele Fakten über Städte und Philosophen. Wer aber wissen will, welche Philosophen in Edinburgh seit 1700 zur Welt kamen, muss lange recherchieren. Da hilft nur Geduld – oder eine semantische Erweiterung für das Mediawiki.
Wikis sind hervorragende Werkzeuge, um mit wenig Aufwand Informationen zu erfassen und zu vernetzen. Aber wenn es um die Verarbeitung von strukturierten Daten geht, stoßen sie schnell an Grenzen. Wer mit Mediawiki-Software [1] beispielsweise Adressen- oder Termindatensätze sammeln will, kommt mit der Grundversion nicht allzu weit.
Attribute schaffen Struktur
Um strukturierte Daten erfassen zu können, entwickeln seit 2005 Markus Krötzsch, Denny Vrandecic, Max Völkel und etwa 30 weitere Entwickler mit Unterstützung des AIFB-Instituts der Universität Karlsruhe die Erweiterung Semantic Mediawiki, kurz SMW [2]. Ganz allgemein geht es darum, Wiki-Seiten mit Attributen (»ist Geburtsort«, »ist Homepage«) und deren Werten (»Köln«, »http://linux-magazin.de«) zu bereichern. Noch eins draufgesetzt haben Yaron Koren und andere, indem sie eine weitere Extension bauten, mit der sich die strukturierten Daten über Formulare pflegen lassen.
Einer strukturierten Datenerfassung in der Wikipedia am nächsten kommen derzeit die Infoboxen (Abbildung 1). Sie geben beispielsweise für Städte in einer immer gleich aufgebauten Übersicht Eckdaten wie Einwohnerzahl und Landkreis an. Diese Kästen beruhen auf Vorlagen (Templates), also Texten mit Platzhaltern, die der Bearbeiter im Artikel mit Werten bestückt. Da Mediawiki und die semantischen Erweiterungen gut eingedeutscht sind, lassen sich häufig sowohl englische als auch deutsche Bezeichnungen verwenden (Tabelle 1).
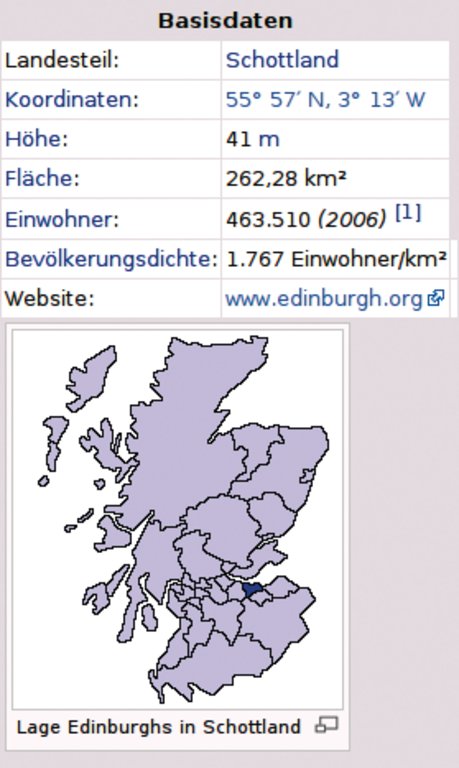
Abbildung 1: In der Wikipedia finden sich strukturierte Daten in solchen Infoboxen.
|
Tabelle 1: |
|
|---|---|
|
Englisch |
Deutsch |
|
Template |
Vorlage |
|
Property |
Attribut |
|
Has type |
Datentyp |
|
Special:Types |
Spezial:Datentypen |
|
Special:Ask |
Spezial:Semantische_Suche |
|
Concept |
Konzept |
|
Has default form |
Hat Standardformular |
Als Beispiel, das sich später zu einer richtigen Datenstruktur entwickeln soll, dient ein Personendatensatz, wie er in Listing 1 definiert ist. Um ihn dem Wiki bekannt zu machen, muss man »http://example.org/index.php/Vorlage:Person« ansteuern und mit dem Inhalt von Listing 1 füllen. Die Vorlage mit Werten zu füttern ist dann trivial, wie Listing 2 zeigt.
Auf diese Weise ist so etwas Ähnliches wie ein Personendatensatz mit vier Feldern entstanden. Der lässt sich hübsch anzeigen, aber viel mehr auch nicht. Es fehlen Datentypen sowie Abfragen, damit sich Daten ordentlich erfassen und auswerten lassen.
|
Listing 1: Einfache |
|---|
01 {|
02 ! Vorname
03 | {{{vorname}}}
04 |-
05 ! Nachname
06 | {{{nachname}}}
07 |-
08 ! Geburtsdatum
09 | {{{geburtsdatum}}}
10 |-
11 ! Geburtsstadt
12 | {{{geburtsstadt}}}
13 |}
|
|
Listing 2: Inhalte für das |
|---|
01 {{Person
02 |vorname=Charles
03 |nachname=Babbage
04 |geburtsdatum=26.12.1791
05 |geburtsstadt=Walworth}}
06
07 {{Person
08 |vorname=David
09 |nachname=Hume
10 |geburtsdatum=7.5.1711
11 |geburtsstadt=Edinburgh}}
12
13 {{Person
14 |vorname=Pablo
15 |nachname=Picasso
16 |geburtsdatum=25.10.1881
17 |geburtsstadt=Malaga}}
|
Datenfelder und Datentypen
Diese Lücke füllt Semantic Mediawiki (SMW). Die Erweiterung ist Voraussetzung, um Datenstrukturen aufbauen zu können und mit einer Bedeutung zu versehen. Dazu gilt es zuerst, die zukünftigen Datenfelder mit Datentypen zu verknüpfen. Oder in der Sprache des SMW: Attribute sind zu definieren.
Angenommen in einem Wiki-Eintrag steht der Satz »David Hume wurde in Edinburgh geboren«, Edinburgh soll also das Attribut »attGeburtsstadt« erhalten. Dazu wandelt der Wiki-Benutzer das Wort »Edinburgh« zunächst in einen Link um und versieht diesen mit dem Attribut als Präfix:
David Hume wurde in [[attGeburtsstadt::Edinburgh]] geboren.
Unter »http://example.org/index.php/Attribut:attGeburtsstadt« finden sich jetzt diese und alle anderen Seiten aufgelistet, die das Attribut enthalten sowie die Werte des Attributs. Aus einer großen Menge von Personen lassen sich nun alle herausfiltern, die in Edinburgh geboren sind. Das ist der Grundstein für Abfragen im Semantic Mediawiki.
Da für »attGeburtsstadt« noch niemand einen Datentyp vergeben hat, bleibt es erst einmal beim Standarddatentyp »Page«. Die Schreibweise »attGeburtsstadt« hilft Attribute von Feldern und Platzhaltern zu unterscheiden.
Das Beispiel in Listing 2 besteht aus nur drei via Vorlage erfassten Datensätzen, in einem realen Wiki könnten das leicht Hunderte oder Tausende sein. Da wäre es mehr als mühsam, in jedem Datensatz jedes Datenfeld mit den entsprechenden Attributen zu garnieren. Mit Vorlagen geht das wesentlich leichter. Die einfache Vorlage ergänzt der Wiki-Admin um Attribute, und schon befindet sich ein Stück auswertbare Semantik im Wiki.
Und tatsächlich liefert die Wiki-Adresse »http://example.org/index.php/Attribut:attGeburtsstadt« jetzt vier Seiten. Zu diesem Zeitpunkt sind alle Attribute noch vom Typ »Page«. Für »attGeburtsdatum« ist das nicht so günstig. Es sollte vom Typ »Datum« sein, um später beispielsweise Übersichtsseiten der Form »Wer wurde alles im 18. Jahrhundert geboren?« mit einer einfachen Abfrage erstellen zu können.
Dazu ist »http://example.org/index.php/Attribut:attGeburtsdatum« aufzurufen. Auch wenn diese Spezialseite genau wie beim »attGeburtsstadt« eine Seitenliste anzeigt, existiert sie in Wirklichkeit noch nicht. Mit einem Klick auf »Erstellen« kann der Wiki-Verwalter das jetzt nachholen und dort den Text »[[Datentyp::Datum]] Dieses Attribut bezieht sich auf den Geburtstag von Personen« eingeben. Der erläuternde Text ist im Gegensatz zur Definition des Datentyps zwar nicht notwendig, aber auf alle Fälle hilfreich. Eine Übersicht über die verfügbaren Datentypen findet sich auf der Seite »http://example.org/index.php/Spezial:Datentypen«.
Die Entscheidung für einen bestimmten Datentyp ist meist leicht zu treffen. Lediglich die Wahl zwischen »String« oder »Page« ist nicht ganz so trivial. Im vorliegenden Beispiel taucht diese Frage beim Geburtsort auf. Falls die Absicht besteht, später den Geburtsorten noch weitere Daten hinzuzufügen, ist »Page« die bessere Wahl. Bleibt es mit Sicherheit allein beim Namen der Stadt, so ist »String« die richtige Entscheidung.
An dieser Stelle noch ein Hinweis aus der Praxis: Es ist nicht ratsam, mehrere Datensätze auf einer Seite unterzubringen. Denn es wird dadurch unklar, wovon die einzelne Seite handelt – also beispielsweise von welcher Person. Und diese Unklarheit zieht sich dann auch durch alle Abfragen.
Semantische Suche
Durch die Anpassung der Vorlagen stehen nun alle Daten für die semantische Suche zur Verfügung. Das Interface für die Suche findet sich unter »http://example.org/index.php/Spezial:Semantische_Suche« – eine Wiki-typisch einfache Seite mit einer Eingabebox für die Suche, einer für (optionale) zusätzliche Parameter und dem Knopf, der die Suche startet. Eine Beispiel-Abfrage soll alle Personen finden, die am 26.12.1791 geboren sind. Dazu muss man das Wiki nach dem Attribut »attGeburtsdatum« durchsuchen. Die Abfrage »[[attGeburtsdatum:: 26.12.1791]]« im Suche-Feld liefert das Gewünschte, nämlich die Seite von Charles Babbage. Die Datumsnotation ist übrigens recht anpassungsfähig: Die Form »1791-12-26« funktioniert ebenfalls.
Für eine Suche nach allen Datensätzen, die über das Attribut »attGeburtsdatum::« verfügen, kommt eine Wildcard zum Einsatz. Der Platzhalter ist bei der semantischen Suche nicht das Sternchen, sondern das Pluszeichen: »[[attGeburtsdatum:: +]]«. Etwas komplexer ist folgende Abfrage:
[[attGeburtsdatum:: > 1700-01-01]] [[attGeburtsdatum:: < 1800-01-01]]
Sie findet alle Seiten, auf denen das Geburtsdatum in einem bestimmten Zeitintervall liegt.
Tests auf größer oder kleiner sind also explizit anzugeben, ohne einen Operator prüft die Abfrage auf Gleichheit. Daneben gibt es nur noch den Test auf Ungleichheit, der mit dem Rufzeichen kodiert wird, und einen Like-Operator, als Tilde geschrieben. Letzterer funktioniert nur bei Strings und ist aus Performancegründen normalerweise ausgeschaltet.
Das Ergebnis dieser Suche zeigt, dass die beiden Bedingungen implizit mit einem »AND« verknüpft wurden. Aber auch eine Disjunktion ist möglich, entweder mit dem Operator »OR« oder mit »||«. Die Abfrage »[[attVorname:: Pablo || David]]« oder alternativ »[[attVorname:: Pablo]] || [[attVorname:: David]]« findet also alle Pablos und Davids.
Häufig wünscht sich der Wiki-Benutzer nicht nur eine Liste der Seiten, sondern eine Liste mit anderen Attributen, die auf der jeweiligen Seite vorkommen. In unserem Fall also Vor- und Nachname. Wer das will, trägt Folgendes ins Feld »Zusätzlichen Ausgaben« ein:
?AttVorname ?AttNachname ?AttGeburtsdatum
Abbildung 2 zeigt die gesamte Abfrage ergänzt um eine Sortierung nach dem Geburtstag und dem Ergebnis.
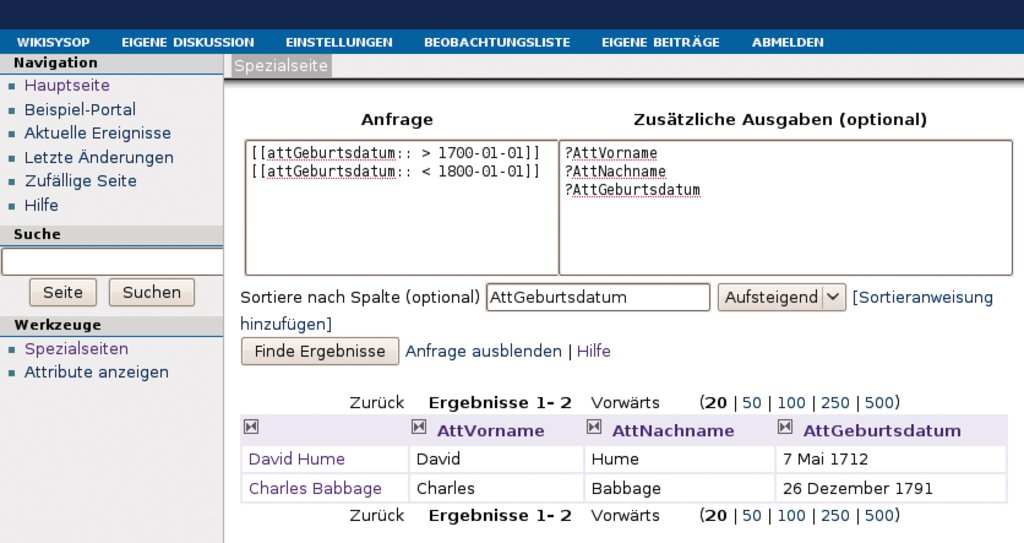
Abbildung 2: Eine semantische Suche mit Ergebnissen, Bedingungen und anzuzeigenden Attributen.
|
Listing 3: Semantische |
|---|
01 {|
02 ! Vorname
03 | [[attVorname::{{{vorname}}}]]
04 |-
05 ! Nachname
06 | [[attNachname::{{{nachname}}}]]
07 |-
08 ! Geburtsdatum
09 | [[attGeburtsdatum::{{{geburtsdatum}}}]]
10 |-
11 ! Geburtsstadt
12 | [[attGeburtsstadt::{{{geburtsstadt}}}]]
13 |}
|
Die gespeicherte Suche
Niemand möchte für Standardabfragen jedes Mal die Boxen neu füllen, das Ergebnis sollte immer auf Klick verfügbar sein. Dafür gibt es die Parserfunktion »#ask«. Das Format ist:
{{#ask: Argument1 | Argument2 | ... }}
Die Argumente sind die Inhalte der beiden Eingabeboxen von eben, garniert mit zusätzlichen Steuerparametern für die Ausgabe, wie Listing 4 zeigt.
|
Listing 4: Komplexere Abfrage |
|---|
01 {{#ask: [[attVorname::David]]
02 | ?attVorname
03 | ?attNachname
04 | sort=attNachname,attVorname
05 }}
|
Ein Blick auf die Hilfeseite des SMW [2] lohnt sich dabei, denn es steht eine ganze Reihe leistungsstarker Funktionen für die Abfrage und die Ergebnisformatierung zur Verfügung. Allerdings lauern auch einige Tücken. So kann es leicht geschehen, dass als Ergebnis der Suche gar nichts erscheint. Das liegt meistens an einem Tippfehler in den Attributnamen. In hartnäckigen Fällen hilft es, die Abfrage und die Spalten erst einmal zu reduzieren und dann Stück für Stück wieder zu ergänzen.
Etwas überraschend reagiert eine Abfrage auch, wenn sie nach Attributen sortieren soll, die nicht in der Ergebnismenge vorhanden sind. Befände sich in der Philosophenliste auch noch Aristoteles, so wäre zwar das Feld »attNachname« gefüllt, aber das Feld »attVorname« wäre wohl gar nicht vorhanden. Damit verschwände der Philosoph aus jeder Liste, in der nach »attVorname« sortiert wird. Verzichtet man auf diese Sortierung und belässt es dabei, den Vornamen nur in den Ergebnisspalten aufzuführen, so taucht er wieder auf.
Ein letztes Problem hat mit dem Caching-Mechanismus von Mediawiki zu tun: Gibt es neue Daten, so finden sie sich auf einer Abfrageseite erst dann, wenn diese frisch abgespeichert oder der Link »aktualisieren« angeklickt wird. Die Alternative dazu ist, mit einem beherzten »$wgEnableParserCache = false;« in der Datei »LocalSettings.php« den Parser-Cache gleich ganz auszuschalten. Das empfiehlt sich aber nur für wenig frequentierte Wikis.
Dynamische Kategorien
Die Wikipedia macht intensiven Gebrauch von Kategorien. Auf diese Weise erzeugt die Enzyklopädie die Übersichtsseiten mit Künstlern und Philosophen. Das lässt sich mit dem SMW wesentlich eleganter über Attribute und Abfragen erledigen. Dabei zeigt sich noch ein weiterer Vorteil dieser Methode. Kategorien tendieren dazu, immer feingliedriger, damit aber auch unhandlicher zu werden. So gibt es zur Wikipedia-Kategorie »Künstler« auch noch die Unterkategorien »Künstler des 20. Jahrhunderts« und »Deutsche Künstler«, also im Grunde beliebige Zusammenstellungen von Attributen, die als Etikett eine Kategorie aufgeklebt bekommen.
Genau das bietet das SMW mit seinen dynamischen Kategorien an. Statt eine Abfrage mit »#ask« durchzuführen, kommen die Parser-Funktion »#concept« und der Namespace »Konzept:« zum Einsatz, etwa auf einer Seite »http://example.org/index.php/Konzept:GeborenInEdinburgh«:
{{#concept: [[attGeburtsstadt::Edinburgh]]
| Berühmte Einwohner Edinburghs
}}
Bei Bedarf lässt sich diese Kategorie weiter auf »Berühmte Einwohner Edinburghs des 18. Jahrhunderts« spezialisieren, ohne dass an den Daten etwas zu ändern wäre. Lediglich die Abfrage bräuchte etwas Tuning. Um eine neue Kategorie zu erstellen, muss der Admin also nicht mehr alle in Frage kommenden Seiten ändern, sondern braucht nur noch ein neues Konzept zu erstellen.
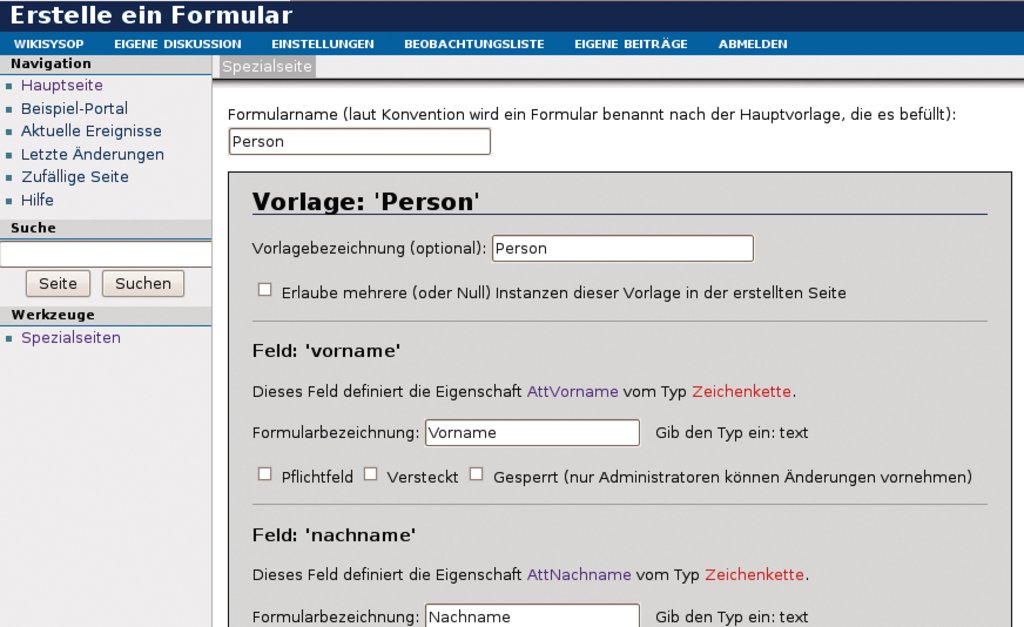
Abbildung 3: Das Formular für Personen entsteht durch die Definition von Datenfeldern und -typen.
Semantische Formulare
Dass der Admin eines Wiki wissen sollte, was es mit Kategorien, Vorlagen, Abfragen und so weiter auf sich hat, ist selbstverständlich. Aber kann man das auch von einem normalen Benutzer verlangen? Ideal wäre es, wenn der Benutzer an Stelle von Vorlagen – die ja immer auch Hintergrundwissen benötigen – gleich Eingabeformulare präsentiert bekäme. Für diesen Zweck gibt es die Extension zur Extension: Semantic Forms [3]. Vorlagen und Attribute lassen sich dabei zunächst analog zur Version ohne Semantic Forms produzieren – aber unterstützt von einem Softwarewerkzeug.
Der Ablauf folgt immer dem gleichen Schema: Zuerst sind Attribute zu definieren. Dafür ist die Seite »http://example.org/index.php/Spezial:CreateProperty« gedacht. Der Admin gibt einfach den Namen des Attributs an, wählt aus den verfügbaren Datentypen aus und drückt »OK« – schon hat er das Wiki um ein weiteres Attribut bereichert.
Für Datumswerte gibt es in der aktuellen Version 1.5.4 der Semantic Forms einen Showstopper: Um ein Datum für die Eingabe aufzubereiten, wird es in einen Unix-Timestamp mit Vorzeichen umgewandelt. Dadurch lassen sich nur Zeitangaben zwischen dem 13.12.1901 20:45:54 und dem 19.1.2038 03:14:07 verarbeiten. Das Semantic Mediawiki selbst kennt dieses Problem nicht.
Sind alle Attribute produziert, geht es auf »http://example.org/index.php/Spezial:CreateTemplate« weiter mit der Erzeugung der Vorlagen, die den Daten Struktur verleihen. Auf dieser Seite kann der Wiki-Verwalter optional die Kategorie der Vorlage bestimmen. Das sollte er auch tun, denn die Kategorie dient dazu, die Vorlage und das zugehörige Standardformular aneinander zu binden. Dadurch erscheint später bei der Bearbeitung einer Seite der zusätzliche Reiter »Mit Formular bearbeiten«. Nach der Ersterfassung ist so auch die Nachbearbeitung von Daten via Formular möglich.
Aber diese Verwendung von Kategorien in einem semantischen Wiki unterscheidet sich offensichtlich erheblich von der in einem normalen Wiki: Dort sind über die Kategorien so etwas wie Tags realisiert, aber dafür besitzt ein semantisches Wiki ja seine Abfragen und dynamischen Kategorien. Ein Benutzer hat mit Kategorien also nichts mehr zu tun, er bewegt sich nur noch in der Welt der Attributwerte und Formulare.
Falls wie im Beispiel die Vorlage bereits besteht, muss der Admin noch etwas nachbessern: Zunächst ist die Kategorie zu ergänzen: »[[Kategorie:Person]]«. Danach verbindet er auf der Spezialseite »http://example.org/index.php/Spezial:CreateCategory« Kategorie und Formular miteinander. Im Quelltext der Kategorie steht jetzt »Diese Kategorie nutzt das Formular [[Hat Standardformular::Person]]«.
Nach diesen Vorarbeiten geht es im nächsten Schritt zum Erzeugen der Formulare. Das geschieht mit Hilfe der Spezialseite »http://example.org/index.php/Spezial:CreateForm«. Hier reicht es, das Formular zu benennen und die Vorlage auszuwählen, um zu einer Seite zu gelangen, auf der man das zukünftige Formular noch um einige Feinheiten wie etwa Pflichtfelder ergänzen kann.
Die drei Seiten zum Anlegen von Attributen, Vorlagen und Formularen lassen sich allerdings nur zum Erzeugen benutzen. Ein nachträgliches Bearbeiten ist lediglich durch einen Eingriff in den erzeugten Code möglich. Das ist aber unkompliziert und erlaubt es zudem, Formulare etwas aufzuhübschen.
Strukturierte Eingabe
Sobald das Formular abgespeichert ist, erscheint die Eingabeseite für dieses Formular, im vorliegenden Beispiel also »http://example.org/index.php/Formular:Person«. Wie in einem Wiki üblich, ist zunächst der Name der Seite anzugeben, die neu erzeugt werden soll. Erst danach lassen sich die Daten eingeben. Abbildung 4 zeigt, wie das aussieht. Erwischt man dabei den Namen einer bereits existierenden Seite, so gibt es zwei Möglichkeiten: Entweder benutzt die Zielseite bereits Daten im richtigen Format, dann werden sie zum Editieren angeboten. Oder, falls dies nicht der Fall ist, das Bearbeitungsformular erscheint mit einem Warnhinweis. Der ursprüngliche Seiteninhalt ist dann in das Feld »Freitext« verbannt.
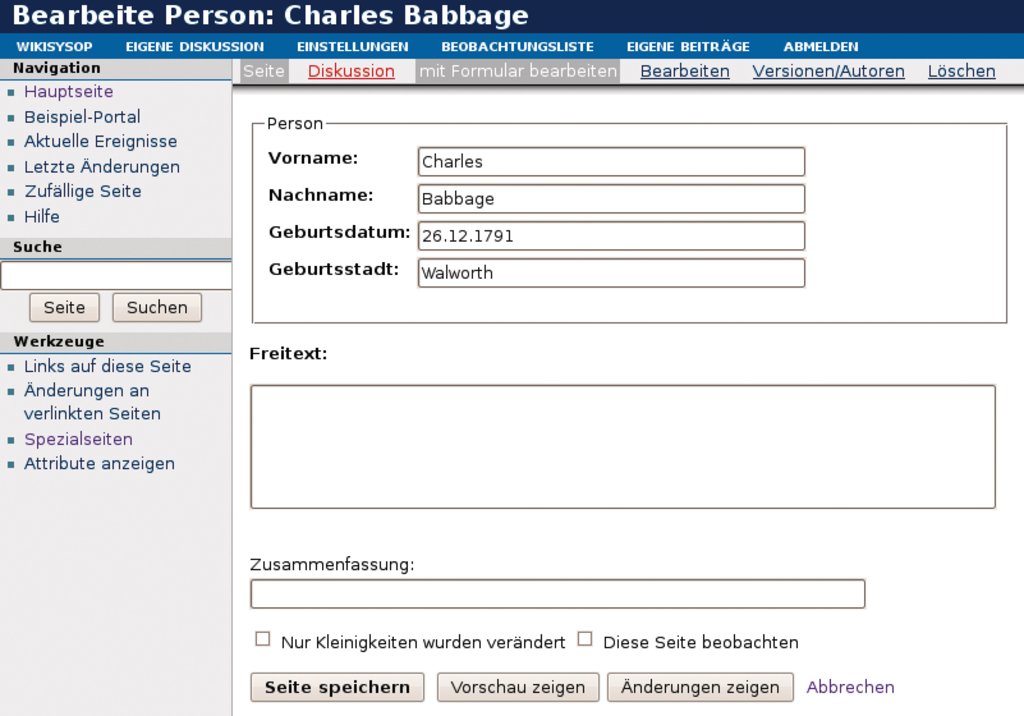
Abbildung 4: Charles Babbage im neu definierten semantischen Formular für Personen.
Für viele Anwendungsfälle sind zwei Schritte genau einer zu viel. Gerade wenn sich die Daten später hauptsächlich über Abfragen oder dynamische Kategorien präsentieren sollen, ist eine automatische Erzeugung der Seitentitel angenehmer. Um dies einzurichten, muss der Admin allerdings in den Code des Formulars eingreifen und festlegen, wie aus den eingegebenen Daten automatisch der Seitentitel entsteht. Zuständig ist die »info«-Zeile, Listing 5 verwendet dafür das Feld »nachname«.
|
Listing 5: Formular mit |
|---|
01 {{{info|page name=<Person[nachname]>-<unique number;start=1>}}}
02 {{{for template|TestPerson}}}
03 {| class="formtable"
04 ! Vorname:
05 | {{{field|vorname}}}
06 |-
07 ! Nachname:
08 | {{{field|nachname|mandatory}}}
09 |-
10 ! Geburtsdatum:
11 | {{{field|geburtsdatum|input type=text}}}
12 |-
13 ! Geburtsort:
14 | {{{field|geburtsort}}}
15 |}
16 {{{end template}}}
|
Titel vom Fließband
Da viele Menschen den gleichen Nachnamen tragen, wird der Seitentitel mit »<unique number;start=1>« um eine für diesen Namespace hochgezählte Zahl ergänzt. Das garantiert, dass in jedem Fall einzigartige Titel entstehen. Wenn also jemand in die Beispielmaske zuerst Immanuel Kant und dann Erwin Kant eingibt, bekommt der erste als Titel »Kant-1« und der zweite »Kant-2«. Ohne die Angabe »start=1« hieße die erste Seite »Kant-« und die zweite »Kant-2«, was selbstverständlich unschön wäre.
In Listing 5 ist außerdem noch ein Workaround für das oben erwähnte Datumsproblem untergebracht. »input type=text« erzeugt ein Text-Eingabefeld statt eines Datum-Eingabefelds, das ansonsten automatisch aufgrund der Attributdefinition erscheinen würde.
Als letzter Baustein fehlt noch der Link, der direkt auf die leere Eingabemaske verweist: »http://example.org/index.php/Spezial:AddData/Person«.
Ausblick
Aber was ist jetzt eigentlich semantisch an diesen Erweiterungen? Sie bohren das Mediawiki so auf, dass es wie ein Datenbank-Frontend zu nutzen ist, ohne seine Wiki-Eigenschaften zu verlieren. Das ist schon sehr viel und eröffnet eine Menge neuer Möglichkeiten. Aber Semantic Mediawiki zielt eigentlich auf das semantische Web ab, bei dem es darum geht, nicht einfach nur wie Google das Internet als Volltext durchsuchbar zu machen, sondern den Inhalten gleich Sinn mitzugeben. Praktisch passiert das, indem sowohl die Inhalte als auch die Beschreibung der Inhalte strukturiert weitergegeben werden. Statt HTML-Code, der hübsch gerendert das menschliche Auge erfreut, kommt dabei das auf XML basierende RDF (Resource Description Framework) zum Einsatz, das für Maschinen gedacht ist (Abbildung 5).

Abbildung 5: Pablo Picasso, im RDF-Format beschrieben. Auch hier sind die Attribute mit Daten eines bestimmten Typs gefüllt.
Wenn Suchmaschinen mit Bedeutungen umgehen können, kann der Anwender gezielt nach Restaurants in Essen suchen und muss nicht seitenweise Treffer durcharbeiten, bei denen nur von der Tätigkeit Essen und nicht der Stadt Essen die Rede ist. Und das ist nur der Anfang für alle möglichen Mashups, die sich die Daten aus diversen Töpfen ziehen und neu verknüpfen.
Wer sich noch tiefer in die Materie hineinwagen will, der kann sein semantisches Wiki mit weiteren Extensions aufwerten. So liefert Semantic Result Formats [4] Abfrageergebnisse auch als Kalender, Zeitstrahl oder Graph. Eine Komplettlösung bietet Halo [5], auch SMW+ genannt. Es fasst zahlreiche erweiterte Extensions zusammen. Dieses Projekt gibt es auch in einer kommerziellen Variante. Und natürlich sollte man die Ideen des W3C für das semantische Web selbst nicht vergessen [6]. (mhu)
|
Infos |
|---|
|
[1] Mediawiki: [http://www.mediawiki.org] [2] Semantic Mediawiki: [http://www.mediawiki.org/wiki/Extension:Semantic_MediaWiki] [3] Semantic Forms: [http://www.mediawiki.org/wiki/Extension:Semantic_Forms] [4] Semantic Result Formats: [http://semantic-mediawiki.org/wiki/Help:Semantic_Result_Formats] [5] Halo: [http://www.mediawiki.org/wiki/Extension:Halo_Extension] [6] W3C Semantic Web: [http://www.w3.org/2001/sw/] |
|
Der Autor |
|---|
|
Rolf Strathewerd ist Philosoph und verdient seine Brötchen als Teammanager in der Webentwicklung der Telegate Media AG. |






