
michusteiner / photocase.de
Wer den Inhalt seiner Festplatten vor Dieben oder dem kontrollsüchtigen Chef verbergen will, braucht Verschlüsselungssoftware. Linux hat kürzlich auf diesem Gebiet viel dazugelernt: DM-Crypt und Cryptsetup-LUKS sind die neuen Meister im Hüten von Geheimnissen.
Im Hintergrund ein kratzendes Geräusch, dazu eindringlich pulsierende Musik. Ein grüner Laserstrahl aus einem silbernen Rohrstück trifft auf das Glas der Balkontür und nagt leise zischend ein rundes Loch hinein. Schnitt, nächste Szene: Die Filmheldin im schwarzen Catsuite schiebt eine knallgelbe Diskette in das Laufwerk eines PC und versteckt sich unter dem Schreibtisch. Jetzt kann der Zuschauer einen Blick auf den Monitor erhaschen. Dort blitzt ein dicker roter Balken: “Cracking”.
Das ist Verschlüsselung à la Hollywood. Doch die Realität sieht anders aus. Mit starker Kryptographie, wie sie unter Linux beispielsweise DM-Crypt für Festplattenpartitionen einsetzt, müsste die Filmheldin zig Millionen Jahre unter dem Schreibtisch kauern, bevor sich der rote Balken ihrer Cracking-Software in ein grünes “Success” verwandelt.
Dieser Artikel gibt einen Einblick in die Technologie hinter DM-Crypt und seinem neuen Management-Tool LUKS (Linux Unified Key Setup) und zeigt, wie man sie einsetzt. Das Kernelmodul »dm-crypt« verschlüsselt Festplattenpartitionen auf Blockdevice-Ebene. Für die Applikation bleibt der Vorgang transparent, solange der Benutzer den Inhalt freigegeben hat.
DM-Crypt verschlüsselt das so genannte Backing-Device (die echte Festplatte) und gibt den Klartextinhalt über ein virtuelles Blockdevice unter »/dev/mapper« frei. Dieses Device kann der Benutzer wie ein herkömmliches Blockdevice verwenden, um darin ein Filesystem zu erstellen und zu mounten.
Auf dem Weg zu Cryptsetup
DM-Crypt setzt auf einem flexiblen Layer namens Device Mapper auf. Alle Device-Mapper-Module erhalten ihre Konfiguration über DM-Tables – einfache Textdateien, die angeben, wie der Device Mapper Zugriffe auf die Regionen der virtuellen Platte verarbeiten soll. Das Programm »dmsetup« liest diese Textdateien und übergibt ihre Information über »ioctl()«-Aufrufe an den Kernel.
Das DM-Table-Format ist für DM-Crypt unnötig unhandlich. Die Verschlüsselungssoftware erwartet den Key als Hex-Zeichenkette einer fixen Länge. Damit chiffriert das Modul die Daten des Blockdevice. Den Schlüssel in DM-Table-Dateien permanent abzulegen wäre aber ähnlich schlau wie einen Haustürschlüssel außen an die Türklinke zu hängen. Vielmehr ist es nötig, den Key vor jedem Mounten neu zu erstellen.
Da niemand allmorgendlich – vielleicht noch vor dem dritten Schluck Kaffee – bis zu 32 Hex-Ziffern fehlerfrei aus dem Gedächtnis tippen will, unterstützt ihn »cryptsetup« dabei. Dieses Tool leitet aus einem (einfacheren) Passwort einen kryptographischen Key ab und übergibt ihn dem Kernel. Abbildung 1 zeigt die Umgebung, in der Cryptsetup arbeitet.
Passwort und Schlüssel
Zwei wichtige Bereiche lassen sich bei Cryptsetup parametrisieren: Die Schlüsselgenerierung und das Verschlüsselungsverfahren. Ersteres bestimmt, wie Cryptsetup aus dem Passwort des Benutzers einen Schlüssel berechnet. Üblicherweise verwendet es einen Hash-Algorithmus. Das gibt dem Anwender die Freiheit, ein beliebig langes Passwort zu wählen. Der Hash komprimiert die Information immer auf eine bestimmte Anzahl von Bytes. Abbildung 1 zeigt Cryptsetup mit seinen Defaultwerten: Das Hash-Verfahren Ripemd-160 erzeugt einen 256-Bit-Schlüssel.
Beim Verschlüsselungsverfahren sind zwei Parameter zu wählen: Algorithmus und Modus. Cryptsetup übergibt diese Parameter zusammen mit dem abgeleiteten Schlüssel an den Kernel. Dort koordiniert das DM-Crypt-Modul den weiteren Ablauf. Zur Verschlüsselung greift es auf das bewährte Crypto-API zu.
Use the Force, LUKS
Cryptsetup hat jedoch einen Schönheitsfehler. Es trennt die Information, wie eine verschlüsselte Informationsmenge zu verwenden ist, von der verschlüsselten Information selbst. Die Cryptsetup-Parameter stehen in Skripten oder Konfigurationsdateien, die zwangsläufig nicht auf der verschlüsselten Partition liegen können. Wer diese Files verliert oder sich bei einer mobilen Platte nicht an die Einstellungen erinnert, dem bleibt der Zugriff auf seine verschlüsselten Daten dauerhaft verwehrt. Linux Unified Key Setup hebt die Trennung auf.
LUKS ist zunächst ein formaler Standard [3], den das Tool Cryptsetup-LUKS [4] implementiert (Abbildung 2). Bei Letzterem handelt es sich um einen Fork des originalen Cryptsetup. Trotz seines Namens ist LUKS nicht auf Linux beschränkt. Es definiert einen Header für DM-Crypt-Partitionen (Abbildung 3), der alle Informationen für die sichere Schlüsselableitung sowie den Verschlüsselungsalgorithmus und -Modus enthält. Da der Header Teil der verschlüsselten Partition ist, sind die Einstellungen immer an jenem Ort verfügbar, an dem sie gebraucht werden.

Abbildung 1: Cryptsetup (oben) nimmt vom User ein Passwort entgegen und berechnet daraus mit einem Hash-Verfahren einen Schlüssel konstanter Länge, den es an den Kernel weiterreicht (Mitte). Mit diesem Key ver- und entschlüsselt DM-Crypt (unten) den Inhalt der Festplatte (Backing Blockdevice).
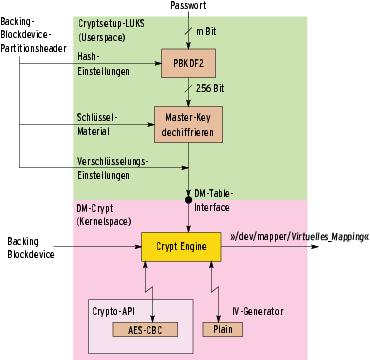
Abbildung 2: Cryptsetup-LUKS speichert alle Parameter der verschlüsselten Partition im Partitionsheader des Backing Blockdevice (links oben). Anders als sein Vorgänger (Abbildung 1) verwendet LUKS für den Festplatteninhalt einen Master-Key, den es mit den Passwort des Benutzers schützt.
Cryptsetup-LUKS und das ursprüngliche Cryptsetup unterscheiden sich zudem in der Technik, mit der sie den Schlüssel aus dem Passwort berechnen (Abbildung 2). Das Passwortmanagement von LUKS verfolgt drei Konzepte: Schlüsselhierarchien, PBKDF2 und anti-forensische Informationsspeicherung.
Neu: Master-Key
Das klassische Cryptsetup übergibt den abgeleiteten Schlüssel direkt an den Kernel. Das hat den Nachteil, dass die Software bei jeder Änderung des Passworts alle Daten neu verschlüsseln muss. Cryptsetup-LUKS hält mit einer zusätzlichen Passwortmanagement-Schicht dagegen: Die Schlüsselhierarchie schiebt eine weitere Krypto-Schicht zwischen den abgeleiteten Schlüssel und den Key, mit dem der Kernel die Partitionsdaten schützt. Der aus dem Passwort erzeugte Schlüssel chiffriert nun einen Master-Key, der erst die Daten in der Partition verschlüsselt (Abbildung 2).
Um das Passwort zu ändern, entschlüsselt Cryptsetup-LUKS den bereits gesetzten Master-Key mit dem alten Passwort, verschlüsselt ihn anschließend mit dem neuen Passwort und überschreibt die alte Master-Key-Kopie mit dem neuen Wert. Da sich der Klartext-Master-Key dabei nicht ändert, bleiben die verschlüsselten Partitionsdaten gültig. Bei 120 GByte spart das einen halben Tag Umschlüsseln, mit der Schlüsselhierarchie reduziert sich eine Passwortänderung auf wenige Sekunden.
Mehrere Passwörter gültig
Den chiffrierten Master-Key speichert LUKS im dem Partitionsheader, der zum verschlüsselten Blockdevice gehört. Es beschränkt sich nicht auf eine einzelne Kopie: Um mehrere Passwörter für eine Partition zuzulassen, ist es möglich, mehrere gleichwertige Kopien des Master-Key abzulegen und jede mit einem anderen String zu verschlüsseln.
Jedes dieser Passwörter gibt den Zugang zum Klartextinhalt der Festplatte frei. Das ist besonders praktisch, um Backup-Passwörter anzulegen oder mehreren Benutzern eigene Zugangsdaten zu geben. LUKS reserviert im Header Platz für bis zu acht Passwörter in so genannten Key-Slots (Abbildung 3).
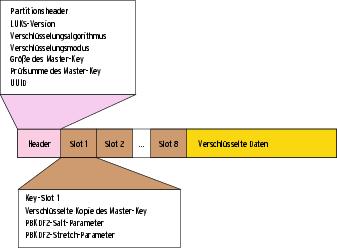
Abbildung 3: LUKS trägt im Header der verschlüsselten Partition alle Parameter ein, die Cryptsetup-LUKS zum Ableiten des Schlüssels aus dem Passwort des Benutzers braucht. In jedem Key-Slot liegt eine verschlüsselte Kopie des Master-Key, mit dem DM-Crypt die Daten schützt.
Wie Cryptsetup braucht auch LUKS einen Hash-Algorithmus, um ein beliebig langes Passwort in eine fixe Anzahl Bytes umzuwandeln. Es verwendet aber das verallgemeinerte Verfahren PBKDF2 (Password-Based Key Derive Function, Version 2). PBKDF2 ist Teil von PKCS#5 (Public Key Cryptography Standard 5) und in RFC 2898 spezifiziert [5]. Es nutzt unter anderem die Verfahren Salting and Stretching, um Wörterbuchangriffe zu vereiteln.
Benutzer haben eine Vorliebe für kurze, leicht merkbare Passwörter (siehe Kasten “Tipps für sichere Passwörter”). Geburtsdaten oder Hundenamen sind wesentlich beliebter als eine zufällig gewählte 22-stellige Zeichenfolge. Eine solche Zeichenkette ist aber nötig, um einen 128-Bit-Schlüssel darzustellen.
| Plädoyer für Festplattenverschlüsselung |
|---|
| Gegenüber einzeln mit GnuPG verschlüsselten Dateien hat transparente Festplattenverschlüsselung einen großen Vorteil: Sie greift automatisch auch für temporäre Files, Befehls-Histories und Konfigurationsdateien. Bei GnuPG wäre es kaum möglich, die Existenz geheimer Daten zu leugnen, wenn die ».bash_history« folgende Kommandos verzeichnet: »gpg document.tex.gpg« und »emacs document.tex«. Genauso unbrauchbar wird selektive Verschlüsselung für Spione, die sich mit Gnome-Programmen Spionagefotos ansehen. Die Gnome Thumbnail Factory legt nämlich ihre Daten nach Gutdünken in »~/.thumbnails« ab.
Ist sein Home Directory nicht verschlüsselt, hat der Spion eine dicke Schwachstelle in seiner Geheimhaltung. Genauso wäre beim Drucken geheimer Dokumente »/var/spool/cups« eine wahre Fundgrube. Statt dem Benutzer die Sisyphusarbeit zu überlassen, jedes verwendete Programm zu inspizieren und dessen Spuren zu verwischen, verbirgt die Strategie “Verschlüsseln per Default” jedes unbekannte und unerwartete File vor fremden Blicken. Gegen Verschlüsselung spricht vor allem die Performance. Auf einem handelsüblichen Pentium 4 mit 1,8 GHz sinkt der Datendurchsatz auf weniger als die Hälfte. Statt 53 MByte/s liefert eine verschlüsselte Festplattenpartition knappe 23 MByte/s. Großzügig bemessener Hauptspeicher wirkt dem entgegen: So lange die Zugriffe dank Cacheing im Hauptspeicher des Rechners ablaufen, wirken sich die langsameren Festplattenzugriffe nicht aus. Performance und Sicherheit im WiderspruchEin Kompromiss wäre, nur bestimmte Verzeichnisse zu verschlüsseln. Im »/usr«-Baum ist kaum mit geheimen Daten zu rechnen. Allerdings gilt diese Annahme nur bedingt, wie das Beispiel »/usr/tmp« belegt. Häufige Problemstellen sind auch öffentlich beschreibbare Verzeichnisse und Dateien. Eine Suche per »find /usr -perm -002 -a ! -type l« deckt diese Stellen auf. Vorsicht: Nach jeder Software-Installation ist der Test erneut fällig. Schnelle Datenvernichtung ist ein weiterer Vorteil verschlüsselter Verzeichnisse. Kryptographie und Datenvernichtung haben gemeinsam, dass sie sich mit der Verknappung von Information befassen. Der Sicherheitsexperte und Linux-Magazin-Autor Peter Gutmann beschreibt in einem Paper [2], dass die letzten Spuren von Daten erst nach 39-maligem Überschreiben von einer Festplatte verschwinden. Statt eine handelsübliche 120-GByte-Platte so aufwändig zu löschen, genügt es, den Schlüssel zu vernichten, um die damit chiffrierten Daten loszuwerden. Mit dem LUKS-Passwortmanagement klappt das binnen Sekunden. |
Da sich niemand zum Beispiel »Sq5woq7501VUE5irAXau.a« merken oder täglich eintippen möchte, ist Abhilfe erforderlich. Eine gute Ableitungsfunktion erfüllt beide Forderungen: Der Benutzer gibt ein leicht zu merkendes Passwort ein, aus dem die Funktion einen kryptisch klingenden Schlüssel konstanter Länge ableitet.
Zufall hinzufügen
Ein Verfahren, das ein kurzes Passwort auf 128 Bit aufbläst, muss die Entropy Gap überwinden, die Kluft beim Grad an Zufälligkeit zwischen der Passwort- und der Schlüsseldomäne. Der Schlüssel ist bei einfachem Padding (Auffüllen mit vorgegebenen Werten) zwar größer, aber nicht zufälliger als das Passwort und damit genauso leicht zu erraten.
Wenn die User ausschließlich deutsche Wörter eingeben, bleibt die Menge möglicher Passwörter begrenzt und damit die Informationsvielfalt zu gering. Ein Angreifer braucht nur das Wörterbuch durchzuprobieren, nicht alle 2128 Schlüssel, die für 128 Bit möglich sind. Ein deutsches Wörterbuch hat weniger als 220 Einträge. Das sind 108 Potenzen weniger, eine dramatische Vereinfachung. Ein Angriff auf einen 20-Bit-Schlüssel ist von jedermann durchführbar.
PBKDF2 begegnet diesem Problem, indem es die Ableitung eines Schlüssels aus dem Passwort mit einer absichtlich rechenintensiven Funktion ermittelt. Das kostet Zeit, die legitime Benutzer nicht stört, da sie diese Funktion nur einmal durchrechnen. Der Angreifer muss jedoch 220 Begriffe probieren.
Benötigt jeder Aufruf eine Sekunde, vergehen zwölf Tage (220 Sekunden). Kombiniert der Benutzer zwei deutsche Wörter zu einem Passwort, benötigt der Knackversuch bis zu 30000 Jahre (240 Sekunden). Diese künstliche Verlangsamung heißt Stretching. PBKDF2 nutzt dafür eine Funktion, deren Rechenintensität beliebig variierbar ist.
Gesalzenes Stretching
Das reicht aber noch nicht aus, um Angreifer zu bremsen. Sie könnten vorab eine große Tabelle mit allen Ein- und Ausgaben der Stretching-Funktion anlegen und damit den Rechenaufwand bei künftigen Knackversuchen sparen. Um das zu verhindern, fügt PBKDF2 eine zufällig gewählte Zeichenkette an das Passwort an, bevor es den Schlüssel ableitet. Die Klartextfassung dieser Zeichenkette speichert LUKS im Partitionsheader.
Nach dem Salting reicht es für einen Angreifer nicht mehr aus, die PBKDF2-Übersetzungen für jedes deutsche Wort zu wissen. Er müsste sie für alle deutschen Wörter und für alle Kombinationen der angehängten Zeichenkette wissen. Je länger der Salt, desto größer müsste die Tabelle des Angreifers sein. PBKDF2 treibt die Größer dieser Tabelle in schwer vorstellbare Dimensionen: Das Universalwörterbuch müsste mehr Einträge haben als sich Atome im Universum befinden, um auf alle möglichen PBKDF2-Kombinationen zu passen.
Mit wenig Hoffnung auf Tabellierung führt der Angreifer zwangsläufig die Berechnungen selbst durch. Einen ganz ähnlichen Weg beschreitet übrigens der klassische Unix-Passwortmechanismus: Auch er verwendet einen Salt, der allerdings wesentlich kürzer ausfällt (12 Bit, in den ersten zwei Zeichen abgelegt).
| Tipps für sichere Passwörter |
|---|
| Viel wahrscheinlicher als das Brechen der Verschlüsselung ist die Bedrohung durch das eigene Gedächtnis. Kryptographie ist unbestechlich; wer sein Passwort vergisst, hat kaum noch eine Chance, seine Daten je wiederzusehen. Überlegungen zur Wahl eines guten Passworts sind daher angebracht.
Zu kurz darf die geheime Zeichenfolge nicht sein, weil sonst Wörterbuchangriffe viel zu schnell zum Ziel kommen. Der Angreifer probiert bei dieser Technik alle Einträge in Wortlisten durch sowie Kombinationen aus diesen Begriffen. Eine achtstellige Zufallskombination aus Zeichen und Buchstaben gilt als absolutes Minimum, um solche Angriffe zu vereiteln. Je mehr Zeichen desto besser – die Erfahrung zeigt, dass man sich schnell daran gewöhnt, jeden Morgen 13 Zeichen zu tippen. Es empfiehlt sich, beim Verschlüsseln nicht nur auf eine Karte zu setzen. Eine Partition ohne Backup-Passwort wird leicht Opfer einer durchzechten Nacht – ohne Kenntnis des Passworts sind die Daten unwiderruflich verloren. Mit LUKS ist es möglich, mehrere Passwörter zu setzen. Ein Backup-Passwort hilft jedoch wenig, wenn der Benutzer das Hauptpasswort schon nicht behalten kann. In einer Welt, die an allen Ecken mit Information überflutet ist, kommt der menschliche Sammeltrieb zu neuen Ehren: Einfach aus der riesigen Menge ein paar Schnipsel auswählen, die sich gut in Buchstaben- und Ziffernfolgen umwandeln lassen oder schon in dieser Form vorliegen. Zum Beispiel schnappt man sich Shakespeares “Romeo und Julia”, schlägt im zweiten Akt die fünfte Szene auf und tippt Julias ersten Satz mit ein paar gut zu merkenden Modifikationen – das wäre eine solide Basis für ein Backup-Passwort. Ein Angreifer wird kaum die Zeit haben, jede mögliche Textpassage aus allen Büchern testweise abzutippen. Nutze die InformationsflutWer es persönlicher will, sortiert die Schulnoten seiner Volksschulzeit chronologisch. Es eignen sich auch digitale Daten, zum Beispiel könnte man die ISO-Images seiner drei Lieblings-CDs als LUKS-Key-File verwenden. Wichtig ist aber, dass das Backup-Passwort aus einer größeren Datenmenge stammt als das Passwort zum täglichen Gebrauch. Andernfalls ist es für den Angreifer leichter, das Backup-Passwort zu knacken; die Mühe, sich ein längeres Hauptpasswort zu merken, wäre vergeblich. Die hier angeführten Tipps sollte niemand unverändert in die Tat umsetzen, da Angreifer nach Erscheinen das Artikels überproportional oft “Willst du schon gehn? Der Tag ist ja noch fern. Es war die Nachtigall und nicht die Lerche …” probieren werden. Das Prinzip ist einfach, gefragt ist Fantasie. |
Vernichtung
Wie im Kasten “Plädoyer für Festplattenverschlüsselung” erwähnt, ist Datenvernichtung auf magnetischen Speichermedien nicht ohne weiteres möglich [2]. Um wirksam Passwörter in der Schlüsselhierarchie zu ändern oder aus ihr zu entfernen, ist es unerlässlich, die alte Kopie des Master-Key vollständig zu vernichten. Mit etwas Glück erwischt man beim (mehrfachen) Überschreiben den richtigen Sektor der Festplatte und löscht den alten Master-Key. Nur ist Glück nichts, worauf Benutzer und Kryptographen vertrauen wollen.
Die Datenvernichtung findet in der Festplatten-Firmware einen Gegenspieler, der sich für das Gegenteil interessiert: Datensicherheit. Eine Maßnahme dafür ist beispielsweise Sector Remapping, eine einfache Technik, die schlecht lesbare Sektoren erkennt. Die Firmware kopiert deren Inhalt in eine reservierte Festplattenzone und leitet jeden weiteren Zugriff auf den Originalsektor zu der neuen Kopie um. Der Originalsektor ist ab diesem Zeitpunkt nicht mehr löschbar, da die Firmware auch jeden Schreibzugriff in die Reserved-Zone leitet. Damit verbleiben alte Schlüsselfragmente auf der Festplatte, an die ein Datenrettungsprofi oder ein gewiefter Angreifer mit Hilfe einer modifizierten Firmware doch noch herankommt.
Dieses Problem trifft die Master-Keys von LUKS besonders hart: Sie sind im Verhältnis zur Sektorgröße sehr kurz (bei AES 128, 192 oder 256 Bit) und passen somit problemlos in einen Sektor. Es genügt, wenn die Firmware diesen einen Sektor in die Reserved-Zone verlagert hat, während das alte Passwort noch aktiv war. Weder SCSI noch ATAPI stellen Kommandos für den Zugriff auf solche Originalsektoren bereit.
Datenretter ausgetrickst
Als Lösung hat der LUKS-Autor ein Verfahren namens Anti-Forensic Information Splitting entwickelt (AF-Splitter). Um die statistische Chance zu minimieren, dass Spuren von gelöschten Daten auf magnetischen Speichermedien überleben, bläht der AF-Splitter diese Daten auf das Viertausendfache auf. Die aufgeblasene Information ist nicht redundant, es ist immer der komplette Datensatz nötig, um den Master-Key zu bestimmen. Diese Umkehrfunktion zum Information Splitting heißt Merging. Es fügt die Originaldaten im Speicher wieder zusammen – dort ist die Datenvernichtung problemlos möglich.
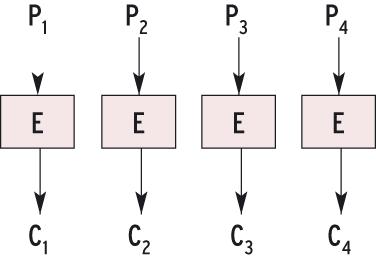
Abbildung 4: Der ECB-Verschlüsselungsmodus (Electronic Code Book) chiffriert jeden Klartextblock unabhängig von allen anderen. Daraus folgt, dass gleiche Eingaben Pi in die Verschlüsselungsfunktion E zu identischen Ausgaben Ci führen.
AF-Splitter verteilt die Originaldaten (Variable x) gemäß der Gleichung x = a1 + a2 + a3 + … + a4000. Die Variablen a1 bis a3999 generiert der Algorithmus zufällig und berechnet a4000 so, dass die Gleichung erfüllt ist. Der Merger addiert alle Element ai. Dazu braucht er jedes einzelne Element, es gibt keine Redundanz. Fehlt ein Element wird die Gleichung unterbestimmt und x ist nicht zu berechnen.
Zur Vernichtung genügt es, einen einzigen der 4000 beteiligten Sektoren erfolgreich zu überschreiben, da der Merging-Prozess den gesamten aufgeblähten Datensatz benötigt. Einen beliebigen Sektor von 4000 zu vernichten fällt wesentlich leichter, frei nach dem Motto “Einen werde ich schon erwischen”. Dass dies statistisch sehr gut klappt, ist in [1] nachzulesen. Dank AF-Splitter gelingt es, Passwörter zu ändern, ohne verwertbare Spuren zu hinterlassen. Zusammen mit Schlüsselhierarchien und PBKDF2 ergibt sich ein hochwertiges Passwortmanagement für DM-Crypt-Partitionen.
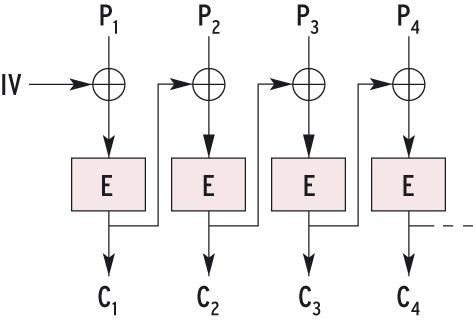
Abbildung 5: Der CBC-Modus (Cipher Block Chaining) bezieht das Chiffrat einer Stufe in die folgende Berechnung mit ein (XOR-Operation). Damit stellt dieser Betriebsmodus sicher, dass gleiche Klartextblöcke unterschiedlich verschlüsselt werden.
Sichere Datenhaltung
Die Kernaufgabe verschlüsselter Festplatten bleibt das Verschlüsseln. DM-Crypt beherrscht derzeit zwei Cipher-Modi, ECB (Electronic Code Book) und CBC (Cipher Block Chaining). Beide leiden unter Sicherheitsproblemen, die der gegenwärtig aussichtsreichste Kandidat LRW-AES ([6], [7]) löst (LRW: Liskov, Rivest, Wagner; AES: Advanced Encryption Standard).
ECB (Abbildung 4) trägt die Bezeichnung Cipher-Modus eigentlich zu Unrecht: Er speichert jedes Einzelergebnis der Blockchiffre ohne weitere Berechnungen. Daraus folgt zwingend, dass bei gleichem Schlüssel jeder Klartext zu einem identischen Chiffrat führt. Mathematisch ausgedrückt ist ECB eine bijektive Funktion von Klartext in die Chiffretext-Domäne. Diese Eigenschaft ist gefährlich, wenn ein Angreifer den Klartext zu einem verschlüsselten Block kennt, zum Beispiel aufgrund genormter Filesystem-Header.
| ESSIV |
|---|
| Mit einem digitalen Wasserzeichen markieren Angreifer einen Text, den sie später in einem verschlüsselten Datenblock wiedererkennen wollen. Der Angreifer muss dazu zwei idente Sektoren auf der Platte erzeugen. Sein Ziel ist, die Verschlüsselung so zu manipulieren, dass die gespeicherten Verschlüsselungsergebnisse von zwei Sektoren gleich lauten.
In Abbildung 5 ist zu erkennen, dass der Angreifer alle Eingabewerte Pi bestimmen kann, nur nicht den IV. Dieser Wert modifiziert den ersten Klartext, siehe Abbildung 6a. Watermarking verhindern dies, indem es den zweiten Sektor mit P1-1 statt P1 verwendet. Der IV des zweiten Sektors ist um 1 höher als der IV des ersten. Diese Erhöhung lässt sich durch die Subtraktion von 1 in P1 kompensieren (Abbildung 6b). Setzt der Angreifer alle weiteren Pi wie beim ersten Sektor, dann sind deren Chiffretexte komplett gleich. 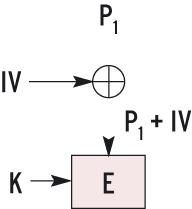 Abbildung 6a: CBC startet die Verschlüsselung mit einer XOR-Verknüpfung von IV und P1. 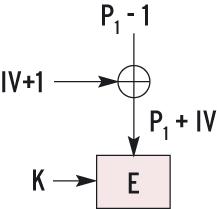 Abbildung 6b: Watermarking kompensiert die Änderung des IV durch ein angepasstes P1. ESSIV (Encrypted Salt-Sector IV) behebt das Problem. Es schickt die Sektornummer in eine Funktion, deren Ergebnis von der Nummer und vom geheimen Schlüssel abhängt (Abbildung 6c). Der Angreifer kann P1 im zweiten Sektor nicht mehr so gestalten, dass er die IV-Differenzen kompensiert. Ihm fehlt der Schlüssel K, um die beiden IVs zu berechnen. 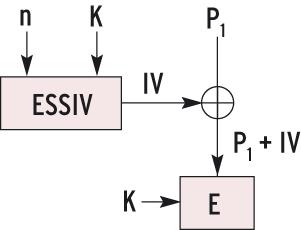 Abbildung 6c: Bei ESSIV kann der Angreifer den IV nicht berechnen, da er das geheime Schlüsselmaterial K nicht kennt. |
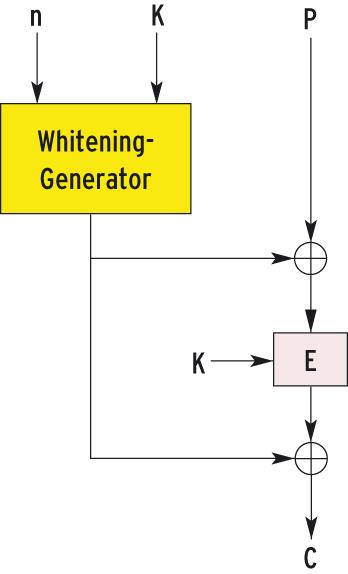
Abbildung 7: Der LRW-Verschlüsselungsmodus kommt ohne Rekursion aus. Er verhindert die Vergleichsattacke im Stil von ECB (Abbildung 4) durch die Addition eines Whitening. Das Whitening berechnet sich aus der Position n auf der Festplatte und dem geheimen Schlüssel K.
Weiß der Angreifer, dass der erste Sektor der verschlüsselten Partition mit einer Serie von Nullen beginnt, so weiß er auch, an welchen anderen Stellen nur Nullen verschlüsselt sind. Er braucht dazu keinen Schlüssel, er vergleicht einfach alle Chiffretext-Blöcke mit dem Partitionsanfang. Hat er einen gleichen Block gefunden, so erfährt er, dass der entschlüsselte Inhalt an dieser Plattenposition auch aus Nullen besteht. Gleiches gilt für jeden anderen Klartextblock.
Versteckspiele
Es gibt im Wesentlichen zwei Methoden, um diese Redundanzen des Klartexts besser zu verstecken. Ein Ansatz lautet: Eine Komponente in die Verschlüsselung aufnehmen, die für jede Plattenposition einmalig ist, zum Beispiel die Plattenposition selbst. Damit erzeugen gleiche Klartextblöcke an unterschiedlichen Plattenpositionen unterschiedliche Verschlüsselungsergebnisse.
Die zweite Lösung verwendet Betriebsmodi, die bereits chiffrierte Blöcke beim Verschlüsseln eines neuen Blocks mit berücksichtigen. Am einfachsten ist das mit einer Rekursion zu realisieren. CBC (Cipher Block Chaining) ist seit langem trotz seiner Einfachheit ein wirkungsvoller rekursiver Verschlüsselungsmodus. Er verknüpft den Chiffretext des zuletzt verschlüsselten Blocks per XOR-Operation mit dem aktuellen Klartext. Diesen modifizierten Klartext verschlüsselt CBC dann und verwendet das Ergebnis für den nächsten Klartext.
Der Aufbau von CBC ist in Abbildung 5 dargestellt. Selbst wenn mehrere aufeinander folgende Klartextblöcke identisch sind, löst die rekursive Konstruktion einen Schneeballeffekt aus. Durch die Verkettungen werden alle gleichen Klartextblöcke mit unterschiedlichen Chiffretext-Ergebnissen modifiziert.
Schneeballeffekt
Eine Eigenschaft dieser Rekursion ist, dass sich der erste Verschlüsselungsschritt auf alle folgenden auswirkt. Für die Festplattenverschlüsselung ist das ungeeignet: Sie müsste die komplette Partition neu chiffrieren, wenn sich der Inhalt des ersten Sektors ändert. Die übliche Antwort lautet, jeden Sektor als abgeschlossene Rekursion zu betrachten und unabhängig von den anderen Sektoren zu verarbeiten.
Das führt zu einem bekannten Problem: Zwei Sektoren mit identischem Klartext führen zu gleichen Chiffretexten. Die Sektoren sind zwar wesentlich größer als die Blöcke der Blockchiffren, können aber dennoch den gleichen Inhalt aufweisen, wenn zum Beispiel der User mehrere Kopien einer Datei anlegt. Hier greift der erste Trick: Die Sektornummer soll die Verschlüsselung beeinflussen, indem sie wie in Abbildung 5 den Initialisierungsvektor (IV) bestimmt. Zwei unterschiedliche Modifikationen des ersten Klartexts lösen unterschiedliche Schneeballeffekte aus und führen zu unterschiedlichen Chiffraten.
Sektornummer als IV
Die Standardvariante von DM-Crypt nimmt die Sektornummer direkt als IV. Diese IV-Generierung heißt Plain. Sie ist allerdings anfällig für den so genannten Watermarking-Angriff. Ein Angreifer formt dabei Daten so, dass er sie in einer verschlüsselten Festplatte wiederfindet, ohne den Schlüssel zu kennen.
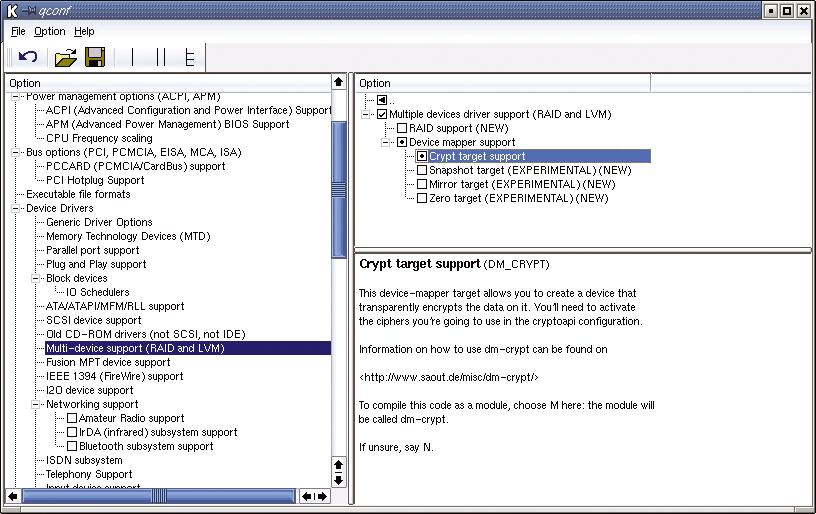
Abbildung 8: Der Device Mapper ist in der Kernelkonfiguration unter »Device Drivers | Multi-device support (RAID and LVM) | Device mapper support« zu finden. Für DM-Crypt ist der »Crypt target support« nötig.
| Listing 1: Cryptsetup-LUKS |
|---|
02 1+0 records in 03 1+0 records out 04 $ losetup /dev/loop0 verysecret.loop 05 $ cryptsetup -c aes-cbc-essiv:sha256 -y -s 256 luksFormat /dev/loop0 06 07 WARNING! 08 ======== 09 This will overwrite data on /dev/loop0 irrevocably. 10 11 Are you sure? (Type uppercase yes): YES 12 Enter LUKS passphrase: ****** 13 Verify passphrase: ****** 14 $ cryptsetup luksOpen /dev/loop0 verysecret 15 Enter LUKS passphrase: ****** 16 key slot 0 unlocked. 17 $ mkfs.xfs /dev/mapper/verysecret 18 [...] 19 $ mount /dev/mapper/verysecret /mnt 20 $ umount /mnt 21 $ cryptsetup luksClose verysecret 22 $ cryptsetup luksAddKey /dev/loop0 23 Enter any LUKS passphrase: ****** 24 key slot 0 unlocked. 25 Enter new passphrase for key slot: ****** 26 $ cryptsetup luksDelKey /dev/loop0 0 27 losetup -d /dev/loop0 |
Diese Markierungen (Watermarks) transportieren bis zu 5 Bit Information [1]. Ein Angreifer könnte solche Marken in E-Mails einfügen und an sein Opfer senden, um später herauszufinden, ob und wenn ja wo es die Nachrichten abgespeichert hat. Denkbar sind auch Watermarks in MP3-Dateien, Bildern oder beliebigen Files, die ein misstrauischer Chef seinem Mitarbeiter unterschiebt. Damit sind Angriffe auf die Privatsphäre möglich: Ohne Entschlüsselung erhält der Spion Informationen über den Inhalt der Festplatte.
Der IV-Generator ESSIV (Encrypted Salt-Sector IV) verhindert derlei. Watermarking beruht darauf, dass der IV zweier aufeinander folgender Sektoren in einem einfachen Zusammenhang stehen. Bei Plain ist das der Fall: Auf den IV des Sektors n folgt der IV n+1 im nächsten Sektor. ESSIV sorgt für eine kompliziertere Folge, die der Angreifer nicht berechnen kann, ohne Teile des geheimen Schlüssels zu kennen (Kasten “ESSIV”).
Es drängt sich die Frage auf, warum DM-Crypt eine Mischung aus Rekursion und Beeinflussung durch die Plattenposition nutzt. Letzteres sollte eigentlich ausreichen. CBC ist aus historischen Gründen weiterhin Teil des Verfahrens: Es hat sich seit langem bewährt und seine Eigenschaften sind ausreichend untersucht. Die Alternativen, die sich ausschließlich auf die Blocknummer verlassen, sind für kryptographische Bewährungsfristen dagegen sehr jung.
Daten tünchen
LRW ist ein solcher Verschlüsselungsmodus, der die Blocknummer in die Verschlüsselung auf eine ebenso einfache wie effektive Art einwebt. Zuerst berechnet LRW ein Whitening (weiße Farbe, Schlämmkreide) in Abhängigkeit vom geheimen Schlüssel und der Blocknummer. Dieses Whitening addiert es zum Klartext, verschlüsselt den Summenwert und addiert anschließend erneut das Whitening (Abbildung 7). Die beiden Schritte heißen auch Pre- und Postwhitening. Sie binden den Chiffretext an eine Plattenposition und erreichen damit, dass gleiche Klartexte an unterschiedlichen Plattenpositionen unterschiedlich verschlüsselt werden.
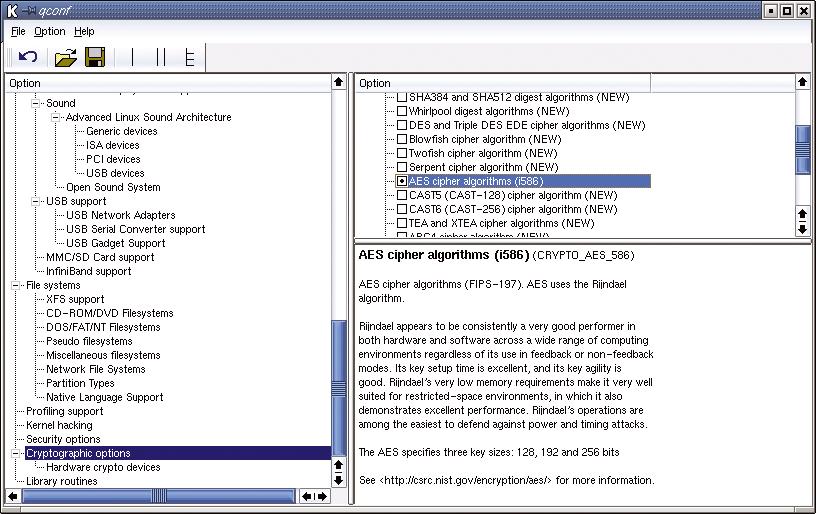
Abbildung 9: Da DM-Crypt die Verschlüsselung mit Hilfe des Crypto-API erledigt, muss unter »Cryptographic options | Cryptographic API« mindestens ein Algorithmus ausgewählt sein. Empfehlenswert ist derzeit AES.
LRW behebt alle bekannten Sicherheitsprobleme von CBC und glänzt zudem mit besserer Performance. Während CBC nicht mit der Anzahl der Prozessoren skaliert, da die Rekursion für jeden Rechenschritt das Ergebnis des vorherigen benötigt, können bei LRW mehrere Prozessoren gleichzeitig arbeiten. Der Autor von LUKS und Koautor dieses Artikels, Clemens Fruhwirth, hat LRW für DM-Crypt implementiert, getestet und stand schon kurz vor der Fertigstellung.
Am Kernel gescheitert
Dennoch ist LRW derzeit nicht für DM-Crypt verfügbar. Das Design des High/Low-Memory von Linux verhindert, dass Kernelmodule mehr als zwei Datenbereiche des High Memory bearbeiten. Die LRW-Implementation basiert aber auf dem Versuch einer generischen Neuimplementierung von Scatterwalk (Teil des Crypto-API), die auf beliebig viele High-Memory-Bereiche gleichzeitig zugreifen sollte. Wegen der gegenwärtigen Beschränkung auf zwei Speicherbereiche scheint eine generische Implementierung nicht zielführend. Frustriert hat der Autor die Arbeiten an diesem Problem abgebrochen [8].
Für DM-Crypt bleibt daher CBC-ESSIV der sicherste implementierte Chiffriermodus – bis sich jemand findet, der sich von frucht- und endlosen Detaildiskussionen auf der Kernel-Mailingliste [9] nicht abschrecken lässt und eine geeignete Scatterwalk-Variante entwickelt. Die Autoren dieses Artikels würden sich sehr freuen. Die Mathematik hinter LRW ist bereits vollständig und standardkonform implementiert.
Installation
Der Einsatz von DM-Crypt, Cryptsetup und LUKS setzt ein Userspace-Tool und einige Kernelmodule voraus. DM-Crypt ist seit Kernel 2.6.4 offizieller Linux-Bestandteil, für den IV-Generator ESSIV ist mindestens die Kernelversion 2.6.10 anzuraten.
Die Optionen für DM-Crypt verstecken sich in der Kernelkonfiguration unter »Device Drivers | Multi-device support | Device mapper support« und in derselben Sektion »Crypt target support« (Abbildung 8). Achtung: Unter »Code maturity level options« muss »Prompt for development and/or incomplete code/drivers« ausgewählt sein, andernfalls bleibt das Crypt-Target verborgen.
Verschlüsselungs-API im Kernel
Da DM-Crypt die Funktionen aus dem Crypto-API verwendet, ist mindestens ein Algorithmus unter »Cryptographic options | Cryptographic API« auszuwählen (Abbildung 9). Die Autoren empfehlen AES. Die meisten Linux-Distributionen haben diese Optionen bereits gesetzt. Mit »modprobe dm-crypt« lässt sich das prüfen: Das Kommando sollte problemlos funktionieren.
Ein Verschlüsselungsalgorithmus genügt; weitere Operation wie das Hashing beim Ableiten des Schlüssels aus dem Passwort übernimmt das Userspace-Tool Cryptsetup-LUKS. Es steht unter [4] zum Download bereit. Für Debian, Gentoo und Suse gibt es fertige Pakete, bei Fedora 4 ist es bereits Standard. Benutzer anderer Distributionen kommen mit dem typischen Dreierschritt »./configure && make && make install« zum Ziel – vorausgesetzt auf ihrem System sind Libpopt, Libgcrypt (mindestens Version 1.1.42) und Libdevmapper installiert.
Cryptsetup-LUKS
Das fertige Binary hört auf den Namen »cryptsetup« und unterstützt mehrere so genannte Aktionen und dazu passende Parameter. Es fügt sich in die restlichen Tools ein, mit denen Linux-Admins ihre Blockdevices mit Filesystemen ausstatten und mounten. Listing 1 zeigt exemplarisch einen solchen Ablauf. Damit das Beispiel auch ohne eigene Festplattenpartition funktioniert, erzeugt der Aufruf in Zeile 1 per »dd« einen 50-MByte-Container, den Zeile 4 im Loop-Verfahren als Blockdevice zur Verfügung stellt.
Vorbereitung
Die zu Beginn wichtigste Cryptsetup-Aktion heißt »luksFormat« und bereitet das Backing Blockdevice (hier das Loopback-Device) auf den verschlüsselten Einsatz vor. In diesem Schritt fällt die Entscheidung für den gewünschten Verschlüsselungsalgorithmus.
Die Formatierungsaktion benötigt als Parameter das zu verwendende Blockdevice und optional eine Datei, deren Inhalt als Passwort dient. LUKS nennt diese Datei Key-File. Sinnvoll sind zudem folgende Parameter:
- »-c« bestimmt den Algorithmus und bei neueren
Kernelversionen den Chaining Mode sowie den IV-Generator. Diese
drei Angaben sind durch einfache Bindestriche getrennt (Standard:
»aes-cbc-plain«). Die derzeit sicherste Variante
heißt »aes-cbc-essiv:sha256«. - »-y« lässt Cryptsetup das Passwort zweimal
abfragen, um Fehlbedienungen durch Tippfehler zu vermeiden. Dieser
Parameter wäre in Kombination mit Key-Files sinnlos. - »-s« bestimmt die Länge des zur
Verschlüsselung benutzten Keys.
Zeile 5 von Listing 1 zeigt den kompletten Aufruf. Durch Eingabe von »YES« bestätigt der Anwender in Zeile 11, dass er sich im Klaren darüber ist, dass nun eventuell vorhandene Daten verloren gehen. Anschließend setzt er das erste Passwort (Zeile 12) und wiederholt es (wegen der Option »-y«) in Zeile 13.
Mapping zum Filesystem
Um das so vorbereitete Blockdevice zu nutzen, muss Cryptsetup-LUKS ein Mapping erstellen, also eine Zuordnung zwischen realem und virtuellem Blockdevice anlegen. Dazu dient die Aktion »luksOpen«, die als Parameter das reale und einen Namen für das virtuelle Blockdevice erwartet (Zeile 14). Ist das Passwort in einer Datei gespeichert (siehe »luksFormat«), erwartet Cryptsetup den Namen des Key-File hinter dem Parameter »-d«. Im Beispiel tippt der User sein Passwort selbst ein (Zeile 15).
Unter »/dev/mapper/« erstellt Cryptsetup-LUKS automatisch ein Blockdevice mit dem angegebenen Namen »verysecret«. Der »mkfs.xfs«-Aufruf in Zeile 17 versieht dieses Device mit einem XFS-Dateisystem. Das Ergebnis lässt sich problemlos mounten (Zeile 19).
Um das fertig gestellte Verzeichnis zu nutzen, genügen künftig die Schritte in Zeile 1 (Loopback-Device mounten), 14 (DM-Crypt aktivieren) und 19 (Filesystem mounten). DM-Crypt ver- und entschlüsselt dann alle Daten unsichtbar im Hintergrund.
Aufräumarbeiten
Vor weiteren Änderungen ist ein Unmounten (Zeile 20) angesagt. Nach getaner Arbeit sollte man das Mapping wieder entfernen, um potenziellen Angreifern und neugierigen Chefs die Inhalte nicht unnötig zu präsentieren. Dazu ist die Aktion »luksClose« vorgesehen. Sie braucht nur den Namen des virtuellen Blockdevice (Listing 1, Zeile 21).
Wie weiter oben bereits ausgeführt, verwaltet Cryptsetup-LUKS auf Wunsch mehrere Passwörter pro Blockdevice. Damit ist es leicht, ein kompromittiertes Passwort zu ändern, ohne alle Daten zeitraubend neu zu verschlüsseln. Die Aktion »luksAddKey« erwartet das reale Blockdevice als Parameter (Listing 1, Zeile 22). Nach Eingabe eines beliebigen bestehenden Passworts fragt das Tool nach einem neuen, zusätzlichen Passwort. Statt des neuen Passworts kann der Benutzer hier wieder ein Key-File verwenden.
Ein bestehendes Passwort entfernt die »luksDelKey«-Aktion (Zeile 26). Sie erwartet vom Anwender das reale Blockdevice und zusätzlich den zu löschenden Key-Slot. Letzterer ist der Speicherort des Schlüssels. Da Cryptsetup-LUKS per Default acht Passwörter verwaltet, reichen die Key-Slots von 0 bis 7. In welchem Key-Slot ein Passwort gespeichert ist, gibt das Programm bei jedem Aufruf von »luksOpen« (Zeile 16) oder »luksAddKey« aus (Zeile 24).
Realitätssinn
Würden in Hollywoods Fantasiewelt Geheimdienste, Bankangestellte, Mafiosi und sonstige Chefs listig ihre Daten mit Cryptsetup-LUKS und DM-Crypt chiffrieren, bliebe die Spannung auf der Strecke. Es wäre vorab klar, dass jeder Entschlüsselungsversuch scheitert. Da sich Filmemacher nur bedingt um die Realität sorgen, dürfen sich Linux-Benutzer entspannt zurücklehnen und beim nächsten Cracking-Schriftzug auf der Kinoleinwand wissend lächeln. (fjl)
| Infos |
|---|
| [1] Clemens Fruhwirth, “New Methods in Hard Disk Encryption”: [http://clemens.endorphin.org/publications]
[2] Peter Gutmann, “Secure Deletion of Data from Magnetic and Solid-State Memory”: [http://www.cs.auckland.ac.nz/~pgut001/pubs/secure_del.html] [3] Clemens Fruhwirth, “LUKS On-Disk Format Specification”: [http://luks.endorphin.org/LUKS-on-disk-format.pdf] [4] LUKS-Software: [http://luks.endorphin.org] [5] RFC 2898, “PKCS #5: Password-Based Cryptography Specification Version 2.0”: [http://rfc.net/rfc2898.html] [6] Moses Liskov, Ronald L. Rivest und David Wagner, “Tweakable Block Ciphers”:[http://www.cs.berkeley.edu/~daw/papers/tweak-crypto02.pdf] [7] IEEE, “Draft Proposal for Tweakable Narrow-block Encryption”: [http://www.siswg.org/docs/LRW-AES-10-19-2004.pdf] [8] Clemens Fruhwirth, “LRW for Linux is dead”: [http://grouper.ieee.org/groups/1619/email/msg00253.html] [9] Diskussion auf der Kernel-Mailingsliste: [http://lkml.org/lkml/2005/1/24/54] |
| Die Autoren |
|---|
| Clemens Fruhwirth ist der Autor von LUKS [4] und des Paper “New Methods in Hard Disk Encryption” [1], das die theoretischen Grundlagen legt. Zudem hat er ESSIV erfunden und LRW-AES und EME für Linux implementiert.
Markus Schuster arbeitet als Systemintegrator beim IT-Dienstleister Bits & Bytes, bezeichnet sich als Free-Software-Allrounder und benutzt LUKS seit dessen Anfängen. |






