© Sergey Nivens, 123RF
Wo Container großflächig zum Einsatz kommen, sollte ein Überwachungsmechanismus her, der den überraschungsarmen Betrieb sicherstellt. Admins müssen bestehende Monitoringlösungen anpassen, um sie fit für eine containerisierte Welt zu machen.
Will ein Admin Container überwachen, muss er sich zunächst klarmachen, welche Erwartungen an das Monitoring er hegt. Möchte er wissen, wie stark die Container die Host-Ressourcen auslasten oder interessiert ihn eher die Verfügbarkeit der containerisierten Dienste? Für beide Anwendungsfälle gibt es verschiedene Ansätze, zum Teil lassen sich bestehende Monitoringlösungen nutzen.
Fürs Grobe
Docker [1] selbst bietet zwar diverse Informationen zu den Containern an [2] – aber nur anderen Tools als Ausgangsbasis für komplexere Monitoring-Ansätze. Docker selbst bereitet die Daten nicht auf. Aber es kennt ein paar Kommandos, mit denen ein Admin Container zumindest rudimentär überwacht.
Der Befehl »docker ps« zeigt alle Container an, die auf einem Host laufen oder gelaufen sind (Abbildung 1). Dies gibt dem Admin einen groben Überblick darüber, ob Container noch laufen oder eine Anwendung verfügbar ist. Außerdem fördert der Befehl weitere Angaben, etwa zu geöffneten und weitergeleiteten Ports, zutage. Beendet das System eine Anwendung, erscheint ein Returncode.
Abbildung 1: Der Befehl »docker ps« verschafft eine Übersicht der laufenden Container.
Das »docker logs« -Kommando fragt ab, was die im Container laufende Anwendung nach Stdout und Stderr schreibt. Wer diese Logs scannt, kann sich so ebenfalls ein simples Monitoring aufbauen. Damit das Kommando funktioniert, muss der Admin zuvor den standardmäßig eingestellten Logging-Treiber »json-file« aktivieren. Alternativ wählt er »syslog« oder »journald« als Logziel aus, was ihm bessere Verarbeitungsmöglichkeiten der Ausgaben beschert.
Das »docker stats« -Kommando (Abbildung 2) zeigt CPU-Verbrauch, Speicherauslastung und Netzwerk-I/O an. Die Anzeige der Daten aktualisiert sich dabei automatisch. Wer die Daten automatisiert auswerten möchte, schaltet dieses Feature besser mit dem Parameter »–no-strem« ab, dann erscheint nur das jeweils erste Ergebnis.
Abbildung 2: Auch »docker stats« zeigt einige rudimentäre Statistiken zum ausgewählten Container an.
Möchte der Containerbetreiber diese Daten weitergehend verarbeiten, hilft es ihm unter Umständen mehr, direkt die Quelle der Ressourcenstatistik anzuzapfen: Cgroups. Wie im Artikel zu Docker Security [3] beschrieben, ordnen Cgroups Prozesse hierarchisch, um sie gemeinsam zu verwalten. Cgroups bieten aber auch die Gelegenheit, Ressourcenstatistiken aufzuzeichnen. Die bilden dann die Grundlage für den »docker stats« -Befehl.
Systemd legt die »cgroup« -Daten standardmäßig im Dateisystem unter »/sys/fs/cgroup« ab. Für jedes aktive »cgroup« -Subsystem wartet hier ein Ordner, in dem das System die hierarchische Struktur der Prozesse abbildet. Unter »/sys/fs/cgroup/memory/system.slice/docker-Container-ID .scope/memory.stat« finden sich zum Beispiel die für den Container gespeicherten Artbeitsspeicher-Statistiken.
Die von Docker bereitgestellten Tools bieten einen groben Überblick für einen Host, lassen sich aber kaum für großflächiges Monitoring anwenden. Zu diesem Zweck müssen Admins andere Werkzeuge einsetzen.
Container-Statistiken live
Ein solches Tool ist etwa das Google-Projekt C-Advisor [4]. Ursprünglich für das Google-eigene Lmctfy (Let me contain that for you) entwickelt, unterstützt es mittlerweile auch Docker, vorausgesetzt dies setzt die seit Version 1.0 standardmäßig aktivierte Bibliothek Libcontainer als Execution Driver ein. Die Installation als Docker-Container ist die einfachste Möglichkeit, eine C-Advisor-Instanz zu starten.
Das Tool bereitet die Perfomance- und Auslastungsdaten in einem sich aktualisierenden Webinterface auf (Abbildung 3). Dies zeigt Ergebnisse für den ganzen Host oder für einzelne Container an, dazu gehören CPU-Auslastung, Speicherverbrauch, Netzwerk-Traffic und belegter Plattenplatz. So gewinnt der Admin einen schnellen Überblick, wie ausgelastet der Host und in welchem Zustand die Container sind.
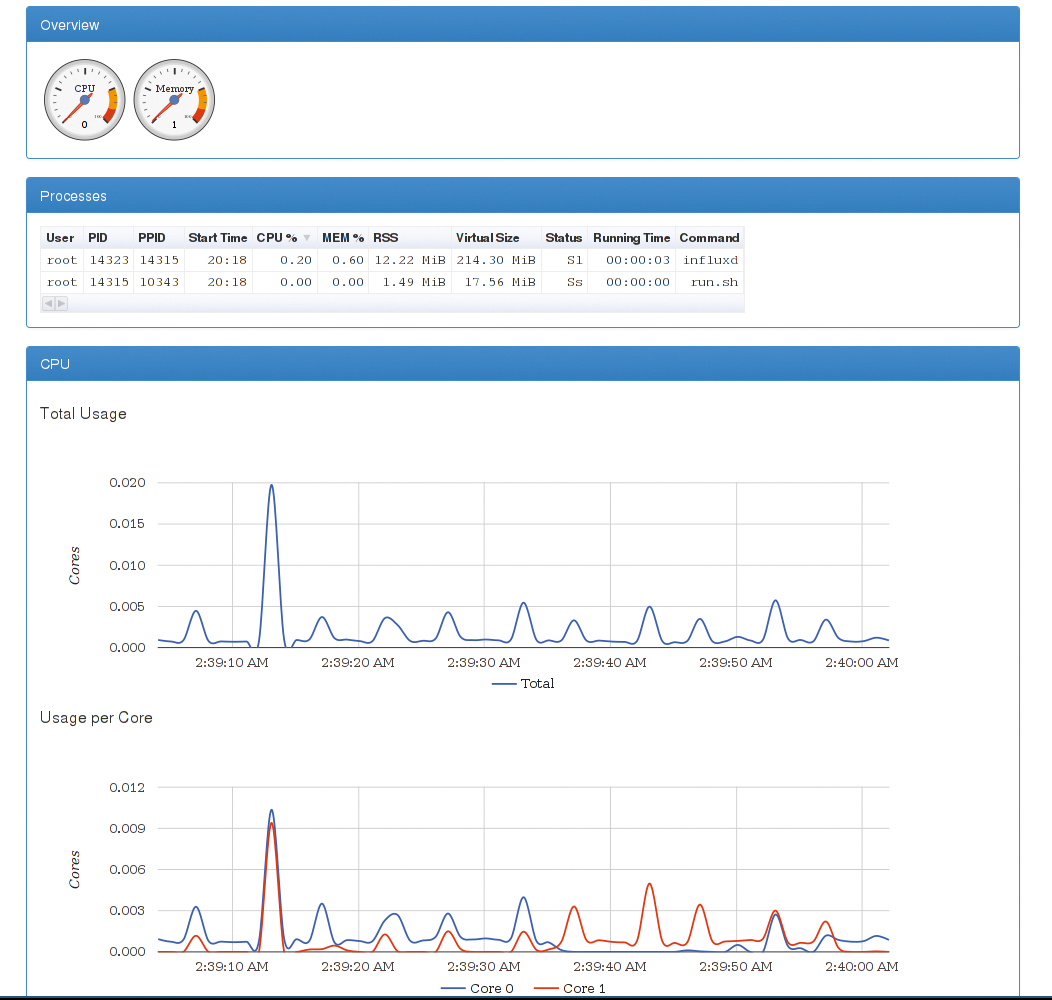
Abbildung 3: Googles C-Advisor bringt ein hübsches Webinterface mit und nutzt Influx DB als Datenbank.
C-Advisor aktualisiert die Daten live, fortschreitende Graphen visualisieren die gewonnenen Daten. Standardmäßig speichert die Software diese Daten jedoch nicht zwischen. Dafür bietet Google die Möglichkeit, die Performancedaten in eine Influx DB [5] zu schreiben. Diese hält die Daten für spätere Auswertungen bereit. Das erledigt allerdings nicht mehr C-Advisor, sondern dafür kommen andere Tools zum Zug.
Eines jener Werkzeuge, das Statistiken einer Influx DB grafisch aufbereitet, heißt Grafana [6]. Es handelt sich um einen Fork des im ELK-Stack verwendeten Kibana [7], der mit einem konfigurierbaren Dashboard punktet, das die Daten visualisiert. Der Benutzer kann aus den vorhandenen Daten eigene Graphen erzeugen, die das Dashboard dann anzeigt. Es unterstützt diverse Diagrammtypen, etwa Punkt-, Balken- oder Liniendiagramme. Für sie lassen sich weitere Optionen einstellen, etwa Stacking der Datenpunkte oder eine prozentuale Darstellung. Weitere Diagrammtypen fügt der Admin über Plugins hinzu.
Die Kombination aus Influx DB und Grafana erlaubt zudem den Einsatz von C-Advisor für eine große Menge an Hosts. Daneben konsolidiert es die Anzeige der Daten in Graphen oder Dashboards und bringt diese zwecks Überblick auf den großen Schirm. So behält der Admin die Docker-Landschaft stets im Blick.
In Zukunft soll C-Advisor weitergehende Features erhalten und Empfehlungen zur Optimierung der Containerperformance geben. Weiter soll C-Advisor die Container automatisch für die bestmögliche Performance feintunen. Die dazu nötigen Auslastungsvoraussagen sollen auch für Clustermanager zugänglich sein.
Im Cockpit
Das Red-Hat-Projekt Cockpit [8] verwaltet nicht nur Server, sondern spendiert dem Dienst auch ein Containermanagement. Das startet und stoppt Container, bietet aber auch einen Überblick dazu, welche Ressourcen die Container nutzen. Er umfasst die erzeugte CPU-Last, den verwendeten Arbeitsspeicher sowie den durch Images belegten Plattenplatz (Abbildung 4).
Abbildung 4: Cockpit zeigt die Auslastung von Containern, aber auch die Images, von denen sie abstammen.
Cockpit beobachtet die CPU und Arbeitsspeichernutzung und stellt sie als Graphen dar. Weiter listet es in der Übersicht für jeden Container den Ressourcenverbrauch auf. Leider fehlt eine Funktion, um die Container nach ihrer CPU-Nutzung oder Speicherauslastung zu sortieren, was die Liste auf Hosts mit vielen Containern schnell unübersichtlich macht. Auch erscheinen die Daten im Graphen in abgestuften Blautönen, was es bei vielen Containern erschwert zu unterscheiden, welcher davon wie viel verbraucht.
Cockpit eignet sich nicht als Monitoringlösung in großen Umgebungen, da eine Aggregation über mehrere Hosts fehlt. Weiter gibt es keine Möglichkeit, einen Alert abzusetzen, falls ein Container nicht mehr läuft, ein Dienst also nicht mehr verfügbar ist. Auf kleineren Systemen bietet Cockpit jedoch einen guten, wenn auch nicht allzu detaillierten Überblick der laufenden Container und genutzten Ressourcen.
Überwachen mit Nagios
Für bestehende Monitoringlösungen gibt es Plugins, die Container überwachen. New Relic [9] bietet auf Github die in Go geschriebenen »check_docker« -Erweiterung für Nagios ([10], [11]) an. Sie holt sich Informationen über das REST-API von Docker. Standardmäßig fragt sie aber nur die (Meta-)Datenauslastung des Hosts ab. Für diese kann der Admin Warning- und Critical-Werte setzen.
Bei Bedarf legt er zudem fest, dass ein Container mit einem bestimmten Image auf einem bestimmten Host laufen muss. Das kann sinnvoll sein, wenn der Admin »check_docker« parallel zu C-Advisor einsetzt. In diesem Fall soll C-Advisor als Container auf jedem Host starten. Der Admin eruiert mittels Nagios, ob das der Fall ist und ob auf jedem Docker-Host ein solcher Container läuft.
Die Master-Version von »check_docker« fragt zudem bestimmte Containernamen ab. Benennt der Admin seine Container bewusst, behält er so auch die Status mehrerer Container im Auge, die vom selben Image abstammen. Daneben lässt sich »check_docker« auch ohne eine Nagios-Instanz nutzen, um die Daten etwa manuell auszuwerten. Dadurch ginge aber einer der großen Pluspunkte verloren: die in Icinga und Nagios integrierte Möglichkeit, Alerts zu versenden.
So erweist sich »check_docker« als gute Ergänzung zu Perfomance-Monitoring-Tools wie C-Advisor und integriert sich nahtlos in eine bestehende Nagios/Icinga-Landschaft. Allerdings erhöht das REST-API den Konfigurationsaufwand, da der Admin die Kommunikation über TLS-Zertifikate absichern sollte, um Unbefugte auszusperren.
Abwandlungen und Kombinationen
Viele der hier aufgeführten Projekte basieren auf bestehenden Tools, die sie miteinander kombinieren. Das für das Ressourcenmonitoring in Kubernetes [12] eingesetzte Heapster [13] nutzt beispielsweise C-Advisor und Influx DB. Für die Visualisierung kommt dann entweder wiederum Grafana zum Zuge oder das Kubernetes-eigene Kubedash [14]. Auch Dockerana [15], das auf dem Dockercon Hackathon 2014 den ersten Platz belegte, verwendet Grafana und dazu Graphite [16] als Datenspeicher.
Komplexere Monitoringlösungen erfordern dann eine Kombination der Tools. Dazu gehören zum Beispiel eine Quelle, die Daten nur einsammelt, etwa C-Advisor oder Collectd [17], ein Zwischenspeicher für die Daten als Metriken, etwa Graphite oder Influx DB, sowie ein Dienst zum Visualisieren der Daten, also etwa Grafana. Jeder dieser Dienste bringt eigene Konfigurationen mit. Ihr Zusammenspiel zu koordinieren ist alles andere als trivial. Wer jedoch die Zeit investiert, den belohnen umfangreiche Monitoring-Möglichkeiten.
Wer das Monitoring nicht selbst hosten möchte, mietet sich bei einem kommerziellen Dienst wie New Relic [9], Sysdig Cloud [18] oder Datadog [19] ein. Demgegenüber stehen die schlichteren, selbst gehosteten Lösungen, zu denen Cockpit, C-Advisor oder eine Nagios-Instanz gehören und die vergleichsweise wenige Features mitbringen.
Für kleine Umgebungen, in denen nur die aktuelle Auslastung interessiert, genügen sogar die eingebauten Docker-Kommandos. Hierzu sind keine weiteren Tools nötig. C-Advisor bereitet die Daten grafisch auf und ist schnell als Docker-Container installiert. Red-Hat-basierte Systeme bringen Cockpit mit, das sogar ein schlichtes Container-Deployment ausführt.
Nutzt der Admin bereits eine Monitoringlösung für normale Server, etwa Sensu [20] oder Nagios, machen Plugins diese bereit für Docker. Er benötigt dann für die Container keine zusätzliche komplexe Monitoringsoftware und nutzt zugleich die bestehenden Features, etwa die Alarme.
Wer eine große Umgebung mit Docker plant, sollte sich die speziell dafür angepassten Monitoringtools ansehen. Diese erfordern den höchsten Konfigurationsaufwand, bieten aber auch die umfangreichsten Möglichkeiten der Daten-Aggregation und -Darstellung. Hier baut der Containermeister entweder aus den Einzelteilen eine eigene Lösung oder setzt ein Projekt wie Prometheus [21] oder Heapster ein, das einen Teil des Aufwands abnimmt. Da sich die Tools aber noch recht stark entwickeln, muss er mit Inkompatibilitäten zwischen den Versionen rechnen. Eine umfangreiche Testumgebung ist hier Pflicht.
Infos
- Docker: https://www.docker.com
- Docker Runtime Metrics: https://docs.docker.com/articles/runmetrics/
- Sebastian Meyer, “Vorsicht Container!”: Linux-Magazin 10/15, S. 26.
- C-Advisor: https://github.com/google/cadvisor
- Influx DB: https://influxdb.com
- Grafana: http://grafana.org
- Kibana: https://www.elastic.co/products/kibana
- Cockpit: http://cockpit-project.org
- New Relic: https://newrelic.com
- »check_docker« : https://github.com/newrelic/check_docker
- Nagios: https://www.nagios.org
- Kubernetes: http://kubernetes.io/
- Heapster: https://github.com/kubernetes/heapster
- Kubedash: https://github.com/kubernetes/kubedash
- Dockerana: https://github.com/dockerana/dockerana
- Graphite: https://github.com/graphite-project
- Collectd: https://github.com/bobrik/collectd-docker
- Sysdig Cloud: https://sysdig.com
- Datadog: https://www.datadoghq.com
- Sensu: https://sensuapp.org
- Prometheus: http://prometheus.io





