Du kommst da net rein: Dieser Spruch selbstgefälliger Türsteher ist bei sicherer Software unvermeidbar. Jedes Programm muss genau wissen, welche Daten zu ihm passen und welche es ablehnt. Die guten von bösen Eingaben unterscheiden fällt aber nicht immer leicht.
Software, die sinnvolle Arbeit verrichtet, bezieht fast unweigerlich Eingaben von Anwendern, anderen Programmen, aus dem Netz oder aus dem lokalen System. Die üblichen Datenpfade sind Argumente der Kommandozeile, Dateien, Eingaben von Maus und Tastatur, Signale und vieles mehr. Manche Programme erhalten ihre Eingaben bereits beim Start, andere erst, während sie laufen. Die erste Folge dieses Workshops [1] hat sich unter anderem mit überraschenden Eingaben beim Programmstart beschäftigt; dieser Teil geht näher auf die Sicherheitsfolgen der erwünschten und unerwünschten Eingaben ein.
Wie ernst diese Gefahren sind, bestätigt ein Blick auf einschlägigen Sicherheitsseiten. Bei Securitytracker [8] füllen die so genannten Boundary Errors eine ganze Kategorie (siehe Abbildung 1). Meist mehrmals pro Tag ergänzen die Betreiber neue Sicherheitslücken in dieser Fehlerklasse.
Wie schnell solche Fehler passieren, zeigt das einfach gestrickte Programm »patch-fstring« in Listing 1. Es schreibt in einer vorhandenen Datei an eine bestimmte Stelle eine Zeichenkette und verlangt dafür auf der Kommandozeile vier Argumente: den Dateinamen, eine Blockgröße und -nummer und als Letztes den Korrekturstring. Die Position, an der das Patchprogramm den String einfügt, berechnet es aus Blockgröße mal Blocknummer.
Beispiel: Files patchen
In den Zeilen 8 bis 11 (Listing 1) speichert der Code seine Aufrufargumente in eigenen Variablen. Dann öffnet das Programm die Datei mit »fopen()« (Zeile 13), berechnet die Position (Zeile 17) und spult den Dateizeiger mit »fseek()« zur gewünschten Stelle vor (Zeile 18). Abschließend schreibt »fprintf()« in Zeile 21 die Daten in die Datei.
Dieser unscheinbare Code steckt trotz seiner Kürze voller Probleme:
- Es ist nicht sicher, dass der Aufrufer wirklich vier Argumente
übergibt, er könnte das Programm auch mit
»patch-fstring foo 1 2« starten. - Die Ascii-to-Integer-Funktion »atoi()« liefert 0,
wenn sie ihre Eingabe nicht als Zahl erkennt (Zeilen 9 und 10;
Aufruf etwa mit »patch-string foo 0x100 10
hallo«). - Bei der Multiplikation großer Zahlen kann es zu einem
Integerüberlauf kommen (»patch-fstring foo 1000000 8000
hallo«). - Der »fprintf()«-Aufruf ist zudem anfällig
für Formatstring-Angriffe, wenn der Benutzer Prozentzeichen
eingibt (»patch-fstring %n%n%n 0 0 0«) [7].
Die ersten drei Anwendungsfehler führen eventuell dazu, dass das Patchprogramm die Schreibposition falsch berechnet. Der String landet dann irgendwo und die Datei ist im Eimer (Abbildung 2).
Ursachen
Fehler durch Eingaben haben immer dieselbe Ursache: Ein Programm akzeptiert Daten, mit denen es nicht umzugehen weiß. Es genügt, wenn ein einzelner Wert nicht in den gewünschten Wertebereich passt. Patch-fstring findet zum Beispiel nichts Anrüchiges an der unsinnigen Blockgröße -23. Oder eine Kombination von Eingabedaten sprengt den erlaubten Rahmen, etwa eine Datumsangabe wie 29.2.2007. Für sich genommen sind alle drei Werte (29, 2 und 2007) erlaubt, nur ist 2007 kein Schaltjahr.
Ursachen sind Faulheit, Naivität, Zeitmangel oder fehlende Übersicht über die Zusammenhänge. Der verführerische Gedanke “Da muss der Benutzer eben aufpassen” erspart dem Entwickler zwar viel Aufwand. Dummerweise überlässt er damit die Sicherheit leichtfertig dem Anwender. Der vertippt sich aber gelegentlich, versteht die Anleitung nicht oder gehört gar zu den bösen Buben. Oder er zeigt das Programm dem Kollegen aus der Nachbarabteilung, der es zum frei zugänglichen CGI-Skript umfunktioniert – nicht ahnend, welche Lücke er damit aufreißt.
Eingabe-Knigge
Solchen Ärger vermeidet der Entwickler, wenn er konsequent einige einfache Regeln einhält:
- Alle Eingaben unter Sicherheitsaspekten sorgfältig
prüfen. - Zusammenhänge zwischen den Daten validieren.
- Eingaben gelten immer bis zum Beweis des Gegenteils als
schuldig. Lieber sinnvolle Daten zurückweisen als falsche
akzeptieren (so genanntes Whitelisting). - Nicht nur die Eingabekanäle prüfen, sondern auch in
den tieferen Schichten der Applikation testen (Defense in Depth,
Abbildung 3). - Auch Ausgaben sorgfältig erzeugen, sie dienen oft als
Eingaben nachgeschalteter Programme oder Skripte.
Schwarze und weiße Listen
Was in der Theorie so einfach klingt, ist in der Praxis verflixt schwer durchzuhalten. Die zwei bekanntesten Ansätze zur Datenvalidierung heißen Whitelisting und Blacklisting. Beim Whitelisting sind alle Daten so lange ungültig, bis sie das Programm auf bestimmte bekannte Muster prüft und akzeptiert.
Blacklisting funktioniert genau umgekehrt. Hier ist alles per Definition gültig, außer es steht auf einer scharzen Liste ungültiger Daten. Dummerweise funktioniert Blacklisting in der Regel nicht zuverlässig, wie das folgende Beispiel verdeutlicht.
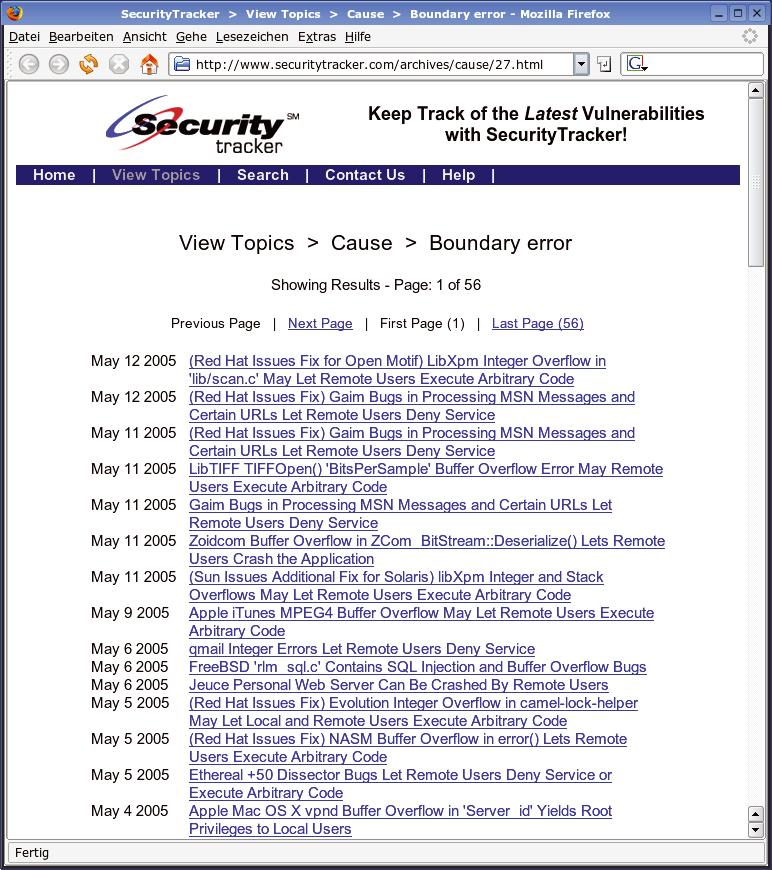
Abbildung 1: Die Kategorie “Boundary Errors” auf der Sicherheits-Webseite Securitytracker. Die Bugs in dieser Klasse sind meist auf Fehler bei der Eingabebehandlung zurückzuführen.
Ein Programm nimmt vom Benutzer einen Dateinamen an, den es mit dem Aufruf »system(“ls Dateiname”)« an eine Shell weiterreicht. Nun möchte der Entwickler sicherlich nicht Dateinamen wie »foo; rm -rf /« erlauben, denn damit würde sein Programm das Skript »ls foo; rm -rf /« ausführen und munter zu löschen beginnen.
Verbotene Zeichen
Blacklisting müsste sämtliche Zeichen verbieten, denen die Shell eine Sonderbedeutungen zuweist. Allerdings kann kaum jemand alle Metazeichen der Bourne Shell aufzählen. Zu allem Überfluss gibt es auch keine Garantie, dass auf einem System wirklich die Bourne Shell läuft und keine andere und auch keine neue Version, die wieder neue Sonderzeichen kennt. Blacklisting zwingt den Programmierer – oft mit enormem Aufwand – alle Nuancen eines Formats zu lernen.
|
Listing 1: Files patchen |
|---|
01 #include <stdio.h>
02 #include <stdlib.h>
03
04 int main(int argc, char **argv) {
05 off_t pos;
06 FILE *f;
07 /* Eingaben */
08 char *filename = argv[1];
09 int blkgroesse = atoi(argv[2]);
10 unsigned int blknummer = atoi(argv[3]);
11 char *string = argv[4];
12
13 f = fopen(filename, "r+");
14 if (f == NULL)
15 return 1;
16 /* An Schreibposition spulen */
17 pos = blkgroesse * blknummer;
18 pos = fseek(f, pos, SEEK_SET);
19 if (pos == (off_t)-1)
20 return 1;
21 fprintf(f, string); /* schreiben */
22
23 return 0;
24 }
|
Beim Whitelisting definiert der Entwickler den erlaubten Zeichensatz, zum Beispiel alle Buchstaben, Ziffern und einige harmlose Sonderzeichen. Damit weist er zwar auch viele unkritische Namen zurück, ist aber ziemlich sicher, dass er sich auch in Zukunft nichts einfängt.
Falle 1: Sonderzeichen
Zeichen mit Sonderbedeutung kennt nicht nur die Shell, sie sind in vielen Programmen und Protokollen wichtig, etwa bei E-Mail-Adressen, SQL-Befehlen oder Dateipfaden. Dabei ist grob zu unterscheiden zwischen Daten, die das Programm selbst verwendet, und solchen, die es an einen anderen Prozess weiterreicht.
Zur zweiten Klasse zählt das Beispiel eines Webhosters, dessen Kunden über ihren Browser bestimmte Zeilen aus einer SQL-Datenbank abrufen dürfen. Sie geben dazu eine Kundennummer ein. Das Backend packt den Namen in eine SQL-Abfrage:
SELECT * FROM opentab WHERE kd_nr="Kundennummer";
Angreifer Benny gibt nun als Kundennummer »1″; SELECT * FROM *; … “1« ein. Die SQL-Datenbank erhält dann folgenden zusammengesetzten Befehl:
SELECT * FROM opentab WHERE kd_nr="1"; SELECT * FROM *; ... "1";
Fröhlich schickt das Programm die gesamte Datenbank an Benny.
|
Listing 2: |
|---|
01 #include "fileguardian.c"
02 int main(int argc, char **argv) {
03 return !fileg_is_absolute_path(argv[1]);
04 }
|
Stammen wie im Beispiel Daten vom Benutzer oder aus einer anderen externen Quelle sind – wenig überraschend – Sicherungsmaßnahmen angeraten. In einfachen Fällen kann der Entwickler die Daten quoten, bevor er sie an die jeweilige nachgeschaltete Instanz weitergibt.
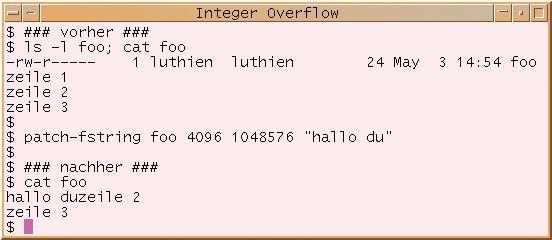
Abbildung 2: Das Ergebnis des Integerüberlaufs in Listing 1. Aus 4096 mal 1048576 Blocks errechnet sich ein Offset von genau 4 GByte. Diese Zahl ist zu groß für den Typ »off_t«. Die höherwertigen Bits gehen verloren, 0 bleibt übrig und das Patchprogramm überschreibt den Dateibeginn.
Da alle Sonderzeichen in den SQL-Standards gut dokumentiert sind, ist das Problem hier lösbar. Aber es bleibt das Risiko, etwas zu übersehen. Das Quoting widerspricht der goldenen Whitelisting-Regel: Jede Eingabe ist bis zum Beweis des Gegenteils schuldig.
Am besten ist es, der Entwickler verzichtet möglichst konsequent darauf, externe Eingaben in Interpretern zu verarbeiten oder sie an solche durchzureichen. Wo das nicht gelingt, filtert er die Daten (siehe die folgenden Abschnitte) und quotet das Ergebnis. Dabei helfen ihm Bibliotheken, die geeignete Quoting-Mechanismen bereitstellen.
Lösung für die Shell: Wenn der Entwickler unbedingt Eingaben weiterreichen muss, dann nicht, indem er ein Aufrufskript aus den Eingaben selbst erzeugt. Genau das passiert aber bei der C-Funktion »system()«:
/* input: Dateiname aus der Eingabe */ sprintf(cmd, "/bin/ls "%s"", input); system(cmd);
Achtung: Bei diesem einfachen Beispiel droht zusätzlich ein Buffer Overflow, wenn »cmd« zu klein für »input« ist. Es zeigt aber das Grundprinzip: Trotz des vermeintlichen Quoting mit »”« schmuggelt Benny problemlos Befehle ein, etwa mit der Eingabe »/tmp”;rm -rf /;echo “«. Im Ergebnis führt die Shell (»system()« startet immer eine Shell) das Skript »/bin/ls “/tmp”; rm -rf *; echo “”« aus. Es ist besser, die Eingaben in Umgebungsvariablen zu schreiben (und wieder droht der Buffer Overflow):
sprintf(var, "INPUT=%s", input);
system("/bin/ls "$INPUT"");
Die Shell kümmert sich dann selbst um das Quoting. Die Gefahr ist also entschärft – vorausgesetzt die Variable steht in doppelten Anführungszeichen. Ob »/bin/ls« die Eingabe korrekt verarbeitet, steht wieder auf einem anderen Blatt. Detaillierte Informationen zu SQL-Injection, Shell-Command-Injection, Crosssite-Skripting und deren Vermeidung finden sich in [3] und [4]. Der Code in [4] enthält leider einige Fehler; der Autor dieses Artikels stellt auf [5] eine korrigierte Fassung bereit.
|
Listing 3: Files patchen |
|---|
01 #include <limits.h>
02 #include <stdio.h>
03 #include <stdlib.h>
04
05 int main(int argc, char **argv) {
06 volatile off_t pos;
07 FILE *f;
08 unsigned long blkgroesse;
09 unsigned long blknummer;
10
11 /* Argumente prüfen */
12 if (argc < 5)
13 return 1; /* zu wenig Argumente */
14 blkgroesse = strtoul(argv[2], 0, 0);
15 if (blkgroesse == ULONG_MAX)
16 return 1; /* ungueltiger Wert */
17 blknummer = strtoul(argv[3], 0, 0);
18 if (blknummer == ULONG_MAX)
19 return 1; /* ungültiger Wert */
20 /* öffnen */
21 f = fopen(argv[1], "r+");
22 if (f == NULL)
23 return 1;
24 /* An Schreibposition spulen */
25 pos = (off_t)(blkgroesse * blknummer);
26 if (blkgroesse != 0 && pos / blkgroesse != blknummer)
27 return 1; /* Integerüberlauf */
28 pos = fseek(f, pos, SEEK_SET);
29 if (pos == (off_t)-1)
30 return 1;
31 fprintf(f, "%s", argv[4]); /* schreiben */
32 return 0;
33 }
|
Syntaktische Filter
Meist ist es sicherer, die Daten anhand einer weißen oder wenigstens einer schwarzen Liste zu filtern statt nur zu quoten. Im günstigsten Fall genügt es, eine Teilmenge des Ascii-Zeichensatzes zuzulassen. So erlaubt Unix in Pfadnamen alle Zeichen außer Null-Byte und Schrägstrich »/«. Damit steht die minimale schwarze Liste fest. Dieser Filter könnte auch syntaktischer Filter heißen, da er nur Datensätze abweist, deren Syntax inkorrekt ist.
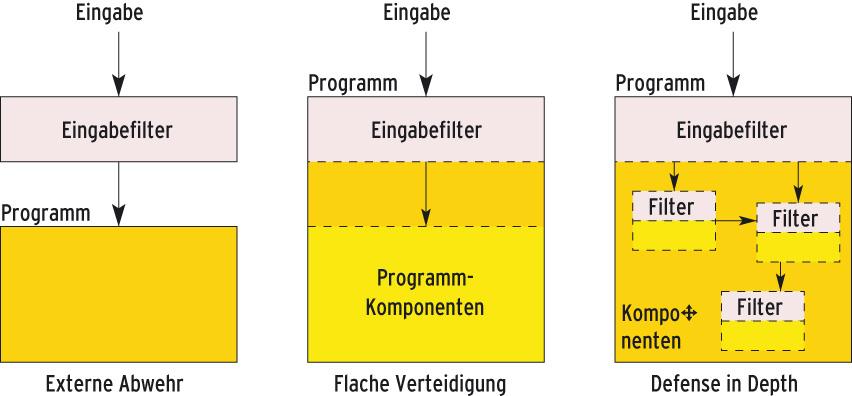
Abbildung 3: Links: Der Aufrufer ist für korrekte Eingaben verantwortlich, das Programm akzeptiert alles. Mitte: Ein Filter prüft Eingaben nur beim Betreten des Programms. Rechts: Jede Programmkomponente testet ihre Eingaben und erkennt Abweichungen, selbst wenn sich die äußere Verteidigungslinie als löchrig erweist.
In der Whitelisting-Variante genügt es, nur Buchstaben, Zahlen, das Minuszeichen »-«, den Unterstrich »_« und den Punkt ».« zuzulassen. Auf dem System des Autors deckt das bereits 98 Prozent aller Dateinamen ab, die übrigen zwei Prozent enthalten eines der Zeichen »~,+:=%#$()«. Vermutlich sind auch diese Kombinationen harmlos. Da die Shell und andere Programme diesen Zeichen eine besondere Bedeutung geben, lässt sie ein vorsichtiger Entwickler jedoch lieber weg.
Semantische Filter
Eine andere Filtertechnik untersucht auch die Semantik der Eingaben. Bei Pfaden besitzen manche Zeichenfolgen eine besondere Bedeutung. Ein einzelner Punkt ».« zeigt an, dass die Suche im aktuellen Verzeichnis beginnt, der zweifache Punkt »..« wechselt ins Mutterverzeichnis. Je nach Aufgabe bietet es sich an, alle relativen Pfade, nur die relativen Pfade mit »..« oder generell alle Pfade zu verbieten und nur einfache Dateinamen zuzulassen. Die richtige Filterstrategie hängt immer von der konkreten Aufgabe und den verwendeten Formaten ab (siehe [3] und [4]).
Lösung für C und C++: Eine Minifunktion sorgt für syntaktisches Filtern von Dateinamen mit Hilfe einer schwarzen Liste:
int is_subset(char *s, char *ch)
{
for (; *s && !strchr(ch, *s);
s++) ;
return (*s == 0);
}
if (is_subset(Pfad, "abc..90_-"))
exit(1);
Für den beschriebenen semantischen Filter stellt Gateguardian [6] das nötige Rüstzeug bereit. Die folgenden Funktionen liefern die gewünschte Information:
- fileg_is_absolute_path()
- fileg_is_relative_path()
- fileg_is_local_relative_path()
- fileg_is_path()
- fileg_is_filename()
Um nur Pfade zuzulassen, die im oder unter dem aktuellen Verzeichnis liegen, reicht:
if (! fileg_is_local_relative_path(Pfad)) exit(1);
Lösung für die Shell: Am besten die Gateguardian-Funktionen in ein kleines C-Programm packen (siehe Listing 2) und dann mit »is-absolute-path “Pfad” || exit 1« den Pfad in der Shell überprüfen.
Falle 2: Zahlen einlesen
Ärger mit Zeichen, Ziffern und deren Bedeutung bereiten auch die primitiven Datentypen von C und C++. In diesem Zoo tummeln sich als kleinste Bewohner ganze Zahlen und Fließkommawerte in verschiedenen Größen und Genauigkeiten (»short«, »int«, »long« …) mit oder ohne Vorzeichen. Ein besonders exotischer Typ ist das Chamäleon »char«. Je nach Compiler besitzt es per Default ein Vorzeichen oder auch nicht.
Aber auch bei Integer, Short & Co. ist nicht alles klar und eindeutig – je nach Compiler und Prozessor fallen sie unterschiedlich groß aus. Fest steht lediglich, dass ein Long nie kürzer als ein Integer ist und ein Integer mindestens so groß wie ein Short.
Der Pfleger in Gestalt des Entwicklers sorgt für die angemessene Unterkunft seiner Schützlinge. Er vermeidet Verstümmelungen, etwa wenn sich ein 32-Bit-Integer in einen 16-Bit-Short-Käfig zwängt, indem er für ausreichend Platz sorgt oder vorher prüft, ob der Große in den kleinen Raum passt.
Wenn er sich der Daten annimmt, ahnt er allerdings in vielen Fällen gar nicht, worauf er sich genau einlässt. Eingabewerte liegen sehr oft in von Menschen lesbarer Form vor und sind damit interpretationsbedürftig. Sie stammen aus der Kommandozeile, aus Eingabefeldern oder Datenströmen.
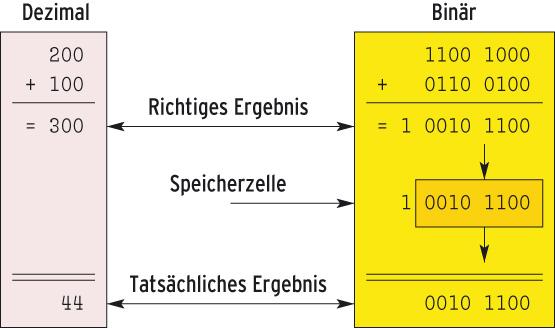
Abbildung 4: Das Programm addiert zwei Werte mit begrenzter Länge (8 Bit). Das Resultat benötigt 9 Bit, es landet aber in einer 8-Bit-Speicherzelle. Dabei geht das oberste Bit verloren, ein Integerüberlauf ist aufgetreten.
Bei »patch-fstring« aus Listing 1 verwandelt die Funktion »atoi()« Texteingaben in Integerwerte (Ascii to Integer). Sie versteht zwar das Vorzeichen, aber sie schneidet zu große Binärzahlen einfach ab – ohne jede Fehlermeldung. So wird beispielsweise aus der Dezimalzahl 3000111222 plötzlich 2147483647. Klüger sind die Funktionen »strtol()« (String to Long) und »strtoul()« (String to Unsigned Long). Sie leisten mehr und signalisieren Fehlerbedingungen – wenn auch nur notdürftig über den Rückgabewert und die globale »errno«-Variable.
|
Listing 4: Integer mit |
|---|
01 #include "inputguardian.c"
02
03 int main(int argc, const char **argv) {
04 const char *end;
05 char c;
06 int i;
07
08 if (inputg_parse_i("999 -77", &end, &i))
09 return 1; /* Fehler */
10 if (inputg_parse_c(end, &end, &c))
11 return 1; /* Fehler */
12 /* ... */
13
14 return 0;
15 }
|
Fehler versteckt
Der Rückgabewert lautet »LONG_MAX« oder »ULONG_MAX« bei Werteüberlauf und »LONG_MIN« bei einem Unterlauf. Einen zusätzlichen Hinweis auf Fehler geben die beiden Pointer »**endptr« und »*nptr«. Die Strtol-Funktion hat nur dann korrekt gearbeitet, wenn folgende zwei Bedingungen zutreffen:
- Das Resultat ist weder »LONG_MAX« noch
»LONG_MIN« (alternativ auf »errno !=
ERANGE« prüfen). - Es gilt »*endptr > nptr«.
Damit machen auch diese Funktionen dem Programmierer das Leben unnötig schwer. Es sollte einfacher sein, einen Fehler in einer Funktion zu bemerken. Zudem sind sie nicht ausreichend portabel, zum Beispiel sperrt sich bei »strtoll()« der Datentyp »long long«; trotz dieses Sondertyps kennt die Funktionsfamilie nicht einmal alle standardisierten Integertypen.
Dämlich verhalten sich auch weitere Implementierungen, etwa die »scanf()«-Funktionsfamilie, der »>>«-Operator in C++ oder die arithmetische Substitution in gängigen Shells mit »$[…]«. Sie schneiden überzähligen Bits einfach ab und liefern kommentarlos Müll. Die Bash hat auf dem System des Autors eine recht eigenwillige Auffassung von der Multiplikation: »echo $[100000 * 100000]« beantwortet sie mit 1410065408. Je nach Bash-Version und Linux-System sind mehr Nullen nötig, um den Überlauf zu provozieren.
Lösung für die Shell: Die Eingabe (etwa »$1«) in einer Variablen speichern und ihren Textinhalt mit der numerischen Interpretation vergleichen. (Warum Shellvariablen grundsätzlich in Anführungszeichen gehören, erläuterte der zweite Teil dieser Serie [2]):
IN="$1" test x"$IN" = x$[IN] || exit 1 # Fehler
Lösung für C und C++: Genügt für das Programm ein Wertebereich ohne die Grenzwerte »ULONG_MAX«, »LONG_MAX« und »LONG_MIN« aus »limits.h«, darf es »strtol()« und »strtoul()« einsetzen. In Listing 3 ist eine korrigierte Version des Programms aus Listing 1 zu sehen. Die Zeilen 15 und 17 prüfen den Rückgabewert auf Spuren eines Überlaufs – gibt der Anwender einen zu großen Wert ein, bricht das Programm mit dem Fehlerwert »1« ab.
Inputguardian
Reichen diese Tests nicht oder fehlt die Strto-Familie auf dem Zielsystem, helfen nur noch Selbermachen oder Gateguardian [6]. In Version 0.9.4 ist das Modul Inputguardian hinzugekommen, das Funktionen zur Eingabekontrolle mitbringt: »inputg_parse_Typ«. Hinter Typ verbirgt sich eine Abkürzung des Datentyps, zum Beispiel »ui« für »unsigned int«. Der Admin hat die Wahl, entweder gegen Libgateguardian zu linken oder die Quellen mit der Include-Präprozessoranweisung einzubinden (Zeile 1 in Listing 4).
Jede Funktion der Inputg_parse-Familie braucht drei Argumente: Den zu bearbeitenden String (»”999 -77″« in Zeile 8), einen Zeiger (»&end«), über den sie die nächste zu verarbeitende Position im String zurückliefert, sowie einen Zeiger auf die Variable, in der sie den Wert ablegt (»&i« in Zeile 8 und »&c« in Zeile 10). Der Rückgabewert »0« signalisiert, dass Inputguardian die Eingabe erfolgreich lesen konnte, »-1« dagegen einen Fehler.
Falle 3: Wertebereich
Meist erwarten Programme ihre Eingaben innerhalb bestimmter Grenzen, außerhalb derer es nicht richtig arbeitet und sinnlose Ergebnisse liefert. Zum Beispiel sind Zahlen vielleicht zu groß oder zu klein, Strings zu lang oder zu kurz. Wie auch immer die Eingaben aussehen, defensives Programmieren lohnt sich. Lieber einmal zu viel einen Wert überprüfen als einmal zu wenig.
Lösung für die Shell: Die Länge einer Zeichenkette in der Variablen »STR« lässt sich mit »${#STR}« ermitteln und damit begrenzen – ganz wie es bei Zahlenwerten üblich ist:
LEN="${#STR}"
test "$LEN" -gt Maximum && exit 1
test "$LEN" -lt Minimum && exit 1
Lösung für C und C++: Die Strategie ist dieselbe wie bei der Shell. Für Zahlen genügt ein einfacher Vergleich. Bei Zeichenketten in C vom Typ »char *« ermittelt »strlen(String)« die Länge, in C++ ist die Methode »String.size()« zuständig:
if (wert < Minimum || wert > Maximum) exit(1); /* Fehler */ size_t len = strlen(str); /* oder: */ std::string::size_type len = str.size(); if (len < Minimum || len > Maximum) exit(1); /* Fehler */
Vorsicht: Die eingebaute automatische Typkonvertierung in C wandelt bei Vergleichen von Zahlen beide Seiten – falls nötig – in kompatible Typen um. Zum Beispiel mutiert bei »int i; unsigned int u;« im Vergleich »if (i < u)« die Variable »i« in einen vorzeichenlosen Typ. Das beschädigt ihren Wert.
In C++ gibt es solche Vorgänge zwar auch, aber der Übersetzer warnt davor. Diese Hinweise sind ernst zu nehmen, sie deuten fast immer auf einen Bug hin. Eine spätere Folge befasst sich näher mit dieser Problematik; fürs Erste genügt der Rat, immer nur Zahlen vom gleichen Typ miteinander zu vergleichen.
Falle 4: Rechenfehler
Der bereits erwähnte Überlauf von Integervariablen (etwa »blkgroesse« und »blknummer« in Listing 1) tritt im Zusammenhang mit Eingaben schnell auf, wenn das Programm mehrere Werte addiert oder multipliziert. Bei positiven Zahlen ist das Ergebnis von Addition und Multiplikation immer größer als beide verrechneten Zahlen. Passt das Rechenergebnis nicht mehr in den verwendeten Datentyp, spricht man von einem Integerüberlauf. Das Programm schneidet die überzähligen Bits einfach ab (Abbildung 4).
Lösung für die Shell: Bei jeder Addition und Subtraktion mit positiven Zahlen das Ergebnis prüfen. Nach einem Überlauf ist das Ergebnis einer Addition kleiner als beide Operanden, bei der Subtraktion größer als der linke Operand. Bei negativen Zahlen dreht sich die Logik um, also größer (»-gt«) statt kleiner (»-lt«) und umgekehrt:
test $[A + B] -lt "$A" && exit 1 test $[A - B] -gt "$A" && exit 1
Lösung für C und C++: Da es hier um reine Rechenoperationen geht, ist nur die Syntax anders, das Prinzip bleibt:
if (a+b < a) exit(1); if (a-b > a) exit(1);
Bei Multiplikationen fällt der Vergleich aufwändiger aus, da der Wertebereich des Ergebnisses nicht feststeht. Hier hilft es, das Ergebnis mit einer Division zu kontrollieren. Allerdings ist dazu eine temporäre Variable mit dem richtigen Typ erforderlich:
int a, b; volatile int p = a*b; if (a != 0 && p/a != b) exit(1);
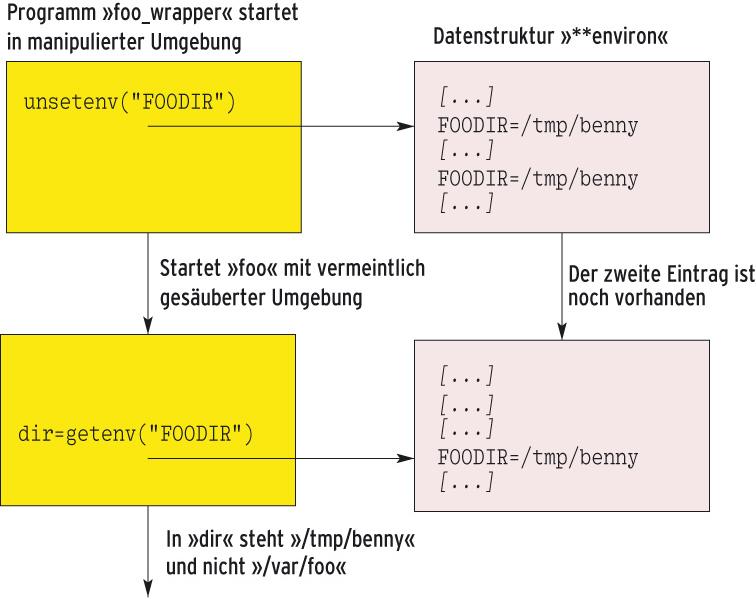
Abbildung 5: Weil ein Angreifer die Variable »FOODIR« doppelt in der Umgebung abgelegt hat, lässt der »unsetenv()«-Aufruf in »foo_wrapper« (Listing 5b) eine Kopie übrig. Das »foo«-Programm (Listing 5a) sieht genau diese und verhält sich anders, als »foo_wrapper« erwartet.
Es gibt außerdem einige trickreiche Testvarianten, die performanter arbeiten und mehr Fälle abdecken. Eine spätere Folge des Workshops wird das Thema Rechenfehler mit Integertypen noch genauer betrachten.
|
Listing 5a: Fehlerhaftes |
|---|
01 #include <stdlib.h>
02 #include <unistd.h>
03
04 int main(void) {
05 char *dir;
06
07 dir = getenv("FOODIR");
08 if (dir != 0)
09 dir = dir + strlen("FOODIR=");
10 else
11 dir = "/var/foo";
12 if (chdir(dir) != 0)
13 exit(1);
14 /* ... */
15
16 return 0;
17 }
|
|
Listing 5b: Fehlerhafter |
|---|
01 #include <stdlib.h>
02 #include <unistd.h>
03
04 int main(void) {
05 extern char **environ;
06
07 unsetenv("FOODIR");
08 /* ... */
09 execle("/usr/bin/foo", 0, environ);
10
11 return 1;
12 }
|
Falle 5: Umgebungsvariablen
Neben dem Interpretieren des Inhalts ist auch der Datenpfad, auf dem Eingaben das Programm betreten, mit Stolpersteinen gepflastert. Umgebungsvariablen sind ein beliebter, praktischer und leicht zu implementierender Weg. In C-Programmen stecken sie in einem Feld von Zeigern auf Strings. Der Zugriff erfolgt entweder über die globale Variable »char **environ« oder die beiden Funktionen »getenv()« und »putenv()«.
|
Listing 6: |
|---|
01 #include <stdlib.h>
02 #include <string.h>
03
04 int safe_putenv(char *string) {
05 int rc;
06 int offset;
07 char *name;
08 char *pos;
09 char *var;
10
11 name = strdup(string);
12 if (name == 0)
13 return -1;
14 rc = putenv(string);
15 if (rc != 0)
16 return rc;
17 /* Plausibilitätstests */
18 pos = strchr(name, '=');
19 if (pos == 0) {
20 free(name);
21 return -1;
22 }
23 offset = pos - name + 1;
24 *pos = 0;
25 var = getenv(name) - offset;
26 rc = (var == string) ? 0 : -1;
27 free(name);
28
29 return rc;
30 }
31
32 void safe_unsetenv(const char *name) {
33 unsetenv(name);
34 if (getenv(name) != 0)
35 abort();
36
37 return;
38 }
|
Die Umgebungsvariablen liegen in den meisten Fällen als nullterminierte Zeichenketten der Form »Name=Wert« im Speicher. Mit der Funktion »execve()« kann ein Angreifer aber beliebige Strings wie etwa »Name«, »=xyz« oder nur ein einsames »=« setzen. Ein und dieselbe Variable lässt sich sogar mehrfach speichern. Wer »getenv()« und »putenv()« verwendet, muss sich um verstümmelte Strings nicht weiter sorgen, aber er fällt womöglich auf Duplikate herein.
Ein Beispiel: Das Programm »foo« erlaubt es, das Verzeichnis, in dem es seine Daten ablegt, über die Umgebungsvariable »FOODIR« zu ändern (Listing 5a, Zeilen 7 bis 9). Anke will Foo aus ihrem Programm »foo-wrapper« heraus aufrufen, um vorher mit »unsetenv()« die Variable »FOODIR« zu löschen (Listing 5b, Zeile 7). Damit soll Foo bei seinen Standardeinstellung bleiben. Dem Spitzbuben Benny ist es gelungen, Anke eine Umgebung unterzuschieben, die die Variable »FOODIR« doppelt enthält (jeweils als »FOODIR=/tmp/benny”«). Unsetenv löscht nur eine Kopie der Variablen – die andere überlebt. Foo arbeitet folglich im falschen Verzeichnis (Abbildung 5).
Lösung für C und C++: Die Hilfsfunktionen »safe_unsetenv()« und »safe_putenv()« aus Listing 6 prüfen nach dem Aufruf von Unsetenv oder Putenv, ob das Resultat den Erwartungen entspricht. Statt Unsetenv und Putenv besser die Safe-Ausführungen verwenden.
Fazit
Mit den bisherigen Ausführungen ist das Thema Programmeingaben noch nicht annähernd ausgeschöpft. Offen ist zum Beispiel die Verwundbarkeit gegen Formatstring-Angriffe aus Listing 1. Um diese und andere Fragen zu Ein- und Ausgabe kümmert sich die nächste Folge des Workshops. (fjl)
|
Infos |
|---|
|
[1] Dominik Vogt, “Umweltverschmutzung – Sicheres Programmieren für Administratoren, Folge 1”: Linux-Magazin 02/05, S. 54 [2] Dominik Vogt, “Wurzelbehandlung – Sicheres Programmieren für Administratoren, Folge 2”: Linux-Magazin 04/05, S. 64 [3] Sverre H. Huseby, “Sicherheitsrisiko Web-Anwendung”: Dpunkt-Verlag, ISBN 3-89864-259-3 [4] Viega, Messier, “Secure Programming Cookbook”: O\’Reilly, ISBN 0-596-00394-3, [http://www.secureprogramming.com] [5] Dominik Vogt, Korrekturen zum Secure Programming Cookbook: [http://www.dominikvogt.de/de/index.html#Links] [6] Dominik Vogt, Gateguardian: [http://sourceforge.net/projects/gateguardian/] [7] Achim Leitner, “Kein Format – Sicherheitslücken durch den Format-String”, Linux-Magazin 08/01, S. 96 [8] Securitytracker-Kategorie “Boundary Errors”: [http://www.securitytracker.com/archives/cause/27.html] |
|
Der Autor |
|---|
|
Dipl.-Math. Dominik Vogt ist langjähriger Software-Entwickler und Systemadministrator. Zurzeit arbeitet er als freiberuflicher EDV-Berater mit dem Schwerpunkt Softwaresicherheit. In seiner Freizeit werkelt er gerne an dem Windowmanager Fvwm. |






