
In diesen Tagen erschien PostgreSQL 8. Die Datenbank mit dem Elefanten-Maskottchen empfiehlt sich mit zahlreichen neuen Features, darunter Tablespaces, Point-in-Time-Recovery und Savepoints. Weiter ausgebaut haben die Entwickler auch die Programmiermöglichkeit von Serverfunktionen.
Auch unter den freien Datenbanken belebt Konkurrenz das Geschäft: Seit mehr als einem Jahr ist die ehemalige SAP DB als freie Max DB aus dem Hause MySQL zu haben, im August letzten Jahres stellten fast gleichzeitig IBM und Computer Associates ihre Produkte Cloudscape und Ingres unter eine Open-Source-Lizenz. Gegen diese ehemals kommerzielle Konkurrenz müssen sich die alteingesessenen Open-Source-Datenbanken behaupten.
Wie das gelingt, demonstriert PostgreSQL mit der eben erschienenen Release 8. Zwei der zahlreichen Neuerungen fallen dem erfahrenen Datenbank-Administrator sofort auf, bescheren sie PostgreSQL doch Features, die sie bisher vor allem von Highend-Produkten kannten: Tablespaces für das Positionieren von Datenbankobjekten und ein lückenloses Recovery-Konzept.
Datenbanken halten Festplatten auf Trab. Deshalb ist es ein bewährter Kniff, die häufigen Schreib- und Lese-Zugriffe konkurrierender Operationen auf möglichst viele Platten zu verteilen. Zusätzliche Disks helfen außerdem dabei, Platzmangel auszugleichen.
Divide et impera
Beides war mit PostgreSQL nicht leicht zu bewerkstelligen, denn es gab nur ein zentrales Verzeichnis für Daten. Anderswo verfügbare Speicherkapazität war nicht nutzbar. In der neuen Version kann der Administrator nun auf Table- spaces zurückgreifen. Sie fungieren als Container für Datenbankobjekte, die sich in beliebiger Anzahl an beliebigen Speicherorten verankern lassen. Der Admin kann damit sowohl die I/O-Last verteilen als auch den verfügbaren Platz besser ausnutzen.
Neben kompletten Datenbanken lassen sich bei Bedarf auch nur Schemata, Tabellen oder einzelne Indizes platzieren. Besonders Performance-fördernd wirkt die Verteilung von Tabelle und zughörigem Index auf verschiedene Festplatten. Dadurch müssen die Schreib-Lese-Köpfe weniger springen und bewegen sich stattdessen zeitsparend von Sektor zu Sektor. Wenn man Tabellen, die oft mit Joins verknüpft sind, auf verschiedene Platten legt, ist ein ähnlicher Effekt zu erzielen.
Das funktioniert besonders gut, wenn eine große Anzahl von Zeilen zurückgeliefert wird. In diesem Fall erkennt der Planer in PostgreSQL, dass ein Indexscan langsamer als das sequenzielle Lesen wäre. (»EXPLAIN« oder »EXPLAIN ANALYZE« offenbaren die Kostenrechnung des Planers). Sind die Speicherorte der logisch verbundenen Tabellen physisch getrennt, behindern sich die parallelen Leseoperationen nicht gegenseitig und können dadurch den maximalen Durchsatz liefern.
Wer Tablespaces von anderen Datenbanken (wie etwa Oracle) kennt, dem wird auffallen, dass es in PostgreSQL keinen Parameter gibt, der ihre Größe festlegt. Die Datenbank weist ihnen stattdessen lediglich einen Pfad zu. So belegen sie nur den Speicherplatz, der tatsächlich auch verwendet wird.
Einen neuen Tablespace kreiert der Administrator mit dem SQL-Befehl:
CREATE TABLESPACE Tablespacename [ OWNER Username ] LOCATION Directory
Eine neue Datenbank, ein Schema, eine Tabelle oder einen Index kann er anschließend in dem so erzeugten Container platzieren. Zum Beispiel:
CREATE TABLE test (a INT, b INT) TABLESPACE hd_master;
Wie jede Bank sichern auch Datenbanken ihre Einlagen möglichst wirkungsvoll gegen Verlust. Die meisten verwenden eine mehrstufige Strategie: Regelmäßige Backups retten den kompletten Datenbestand auf sichere Medien. Von dort kann er – etwa nach einen Systemausfall – komplett wiederhergestellt werden. So genannte Transaktionslogfiles (siehe Kasten “Transaktionslogfiles”) verzeichnen zusätzlich alle Änderungen an den Datendateien. Dadurch lassen sich unvollendet abgebrochene oder fehlerhafte Operationen wieder rückgängig machen (Rollback) .
|
Transaktionslogfiles |
|---|
|
Das Transaktionslogfile einer Datenbank funktioniert ähnlich dem Journal eines Journaling-Dateisystems. In dem Log werden alle geplanten Änderungen an Daten (Tabellen, Indizes und so weiter) vermerkt. In kurzen Abständen werden sie dann von dort aus auf den Datenbestand übertragen. Stürzt der Rechner während eines solchen Schreibprozesses ab, lässt sich anhand des Transaktionslogfile festgestellen, welche Änderungen bereits vollzogen wurden und welche noch ausstehen. Diese Information ermöglicht es, die Transaktion entweder zu komplettieren oder zurückzunehmen. In jedem Fall bleibt die Konsistenz der Daten gewahrt. Als weiterer Vorteil ergibt sich eine Steigerung der Geschwindigkeit, denn es ist einfacher, sequenziell Daten an das Transaktionslogfile anzuhängen als den Festplattenkopf ständig auf die richtigen Stellen in den Datendateien zu positionieren. Außerdem können diese Files auch auf einer zweiten Festplatte liegen. Vor PostgreSQL 8.0 wurden die Transaktionslogfiles nach einiger Zeit wieder überschrieben. Nun kann man sie archivieren und auf diese Weise nicht nur ein paar Transaktionen daraus komplettieren, sondern auch all jene noch einmal durchführen, die bis zu einem gewünschten Zeitpunkt stattgefunden haben (Point-in-Time-Recovery). |
Einlagensicherung
Ohne besondere Vorkehrungen würden die Transaktionslogs unaufhörlich wachsen, wodurch irgendwann das Filesystem überliefe. Dem beugen Datenbanken in der Regel mit einem Rotationsverfahren vor: Neue Einträge überschreiben früher oder später ältere. Das begrenzt den benötigten Platz, aber auch die in den Logs dokumentierte Änderungs-Historie. Reicht sie nicht mehr bis zum letzten Backup zurück, entsteht eine Lücke im Sicherheitskonzept: Alle Daten, die zwischen der letzten Komplettsicherung und den ältesten erhaltenen Einträgen in den Logs geändert wurden, ließen sich nach einem totalen Datenverlust nicht mehr rekonstruieren.
PostgreSQL 8.0 begegnet dem durch ein Verfahren namens Point-in-Time-Recovery. Es sichert alle Logs, bevor sie überschrieben werden, und gewährleistet so, dass sich jeder Zustand der Datenbank seit dem Ende des letzten Backups wiederherstellen lässt. Auch Benutzerfehler sind damit mitversichert: Wer hat beim »DELETE« nicht schon mal das »WHERE« vergessen?
Das Recovery wird trotz des neuen Feature nicht komplizierter. Der Administrator spielt zuerst das letzte Voll-Backup des »data/«-Verzeichnisses sowie alle benutzten Tablespaces ein. Danach legt er im »data/«-Verzeichnis die Datei »recovery.conf« an, in der er angibt, wo sich die Transaktionslogfiles befinden und bis zu welchem Zeitpunkt die Wiederherstellung reichen soll. Ein Beispiel kann so aussehen:
restore_command ='cp /var/lib/pgsql/archive/%f %p' recovery_target_time ='2004-11-24 15:15:00.0000'
Als Ziel-Zeitpunkt für das Wiedereinspielen (Rollforward) kann er sowohl eine Transaktions-ID als auch – wie in dem Beispiel – einen bestimmten Zeitpunkt festlegen. Startet PostgreSQL und findet die beschriebene Datei, wechselt es in den Recovery-Modus, stellt die Datenbank wieder her und benennt die Steuerdatei von »recovery.conf« in »recovery.done« um. Einen Auszug der Meldungen eines solchen Recovery-Vorgangs zeigt Listing 1.
|
Listing 1: |
|---|
01 LOG: starte Wiederherstellung aus Archiv 02 LOG: restore_command = »cp /var/lib/pgsql/archive/%f %p« 03 LOG: recovery_target_time = 2004-11-24 15:15:00+01 04 LOG: Logdatei »000000010000000000000007.00EB5DD4.backup« aus Archiv 05 wiederhergestellt 06 LOG: Logdatei »000000010000000000000007« aus Archiv wiederhergestellt 07 LOG: Checkpoint-Eintrag ist bei 0/7EB5DD4 08 LOG: Redo-Eintrag ist bei 0/7EB5DD4; Undo-Eintrag ist bei 0/0; Shutdown FALSE 09 LOG: nächste Transaktions-ID: 1827; nächste OID: 131918 10 LOG: automatische Wiederherstellung läuft 11 LOG: Redo beginnt bei 0/7EB5E10 12 LOG: Logdatei »000000010000000000000008« aus Archiv wiederhergestellt 13 LOG: Logdatei »000000010000000000000009« aus Archiv wiederhergestellt 14 LOG: Wiederherstellung beendet vor Commit der Transaktion 1921, Zeit 2004-11-24 15:15:08 CET 15 LOG: Redo fertig bei 0/9D980F4 16 LOG: gewählte neue Timeline-ID: 2 17 LOG: Wiederherstellung aus Archiv abgeschlossen 18 LOG: Datenbanksystem ist bereit |
Eine interessante neue Möglichkeit in PostgreSQL 8 betrifft ein Problem, das es bei einer Datenbank im Produktivbetrieb eigentlich gar nicht geben dürfte – wenn doch, ist es meist ein Indiz für Mängel beim Datenbank-Entwurf oder -Test: die nachträgliche Änderung von Spaltentypen in einer Tabelle.
Zahlendreher
Die bisherige Methode bestand darin, zunächst eine Spalte des neuen Typs anzulegen. In diese wurden dann die konvertierten Daten der zu ändernden Spalte kopiert. Anschließend löschte man die alte Spalte und gab der neuen den ursprünglichen Namen. Diese Handarbeit übernimmt die Datenbank nun über den Befehl »ALTER TABLE ALTER COLUMN … TYPE …[USING …]« selbst. Eine automatische Konvertierung kann das System aber nur dann vornehmen, wenn es den Ursprungstyp eindeutig auf den Zieltyp abbilden kann.
Für alle anderen Fälle bietet sich der USING-Parameter an. Hier definiert ein Ausdruck die Regeln der Konvertierung. Dieser ist sehr flexibel zu gestalten: Der Entwickler kann sowohl andere Spalten als auch vordefinierte oder selbst geschriebene Konvertierungsfunktionen einbeziehen. Abbildung 1 zeigt dafür ein Beispiel, das in einer Tabelle »history« die Einträge der Spalte »jahr« über eine durch den Benutzer definierte Funktion »convert_from_roman()« von der Darstellung mit römischen Zahlen in Dezimalzahlen konvertiert.
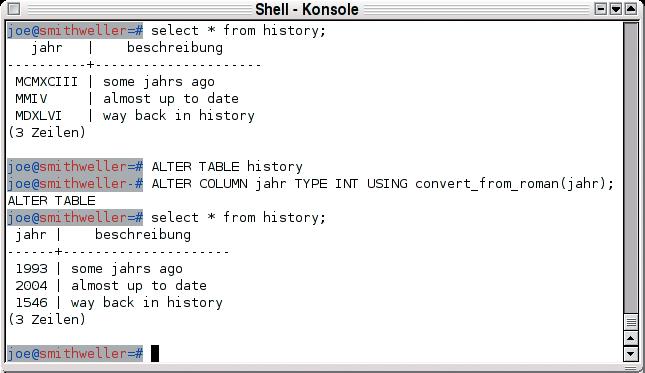
Abbildung 1: PostgreSQL 8.0 unterstützt das nachträgliche Ändern des Datentyps einer Spalte. In den älteren Versionen waren dafür mehrere Statements erforderlich.
Zustandskonserven
Auch für die Entwickler von Datenbankanwendungen ergeben sich mit der Version 8.0 viele neue Möglichkeiten. Sehr interessant dürfte beispielsweise die Unterstützung von Savepoints sein. Diese Erweiterung erlaubt es jetzt, innerhalb einer Transaktion weitere Unter-Transaktionen einzuführen.
Wenn die Datenbank auf die Definition »SAVEPOINT Name« stößt, merkt sie sich den zu diesem Zeitpunkt erreichten Zustand. Die darauf folgenden Operationen können später durch »ROLLBACK TO SAVEPOINT Name« innerhalb der Transaktion bis zu diesem eingefrorenen Zustand zurückgenommen werden. Wer einen Savepoint nicht mehr benötigt, gibt ihn durch »RELEASE SAVEPOINT Name« wieder frei. Folgendes Beispiel illustriert dieses Verfahren:
BEGIN TRANSACTION; INSERT INTO tabelle VALUES (1); SAVEPOINT sp; INSERT INTO tabelle VALUES (2); ROLLBACK TO SAVEPOINT sp; INSERT INTO tabelle VALUES (3); COMMIT;
Es fügt die Werte »1« bis »3« ein, der Befehl »ROLLBACK TO SAVEPOINT sp;« macht aber das Einfügen des Wertes »2« wieder rückgängig.
Besonders nützlich ist dieses Feature bei längeren Transaktionen. Bisher war es ja so, dass eine Transaktion komplett zurückgerollt werden musste, sobald ein in ihr enthaltener Befehl einen Fehler verursachte. Der Client musste sie dann im Zweifelsfall auch neu starten. Neuerdings kann er innerhalb einer Transaktion einfach zu sicheren Rücksprungspunkten zurückkehren.
Diese Möglichkeit haben die Entwickler auch in PL/PgSQL integriert, einer prozeduralen Sprache, die sich ungefähr mit “SQL plus Variablen und Programmlogik” umschreiben lässt. Der Name erinnert auch nicht zufällig an PL/SQL von Oracle. Aufgrund des Konzepts der Savepoints unterstützen PL/PgSQL-Funktionen auch Exceptions, mit denen ein Fehler in einer Funktion abgefangen und adäquat behandelt werden kann. In den Vorgängerversionen beendete ein Fehler in einer Funktion nicht nur die Funktion selbst, sondern auch die laufende Transaktion. Listing 2 zeigt das Gerüst einer PL/PgSQL-Funktion mit Exception-Handling.
|
Listing 2: |
|---|
01 CREATE FUNCTION exceptions_beispiel(int) RETURNS int AS $$
02 DECLARE
03 param ALIAS FOR $1;
04 BEGIN
05 BEGIN
06 INSERT INTO ... VALUES (...)
07 EXCEPTION
08 WHEN INTEGRITY_CONSTRAINT_VIOLATION THEN
09 -- Constraints wie z.B. UNIQUE/NOT NULL/CHECK...
-- oder ein Fremdschlüssel wurden verletzt.
10 ...
11 WHEN UNIQUE_VIOLATION OR FOREIGN_KEY_VIOLATION THEN
12 -- es ist auch eine genauere Aufschlüsselung möglich
13 ...
14 WHEN DIVISION_BY_ZERO THEN
15 -- auch solche Fehler können abgefangen werden
16 ...
17 WHEN OTHERS THEN
18 -- alle nicht explizit abgefangenen Fehler...
19 RAISE EXCEPTION 'Fehler in execptions_beispiel: %", param;
20 END;
21 RETURN 1;
22 END;
23 $$ LANGUAGE plpgsql;
|
Einfach komplex
Eine Stärke von PostgreSQL sind seit langem die in verschiedenen Sprachen frei programmierbaren Server-Funktionen. Neben SQL und PL/PgSQL kann der Entwickler dafür zwischen PL/Perl, PL/Python und PL/Tcl wählen. PL/Java, PL/R, PL/Ruby und PL/Sh sind zwar nicht in der Standarddistribution, aber auf[1],[2],[3] und[4] erhältlich. Auch eine Sprache PL/PHP befindet sich in der Entwicklung.
PL/Perl haben die PostgreSQL-Entwickler in der Version 8.0 um so genannte Set Returning Functions erweitert, also um Funktionen, die nicht nur eine, sondern mehrere Ergebniszeilen zurückliefern. Mit der ebenfalls neuen SPI-Unterstützung (Server Programming Interface) ist der Zugriff auf weitere Datenbankobjekte durch PL/Perl-Funktionen möglich. Außerdem sind jetzt auch Trigger in dieser Sprache definierbar.
Besonders für solche Funktionen ist die Möglichkeit interessant, komplexe (zusammengesetzte) Typen als Parameter entgegenzunehmen oder weiterzugeben. Die Version 8.0 unterstützt diese Datentypen an einigen Stellen, an denen bislang nur skalare Typen erlaubt waren. Dabei ermöglicht es der »row()«-Konstruktor, komplexe Typen aus einfachen zusammenzusetzen. So lassen sich zum Beispiel die drei skalaren Typen Integer, Text und Real mittels »row(3, \’PostgreSQL\’, 47.11)« in einem komplexen Wert zusammenfassen.
Das Beispiel in Listing 3 beschreibt den Umgang mit komplexen Typen in PL/Perl. Es definiert zunächst den Datentyp »adresse«, legt anschließend eine Tabelle mit diesem Datentyp an und fügt einen Wert in die Tabelle ein. Dieser Wert entspricht zwar der Typ-Definition, vermengt aber Städtenamen und Postleitzahl im Feld »stadt« und lässt das »plz«-Feld frei. Das Beispiel legt deshalb die Funktion »lies_plz()« an, die diesen Fehler korrigiert: Sie nimmt einen Wert vom »adresse«-Typ entgegen, extrahiert die PLZ aus dem Namensfeld, kopiert sie in das ihr zugedachte Feld und gibt den berichtigten Datensatz als Wert vom Typ »adresse« wieder zurück.
|
Listing 3: Komplexe |
|---|
01 CREATE TYPE adresse AS (name text, strasse text, stadt text, plz int);
02
03 CREATE TABLE personen (pid serial, addr adresse);
04 INSERT INTO personen (addr)
05 VALUES (row('Heinz Meier', 'Am Hang 13', '94849 Irgendwo', NULL));
06
07 CREATE OR REPLACE FUNCTION lies_plz(adresse) RETURNS adresse AS $$
08 my $addr = $_[0];
09 my $city = $addr->{'stadt'};
10 $city =~ s/^s*(d*)s+//; # strip numerical prefix
11
12 return { name => $addr->{'name'}, strasse => $addr->{'strasse'},
13 stadt => $city, plz => $1 || 0 };
14 $$ LANGUAGE plperl;
15
16 SELECT lies_plz(addr) FROM personen;
|
Die Beispiele in den Listings 2 und 3 demonstrieren auch das neue, so genannte Dollar-Quoting. Bislang wurden Funktionen stets in Hochkommata eingeschlossen, was den Nachteil hat, dass man in der kompletten Funktion jedes »\’« durch »\’\’« ersetzen muss. Selbst ein leerer String geriet damit zu einem unübersichtlichen »\’\’\’\’«. Mit dem Dollar-Quoting lassen sich nun Funktionen (und alle anderen Text-Variablen ebenfalls) innerhalb von »$$ … $ definieren und darin die normalen Quote-Zeichen verwenden.
Hinter den Kulissen
Unter den Änderungen der neuen PostgreSQL-Version gibt es auch solche, von denen normale Datenbankbenutzer profitieren, obwohl sie ihnen nicht direkt begegnen. So wurden Planer und Optimizer verbessert, ebenso das Caching der Datenbank. Es beachtet neuerdings neben dem Zeitpunkt des letzten Zugriffs auf eine Speicherseite auch die Häufigkeit der Zugriffe in der Vergangenheit. Beide Werte bestimmen jetzt, welche Seiten PostgreSQL im Cache halten soll und welche nicht.
Der neue Algorithmus nennt sich ARC (Adaptive Replacement Cache), zuvor war dafür lediglich ein LRU-Algorithmus (Least Recent ly Used) zuständig. Die bisherigen Versionen schrieben damit geänderte Speicherseiten alle paar Minuten auf die Festplatten zurück, was zur Folge hatte, dass in dieser Zeit die Plattenaktivität sehr hoch war.
Mit dem neuen, so genannten Background Writer verteilen sich die Schreibzugriffe gleichmäßiger, was zu geringerer Spitzenlast führt und damit den Gesamtdurchsatz des Systems erhöht. Weniger Ressourcen-hungrig ist nun auch der Vacuumprozess, der nicht mehr benutzten Speicherplatz freigibt. Auch bei ihm ist die Balance zwischen Laufzeit und Last konfigurierbar.
Detailverbesserungen
Die Liste der Neuerungen ist damit allerdings noch längst nicht ausgeschöpft. Erwähnenswert sind beispielsweise auch das eingebaute Logrotating oder die neue Fähigkeit von Pg_dump, Abhängigkeiten aufzulösen. Damit werden jetzt Dumps erzeugt, die Pg_restore zurückschreiben kann, ohne an Abhängigkeitsproblemen zu scheitern. Ebenfalls neu ist der so genannte Expression Index, der nicht nur die Ergebnisse einer Funktion indiziert – das gab es schon zuvor -, sondern auch mit beliebigen Ausdrücken arbeitet.
Oft fragen Anwender nach einem grafischen Administrationstool für PostgreSQL. Davon gibt es mehrere, speziell an die Version 8.0 angepasst sind aber Php Pg Admin[5] und Pg Admin III[6]. Während der Benutzer Php Pg Admin über eine Weboberfläche bedient, handelt es sich bei Pg Admin um ein natives Programm, das dank der Verwendung von Wx-Widgets sowohl unter Linux als auch unter Windows läuft. Abbildung 2 zeigt als Beispiel einen Screenshot von Pg Admin III.
Abbildung 2: Das grafische Administrationstool Pg Admin III ist speziell an die neue PostgreSQL-Version angepasst und läuft gleichermaßen unter Linux wie Windows.
Seit der Veröffentlichung von PostgreSQL 7.4 vor über einem Jahr hat sich auch im Bereich der Standardisierung einiges getan: Ende 2003 wurde die neue Version des SQL-Standards – SQL 2003 – verabschiedet. In PostgreSQL 8.0 sind daher diverse Änderungen eingeflossen, die die Konformität mit diesem neuen Standard verbessern. Die neue prozedurale Sprache PL/Java orientiert sich ebenfalls an der Spezifikation der Server-seitigen Java-Anbindung in SQL 2003. Die Umsetzung von weiteren Features des neuen Standards ist für die nächste Release geplant.
Eine Neuerung bei PostgreSQL 8.0 erregt vor allem außerhalb der Linux-Welt Aufsehen: Auf vielfachen Wunsch gibt es das freie Datenbanksystem nun auch in einer Version für Windows. Vorher lief es nur in der Cygwin-Umgebung, die die Systemaufrufe aus der Unix-Welt emulierte. Die neue, native Windows-Version führt zu einer beachtlichen Leistungsverbesserung unter diesem Betriebssystem. Auf[7] ist ein Installer für PostgreSQL zu finden, der mit wenigen Klicks die Windows-Version auf den Rechner zaubert. Die bereits erwähnte grafische Administrationsoberfläche Pg Admin III installiert er bei dieser Gelegenheit gleich mit.
Mit der neuen Version ist dem freien Datenbanksystem ein großer Schritt in die Zukunft gelungen. PostgreSQL 8.0 erweist sich als gut gerüstet für den Wettkampf mit anderen Open-Source-Datenbanken. Wer sich heute nach einer neuen Datenbank umsieht, sollte dieses System – es steht unter der BSD-Lizenz – auf jeden Fall in die engere Wahl einbeziehen. (jcb)
|
Funktionen für |
|---|
|
Auf dem Datenbankserver hinterlegte Funktionen oder Stored Procedures entlasten den Client von vielen Zwischenrechnungen und führen oft zu einem Gewinn an Performance. PostgreSQL bietet besonders viele Möglichkeiten, derartigen Code in vielen Sprachen zu programmieren. Arbeit delegierenin praktisches Beispiel: Ein Mailserver implementiert als Spam-Schutz die Greylisting-Technik. Dazu verwendet er eine Datenbank, die verschiedene Whitelists verwaltet. Es sollen folgende Regeln gelten: Jede Mail eines unbekannten Absenders wird für vier Minuten temporär ablehnt. Jede Kombination aus Sender-IP-Adresse und Empfänger verfällt nach zwölf Stunden, falls dafür nur eine Mail eingeht. Gibt es weitere Mails, ist die Kombination 30 Tage nach der letzten Aktivität zu löschen. All diese Regeln müssten entweder dem Mailserver oder einem externen Programm beigebracht werden. Es gibt jedoch auch die Alternative, ohne Zwischenschicht einfach eine Funktion auf dem Datenbankserver zu hinterlegen, die die Whitelists für IP-Adressen, Absender und Empfänger beachtet, die entsprechenden Timestamps verwaltet und außerdem weiß, nach welcher Zeit ein Datensatz verfallen ist. Der Mailserver fragt dann lediglich über eine einzige Funktion (»DeferGreylisting( IP, Sender, Recipient)«) ab, ob die Mail angenommen oder vorerst abgewiesen werden soll. Die Funktion prüft selbst alle Bedingungen anhand der Datenbankeinträge, ohne dass hierbei ein Datentransfer zwischen Mail- und Datenbankserver anfällt. In PostgreSQL ist PL/PgSQL für eine solche Aufgabe das Mittel der Wahl. Es handelt sich dabei um ein SQL mit Programmkonstrukten, also mit If und Else, mit Schleifen und seit 8.0 auch Exception-Handling. Außerdem werden Funktionen in dieser Sprache vorkompiliert, was eine sehr schnelle Ausführung zur Folge hat. Der Nachteil dabei ist, dass der Programmierer kaum auf bereits vorhandene Module zurückgreifen kann. ProgrammbausteineMöchte er aber unbedingt von vorgefertigten Modulen profitieren, kann er unter PostgreSQL auf eine andere Sprache ausweichen, etwa auf PL/Perl. Für das Beispiel könnte er sich etwa wünschen, dass die Datenbank bei einem Select neben der IP-Adresse gleich noch den zugehörigen Hostnamen anzeigt. Dies kann er durch eine PL/Perl-Funktion realisieren, die Perls Net::DNS-Modul benutzt und die Datenbank damit in die Lage versetzt, auch DNS-Lookups durchzuführen. |
|
Infos |
|---|
|
[1] PL/Java: [http://gborg.postgresql.org/project/pljava/projdisplay.php] [2] PL/R: [http://www.joeconway.com/plr/] [3] PL/Ruby: [http://moulon.inra.fr/ruby/plruby.html] [4] PL/sh: [http://developer.postgresql.org/~petere/pgplsh/] [5] Php Pg Admin: [http://phppgadmin.sourceforge.net/] [6] Pg Admin III: [http://www.pgadmin.org/pgadmin3/index.php] [7] PostgreSQL-Installer für Windows: [http://pgfoundry.org/projects/pginstaller] |
|
Der |
|---|
|
Joachim Wieland studiert an der RWTH-Aachen Informatik und hat sich vor vier Jahren mit dem PostgreSQL-Virus infiziert. |





