
© dzmitri mikhaltsow, 123RF
Wer jahrzehntelang programmiert, füllt im Lauf der Zeit seine persönliche Trickkiste und hat Best-Practice-Tipps parat. Der Perlmeister bildet da keine Ausnahme und öffnet in dieser Ausgabe des Linux-Magazins seinen erprobten Fundus.
Online PLUS
Im Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/Ausgaben/2016/01/plus
Bei jedem neuen Perl-Projekt – und ich fange jede Woche mehrere davon an – gilt es zunächst, die Arbeitsumgebung abzustecken. Schließlich soll später kein Haufen Spaghettiskripte herumliegen, die keiner pflegen will oder – wegen Erinnerungslücken – kann. Auf dem CPAN steht eine Reihe von Template-Generatoren bereit. Neulich fiel mir App::Skeletor auf, das sich, über Template-Module erweitert, an lokale Gegebenheiten anpassen lässt. Kurzerhand schrieb ich Skeletor::Template::Quick, um das Original an meine Bedürfnisse anzupassen, und stellte es aufs CPAN.
Wer die Autoren-Info, wie Abbildung 1 zeigt, in der Datei »~/.skeletor.yml« im Homeverzeichnis ablegt und nach der Installation des Template-Moduls vom CPAN den Befehl »skel Foo::Bar« aufruft, bekommt blitzschnell eine Handvoll vordefinierter Dateien für eine neue CPAN-Distribution in ein neues Verzeichnis »Foo-Bar« gepflanzt. Alternativen wären das Perl beiliegende Tool »h2xs« oder das CPAN-Modul Module::Starter.
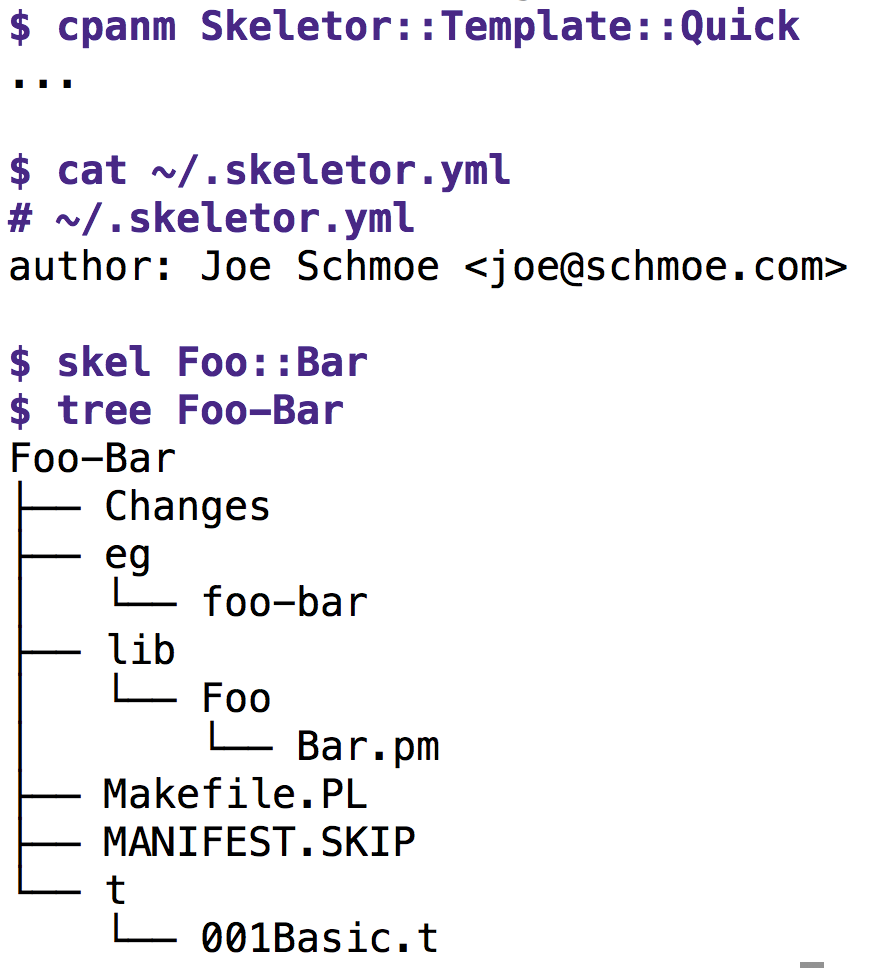
Abbildung 1: Der Skeletor erzeugt das Rohgerüst für ein neues CPAN-Modul.
Um künftige Nutzer eines neuen Moduls auf dem CPAN als Mitstreiter zu rekrutieren, enthält das miterzeugte, Perl-typische »Makefile.PL« einen Link auf das Github-Repository mit dem Sourcecode. Auf http://search.cpan.org steht der Verweis später gleich neben dem Link zum Herunterladen des Moduls, und der Autor freut sich auf Github über Pull-Requests zur Verbesserung des Codes (Abbildung 2).
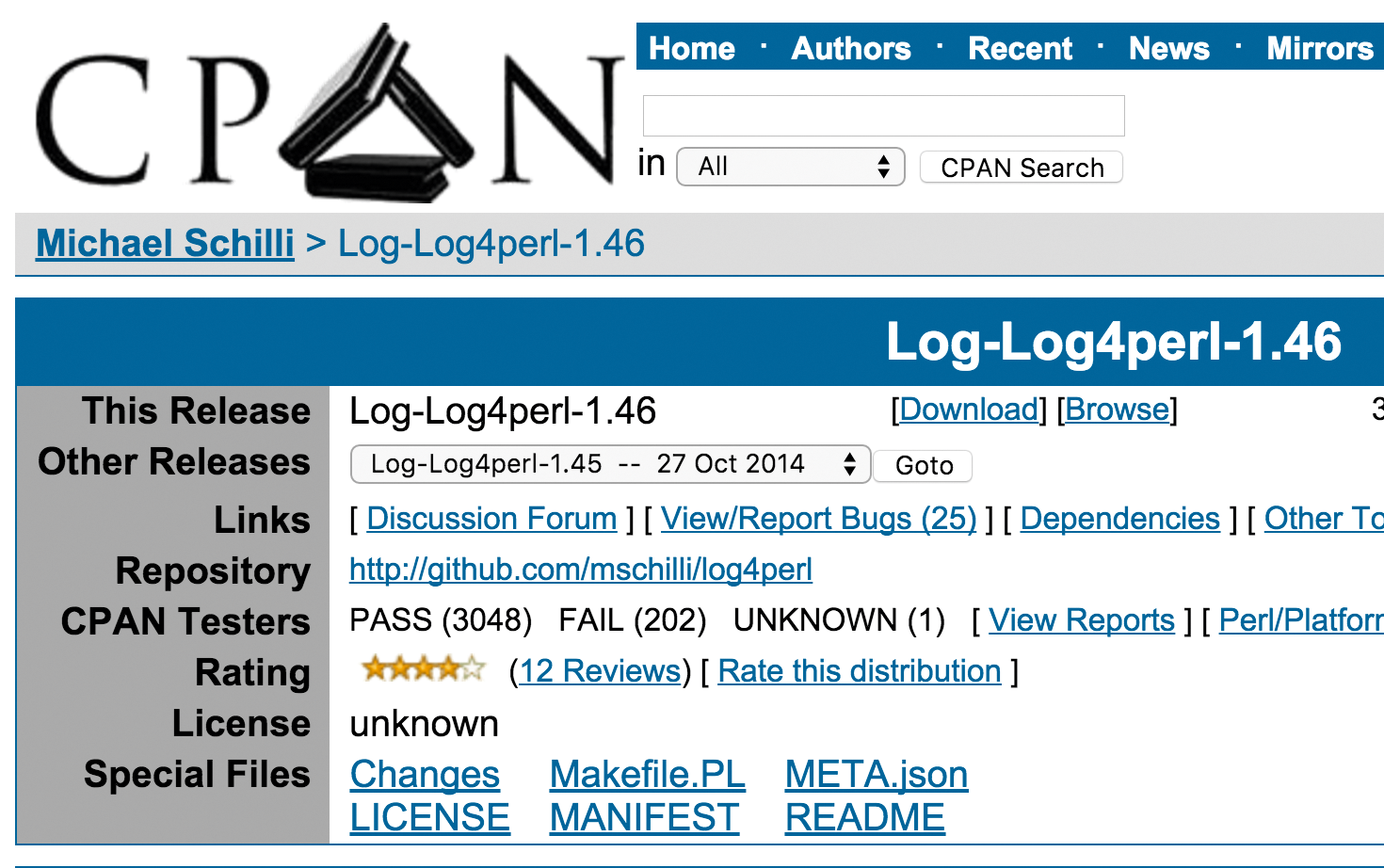
Abbildung 2: Auf dem CPAN-Server steht unter »Repository« ein Link zum Github-Projekt des Moduls.
Solides Fundament
Der Template-Generator erzeugt im neu angelegten Verzeichnis alles, um gleich loszulegen: von den Moduldateien (»lib/Foo/Bar.pm« ) bis zu Beispielskripten wie »eg/foo-bar« und einer Testsuite (»t/001Basic.t« ) steht im neu erzeugten Verzeichnis alles bereit. Die Codedateien verfügen nicht nur über praktische Code-Snippets, sondern geben auch Templates für die Dokumentation vor. Das ist wichtig, denn zu dokumentieren, wie man den programmierten Code nutzt, sollte nie als lästige Pflicht gelten.
Wenn ich neuen Code entwerfe, schreibe ich zuerst auf, wie die Zielgruppe meine technischen Wunderwerke nach meiner Vorstellung nutzt. Meist sind es objektorientierte Module, und vor der ersten Zeile der Implementierung schreibe ich in den Abschnitt »SYNOPSIS« im »POD« -Bereich des Sourcecodes, wie die neue Klasse instanziert wird und was nachher aufgerufene Methoden machen:
my $m = MyModule->new; $m->dosomething( 42 );
Diese leichte Übung hilft oft herauszufinden, ob das erdachte Interface wirklich eine schlaue Idee ist. Wenn es sich nur umständlich handhaben lässt oder verkehrt anfühlt, ist es schnell korrigiert, denn noch ist kein Code nachzubessern.
Stehen bleiben, TDD-Polizei!
Als vor etwa zehn Jahren das Test-Driven Development (TDD, [2]) aufkam, nach dessen Lehre Entwickler erst einen Testfall schreiben und anschließend das neue Feature einfügen, sprangen viele begeistert auf den Zug auf. Im Pair-Programming entstand neuer Code und jedem neuen Feature ging ein Testfall voraus, der vor der Komplettierung fehlschlug (roter Balken) und nach erfolgreichem Abschluss durchlief (grüner Balken).
Irgendwann war aber aus dem Verfahren die Luft raus und viele Programmierer kehrten zum alten Trott zurück. Zwei Dinge habe ich behalten: Änderungen im Code erstelle ich nach der Theorie des Minimum viable Product, klopfe erst mal die gewünschte Funktion rein, teste und nutze anschließend Refactor-Methoden, um das Projekt sauber zu halten.
Immer wenn ich einen Fehler finde und im Code berichtige, versuche ich auch einen Testfall einzufügen, der ohne den Bugfix Alarm schlägt und nach der Behebung ruhig durchläuft. Das ist unbezahlbar, um Regressionen zu vermeiden, die unvermeidlich auftreten, wenn der Code komplexer wird oder sich das Projekt der zehnten Release nähert.
So hat sich nach dem Verfahren “Steter Tropfen höhlt den Stein” mit verhältnismäßig geringem Aufwand eine erstaunlich umfangreiche Testsuite gebildet, die auch sorgfältigste Programmierer nicht ad hoc aus dem Boden stampfen könnten.
IDE für alte Hasen
Bei Entwicklungsumgebungen scheiden sich die Geister. Mancher bevorzugt ein komfortables Monstertool wie Eclipse mit Mausbedienung, das auch die Programmsyntax erkennt und alle Variablen und Funktionen so miteinander verlinkt, dass der Entwickler per Klick zwischen Definition und Verwendung sowie zwischen Dateien hin und her springen kann.
Was praktische IDEs angeht bin ich als alter Hase nicht sehr verwöhnt, lege aber Wert auf Performance. Ich nutze den »vim« -Editor mit einem Trick, um zwischen Dateien eines Projekts hin und her zu schalten: Mit aufgerufen, stellt »vim« alle auf der Kommandozeile übergebenen Dateien als Reiter dar, zwischen denen ich mit »gt« (go to Tab, nach rechts) und »gT« (nach links) wechsle (Abbildung 3). Damit es noch schneller geht, habe ich »gt« mit Vims »map« -Kommando auf [Shift]+[L] gelegt und »gT« auf [Shift]+[H] (siehe ».vimrc« auf [3]).
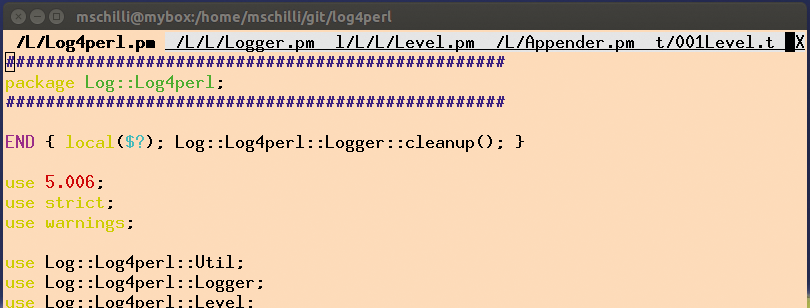
Abbildung 3: Vier Sourcedateien und eine Testsuite offen im Vim-Editor mit Reitern.
Das kann ich mir leicht merken, denn ein kleines [H] bewegt in »vim« den Cursor nach links und ein kleines [L] nach rechts. Also fahre ich zwischen den Reitern einfach mit den entsprechenden Großbuchstaben hin und her. Wer viele Dateien gleichzeitig offen hat, kann nicht alle gleichzeitig mit »ZZ« oder »:wq« verlassen, sondern muss »:qall« eingeben oder Letzteres, wie ich, mit »map« auf [Shift]+[Q] legen.
Infrastruktur als Code
Damit Code nicht nur in der Entwicklungsumgebung, sondern auch bei den Anwendern funktioniert, muss der Release-Prozess zwei Dinge sicherstellen: Der erzeugte Artifact darf sich den Sourcecode ausschließlich aus dem Git-Repository holen und sich nicht auf lokal herumliegende Dateien verlassen, damit sich der Build immer reproduzieren lässt. Und bevor das Erzeugnis in die Wildnis entlassen wird, muss es die beiliegende Testsuite bestehen, die die Sicht des Endanwenders simuliert.
Dazu setzen professionelle Entwicklungsschmieden Buildserver ein, die mit Jenkins oder ähnlichen Tools automatisch aufwachen, falls neue Sourcen im Git-Repository vorliegen. Sie schnappen sich diese, starten den Build, lassen die Tests laufen und schnüren im Erfolgsfall ein Artifact wie einen Tarball oder ein RPM-Paket. Letzteres schieben sie gleich noch in einem Rutsch zum Distributions-Server. Open-Source-Projekte nutzen hierzu oft Travis-CI [4], einen exzellenten Buildhoster, der per Knopfdruck einen Buildserver für ein Github-Projekt aufsetzt und sich mit simplen dreizeiligen Konfigurationen im Sourcecode begnügt.
Für den Hausgebrauch reicht eine virtuelle Umgebung wie eine mit Ansible provisionierte Vagrant-VM [5] oder ein Docker-Container [6], der den Artifact erzeugt und testet. Das Skript »cpan-upload« aus dem Modul CPAN::Upload schiebt danach einen mit »make tardist« geschnürten Tarball aufs CPAN.
Listing 1 zeigt eine Docker-Konfiguration, die einen auf Ubuntu basierten Reinraum erzeugt. Der erste Aufruf von Dockers »build« -Kommando holt sich das schlanke Ubuntu-Basis-Image vom Docker-Mutterschiff und setzt weitere Layer drauf, entsprechend den Anweisungen der im Verzeichnis liegenden Datei »Dockerfile« :
Listing 1
Dockerfile
01 FROM ubuntu 02 03 RUN apt-get -y update 04 RUN apt-get -y install cpanminus 05 RUN apt-get -y install make 06 RUN apt-get -y install libwww-perl
docker build -t testimg .
Die Anweisungen im Dockerfile veranlassen Docker dazu, mit »apt-get update« Ubuntus Paketmanager auf die neuesten Repository-Versionen einzunorden sowie Pakete zur Build-Unterstützung wie »make« zu installieren. Spätere Aufrufe des gleichen »build« -Kommandos sparen sich diesen Aufwand, denn »docker« stellt fest, dass das zwischengespeicherte Image aufgrund seiner Hashsumme noch den Anweisungen des unmodifizierten Dockerfile entspricht.
Das Build-Skript in Listing 2 führt nach dem »build« -Kommando, das ein neues Containerimage erzeugt, ein »run« -Kommando aus, das basierend auf dem Image einen Container startet. Die Option »-v« blendet das Source-Verzeichnis des Moduls im Container unter »/mybuild« schreib- und lesbar ein. Da das »build« -Skript unter »adm/build« im Git-Repository des Moduls steht, findet Perls »FindBin« zunächst heraus, in welchem Verzeichnis sich das aufgerufene Skript befindet. Nachdem bekannt ist, dass der Modulcode ein Verzeichnis darüber liegt, wechselt »Path::Tiny« dorthin und gibt dann mit »canonical« den absoluten Pfad dahin zurück.
Listing 2
build
01 #!/usr/local/bin/perl -w 02 use strict; 03 use Sysadm::Install qw(:all); 04 use FindBin qw( $Bin ); 05 use Path::Tiny; 06 07 my $tag = "build"; 08 my $dir = path( "$Bin/.." )->realpath; 09 10 sysrun "docker", "build", "-t", $tag, "."; 11 12 sysrun qw( docker run --rm --name buildc -v ), 13 "$dir:/mybuild", $tag, "bash", "-c", 14 "cd /mybuild; perl Makefile.PL; make test; make tardist";
Als Kommando im Container verwendet Zeile 13 »bash« und übergibt ihr mit der Option »-c« einen String mit dem Perl-typischen Dreisprung »perl Makefile.PL; make test; make tardist« , der den Modulcode unter Reinraumbedingungen zum Distributions-Tarball schnürt. Weitere Buildstufen kopieren den Tarball in neue Reinräume und testen, ob er sich installieren und verwenden lässt, was nicht automatisch der Fall ist, besonders wenn er zur Laufzeit noch weiter Module vom CPAN benötigt.
Automatisch fehlerfrei
Wichtig ist, dass jede Stufe dieses Buildprozesses automatisch abläuft und sofort die Notbremse zieht, falls unerwartete Ereignisse auftreten. Automatisch deshalb, weil menschliche Bediener ständig Fehler machen, wenn sie immer die gleichen Schritte ausführen, und schnell ermüden, was aus Frustration darüber dann noch zu grauenhaften Code-Nachlieferungen führt. Wer Zeit investiert hat, um den Buildprozess zu automatisieren, weiß zu schätzen, wenn er nach einer Änderung im Code nur ein Knöpfchen drückt und dann in die Mittagspause gehen kann, weil alles seinen erprobten Gang geht.
Release-Status markieren
Um später feststellen zu können, auf welchem Stand des Sourcetree eine Release basiert, muss der Buildprozess den Stand in Git markieren, üblicherweise mit einem Tag, das die Release-Nummer enthält:
git tag release_1.01 git push --tags origin
Wenn »origin« das Remote des Git-Repository bezeichnet, sorgt der nachfolgende »push« -Befehl mit dem Argument »–tags« dafür, dass das Tag nicht nur im lokalen Git-Repository liegt, sondern für jedermann zugänglich auf Github oder dem Hoster der Wahl. Wer später Bugs in zurückliegenden Releases reproduzieren möchte und die Sourcen zum Release-Zeitpunkt braucht, checkt diese mit
git checkout -b testbug release_1.01
aus und findet in einem neuen Branch »testbug« den Stand der Dinge zum Zeitpunkt ihrer Entstehung.
Pakete schnüren
Das CPAN nimmt Tarbälle an, aber wer seinen Nutzern Komfort gönnt, packt den Build in ein Paket der Zieldistributionen wie Debian oder RPM. Wer sich nicht scheut, die Hälfte aller je geschriebenen CPAN-Module als Abhängigkeiten herunterzuladen, nutzt hierzu Dist::Zilla. Wer es schlanker mag, installiert das in Ruby geschriebene Tool »fpm« [7].
Mit einer einigermaßen frischen Ruby-Version installiert sich das praktische Tool mit »gem install fpm« . Es unterstützt unzählige Optionen, um nur einige Dateien in ein Paket der unterstützten Formate RPM, Debian oder OS X zu verschnüren, reichen »-s dir« und das lokal während des Buildvorgangs erzeugte Unterverzeichnis »usr« als Quelle.
Dort lagern, wie das »tree« -Kommando in Abbildung 4 zeigt, die Dateien so, wie sie später auf dem zu installierenden System liegen sollen, also das Skript »foo« in »usr/bin/foo« und das Perl-Modul »Foo.pm« unter »usr/lib/perl5/site_perl/Foo.pm« . Das Beispiel gibt als Paketformat mit »-t deb« Debian vor, also liegt dann im Verzeichnis eine Deb-Datei mit der angegebenen Versionsnummer.
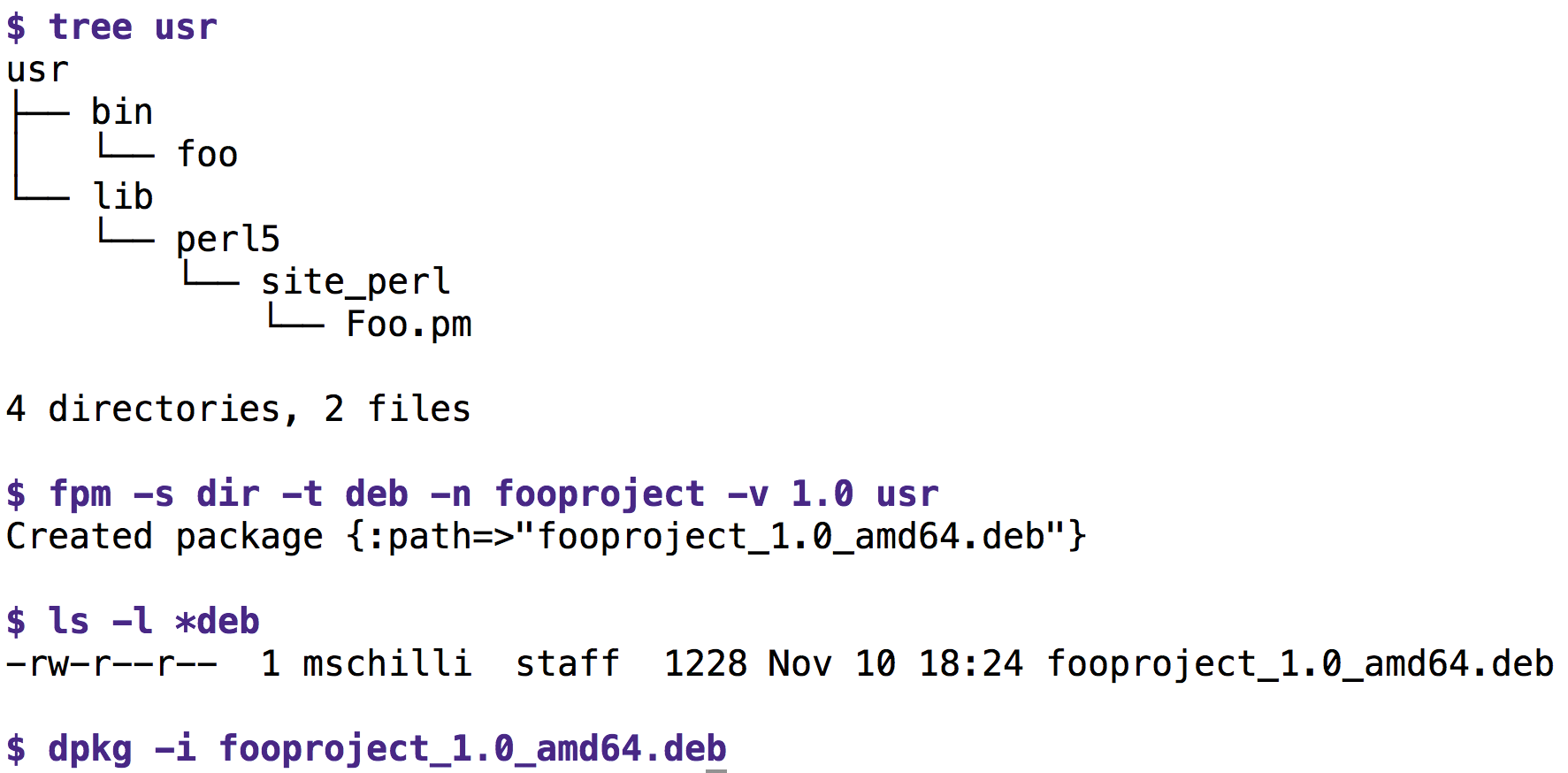
Abbildung 4: Das Schnür-Tool »fpm« packt die unter »usr« liegenden Dateien in ein Debian-Paket.
Das Tool ist traumhaft einfach zu bedienen und schirmt den Entwickler von teilweise recht tragischen Implementierungen spezifischer Paketbündler wie beispielsweise »rpmbuild« ab. Es beherrscht auch Abhängigkeiten von anderen Paketen und vieles mehr und sollte in keiner Werkzeugkiste fehlen.
Rein in den Karton
Teilweise zieht ein neues Projekt eine Latte von CPAN-Modulen herein, die unter Umständen noch nicht als Pakete für die Distribution des Endanwenders existieren. Der zeitfressende Ausweg, eine CPAN-Shell zu öffnen und zu initialisieren, falls es erste Aufruf ist, und dann ein paar Dutzend Module zu installieren, die weitere Module heranziehen, ist oft nicht machbar. Besonders dann nicht, wenn die Zielgruppe nichts mit Perl am Hut hat und nur das neue Kommandozeilen-Utility des Projekts nutzen möchte.
In diesen Fällen leistet das CPAN-Modul Carton unschätzbare Dienste, denn in einer Datei »cpanfile« abgelegte Abhängigkeiten im Format
requires 'Log::Log4perl', '1.0'; requires 'Pod::Usage', '0.01';
löst es selbstständig auf, zieht indirekt abhängige Module mit hinein, startet für alles einen Buildprozess und installiert mit »carton install« die ganze Enchilada in dem neuen Verzeichnis »local« . Wenn man das dann in das Verzeichnis des im letzten Abschnitt besprochenen Utility »fpm« verschiebt, schnürt das Tool ein Paket, das auf dem Zielsystem unabhängig von dort installierten Modulen funktioniert, was ein robustes System ergibt.
Bugs? Welche Bugs?
Jedem Programmierer unterlaufen Fehler, und manchmal muss er den Tatortreiniger-Anzug überstreifen und mit dem Perl-eigenen Debugger durch den Code stapfen, um zu sehen, wo das Problem liegt. Tritt das Problem nicht am Anfang des Skripts, sondern mitten in einem Modul auf, kann er in der zugehörigen Funktion einen Breakpoint setzen, manuell dort hinsteppen oder meinen Lieblings-Perl-Trick verwenden: Das an die gewünschte Stelle im Code eingepflanzte Statement
$DB::single = 1;
unterbricht den mit »perl -d Skript« und »c« gestarteten Debugger genau nach dieser Stelle. Manchmal laufen Perl-Zeilen ab, noch bevor die eigentliche Show im Hauptprogramm beginnt. Zum Beispiel legt der ORM-Wrapper Rose::DB seine Datenstrukturen an, während ein Datenbankmodul zum Beispiel mit »use My::Data« eingebunden wird.
Wie lässt sich ein Skript, das dieses Modul nutzt, so starten, dass der Debugger nicht erst in der ersten Zeile des Hauptprogramms anhält, sondern bereits in My::Data? Stellt man die Zeile
BEGIN { $DB::single = 1 }
an den Anfang des Skripts, hält der Debugger in der ersten ausführbaren Zeile an, egal ob die im Hauptprogramm oder sonst irgendwo steht.
Alles aufschreiben
Oft stolpert ein Entwickler über unschöne Codekonstrukte wie Duplizierungen oder offensichtliche Bugs, die zur Laufzeit hässliche Warnungen ausgeben. Dann passiert irgendetwas Überraschendes, etwa die Entdeckung eines weiteren, noch katastrophaleren Fehlers, der unbedingt sofort behoben werden muss, oder ein externes Ereignis wie eine Arbeitsstörung in Form eines Chefbesuchs – und schon ist der kleine Fehler in Vergessenheit geraten. Nichts ist ärgerlicher, als schon einmal gefundene Fehler später bei einer Live-Demo oder in der Produktion wiederzusehen, weil man sie sehenden Auges hat durchschlüpfen lassen.
Daher: Immer alles notieren, entweder in einem Merksystem wie Evernote oder – wer die Disziplin besitzt, immer wieder nach To-do-Merkern im Code zu suchen – auch damit. Aber Vorsicht, die meisten Entwickler schaffen das nicht und man stößt auch in schon jahrelang erfolgreich aktiven Paketen immer noch auf vergessene To-do-Konstrukte.
Infos
- Listings zu diesem Artikel:ftp://www.linux-magazin.de/pub/listings/magazin/2016/01/perl-snapshot
- Michael Schilli, “Am Anfang war der Test”, Linux-Magazin 08/13, S. 104: https://www.linux-magazin.de/Ausgaben/2013/08/Perl-Snapshot
- Vimrc-Datei des Autors: https://github.com/mschilli/dotfiles
- Michael Schilli, “Erweiterte Testansicht”, Linux-Magazin, 06/12, S. 94: https://www.linux-magazin.de/Ausgaben/2012/06/Perl-Snapshot
- Michael Schilli, “Science. Not Fiction”, Linux-Magazin 10/15, S. 94: https://www.linux-magazin.de/Ausgaben/2015/10/Perl-Snapshot
- Michael Schilli, “Erhebendes am Dock”, Linux-Magazin, 05/14, S. 96: https://www.linux-magazin.de/Ausgaben/2014/05/Perl-Snapshot
- Effing Package Management: https://github.com/jordansissel/fpm/wiki
Der Autor

Michael Schilli arbeitet als Software Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





