
© Dmitry Kalinovsky, 123RF
Websites bieten ihren Lesern zu einem Thema oft auch noch Links zu Artikeln mit ähnlichen Themen an. Die freie Suchmaschine Elasticsearch findet diese blitzschnell und automatisch, nachdem sie alle Dokumente aus einem Korpus analysiert und indiziert hat.
Wenn Ratsuchende auf der Webseite Stackoverflow nach Antworten zu Programmierfragen stöbern, steht in der Rubrik »Related« eine Liste mit Links, die sich mit ähnlichen Themen befassen (Abbildung 1). Das hält Nutzer bei der Stange, falls das erste Suchergebnis nicht passt oder die Antwort unzureichend ist. Laut [2] generiert die freie Suchmaschine Elasticsearch [3] diese Links auf der Site in Echtzeit aus der wachsenden und sehr beachtlichen Sammlung von 10 Millionen Stackoverflow-Beiträgen.
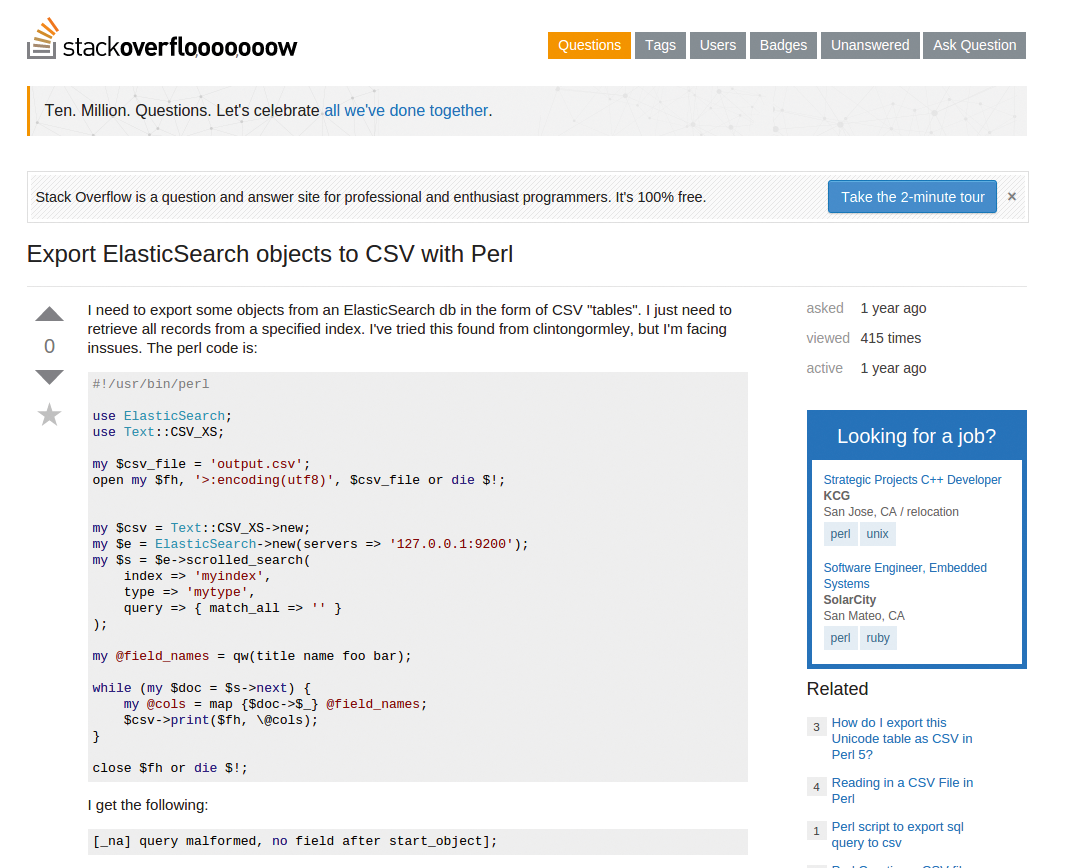
Abbildung 1: In der Rubrik »Related« generiert Stackoverflow mit Elasticsearch Links mit ähnlichen Fragen.
Künstlich schlau
Dabei ist keine richtige Intelligenz am Werk, denn Computer tun sich nach wie vor schwer, den Inhalt eines Dokuments zu verstehen, können also demnach auch keine Dokumente mit verwandten Inhalten finden. Vielmehr stützt sich der verwendete Algorithmus auf einfache Erbsenzählerei, indem er verschiedene Werte für Worthäufigkeit kombiniert und daraus einen Score ableitet.
Elasticsearch hält sich dazu einen so genannten invertierten Index vor, eine vollständige Liste der einzelnen Wörter, die in allen gespeicherten Dokumenten vorkommen. Jedem dieser eindeutigen Wörter weist der invertierte Index eine Liste mit Dokumenten zu, in denen es vorkommt. So kann Elasticsearch blitzschnell etwa eine Liste mit Dokumenten zu einem Suchbegriff ausspucken.
Sucht ein User zum Beispiel nach dem Begriff »perl« , findet Elasticsearch in dem invertierten Index aus Abbildung 2 sofort das Dokument »doc-1« und kann dieses hoffentlich akkurate Suchergebnis präsentieren.

Abbildung 2: Der invertierte Index weist Wörtern Dokumente zu, in denen der Indexer sie fand.
Bei einer Suche nach zwei Wörtern, zum Beispiel »linux cpan« , kommen hingegen zwei Dokumente in Betracht, aber da »doc-2« nur einen Begriff, »doc-3« hingegen beide enthält, verpasst der Algorithmus »doc-3« einen höheren Relevanz-Score. In einer nach dem Score absteigend sortierten Trefferliste steht Dokument »doc-3« dann ganz oben und entspricht wahrscheinlich eher den Erwartungen des Users.
Was heißt relevant?
Aber nicht alle Wörter sind gleich wichtig. Das Wort »file« kommt zum Beispiel in englischsprachigen Dokumenten zu Computerthemen verständlicherweise relativ häufig vor. Sucht der User nach »file linux cpan« , liefern »doc-2« und »doc-3« jeweils zwei Treffer, aber da »linux« für ein Dokument signifikanter als »file« ist, bewertet der Algorithmus »linux cpan« höher als »cpan file« und gibt »doc-3« den Vorzug.
Wie wichtig ein Wort in einem Dokument ist, bestimmt das Tf-idf-Maß [4]. Es weist jenen Wörtern einen hohen Wert zu, die einerseits bestimmend im Dokument vorherrschen, aber andererseits auch nicht allzu häufig in weiteren um einen hohen Score buhlenden Dokumenten stehen, also die Einzigartigkeit des Dokuments untermauern. Der Relevanzwert eines Wortes erhöht sich, je häufiger das Wort im Dokument vorkommt (TF, Term Frequency), geht aber zurück, falls das Wort auch in vielen anderen Dokumenten der Sammlung vorkommt (IDF, Inverse Document Frequency).
Suche nach Gleichem
Um nun die zu einem Dokument x ähnlichen Dokumente in der Datenbank zu finden, extrahiert Elasticsearch aus x zunächst einmal alle relevanten Wörter, formt daraus eine Suchabfrage und gibt deren Treffer aus [5]. Elasticsearch erledigt diese Suche nach ähnlichen Dokumenten ohne viel Programmieraufwand über das Query-Kommando »more_like_this« . Allerdings müssen vorher alle in Frage kommenden Dokumente in den Index wandern, und dafür bietet sich die Client-Schnittstelle Search::Elasticsearch an, also der offizielle Perl-Client für Elasticsearch vom CPAN.
Listing 3 kämpft sich durch ein Verzeichnis, in dem Textdateien liegen. Es handelt sich um Geschichten aus meinem Blog Usarundbrief.com, die ich mit Hilfe eines weiteren Perl-Skripts aus dem handgeschriebenen Contentmanagement-System extrahiert habe. Jede Textdatei entspricht einem Blogeintrag – in fast 20 Jahren haben sich 877 Einträge angesammelt, weshalb das Verzeichnis 877 Dateien enthält. Listing 1 zeigt die Shell-Ausgabe.
Listing 1
Daten einfüttern
$ ls idx | wc -l 877 $ mlt-index Added ab-in-die-redwoods.txt Added abenteuer-verkaufssteuer.txt Added abrissarbeiten-am-highway-101.txt
Aufbau des Index
Der anschließende Aufruf des Skripts »mlt-index« (Listing 3) schnappt sich die Dateien der Reihe nach und speist sie mit der Methode »index()« in den auf meinem Desktoprechner installierten Elasticsearch-Server (siehe Kasten “Installation des Elasticsearch-Servers”) ein. Wer sein Dateisystem lieber unberührt lässt, fährt mit »vagrant up« und der Vagrant-Datei in Listing 2 einfach eine VM hoch und installiert dort den Server. Das Mapping »forwarded_port« sorgt dann dafür, dass der in der VM auf Port 9200 lauschende Elasticsearch-Server auch auf dem Haupt-Host auf Port 9200 ansprechbar ist.
Listing 2
Vagrantfile
1 VAGRANTFILE_API_VERSION = "2" 2 3 Vagrant::configure(VAGRANTFILE_API_VERSION) do |config| 4 5 # 32-bit Ubuntu Box 6 config.vm.box = "ubuntu/trusty64" 7 config.vm.network "forwarded_port", guest: 9200, host: 9200 8 end
Den neu angelegten Index im Server habe ich schlicht »blog« genannt. Die Zeile 15 in Listing 3 löscht ihn erst einmal, falls er sich schon dort befindet – typischerweise von einem früheren Aufruf von »mlt-index« herrührend.
Listing 3
mlt-index
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Search::Elasticsearch;
04 use File::Find;
05 use Sysadm::Install qw( slurp );
06 use Cwd;
07 use File::Basename;
08
09 my $idx = "blog";
10 my $base_dir = getcwd;
11 my $base = $base_dir . "/idx";
12
13 my $es = Search::Elasticsearch->new( );
14 eval {
15 $es->indices->delete( index => $idx ) };
16
17 find sub {
18 my $file = $_;
19
20 return if ! -f $file;
21 my $content = slurp $file, { utf8 => 1 };
22
23 $es->index(
24 index => $idx,
25 type => 'text',
26 body => {
27 content => $content,
28 file => $file,
29 }
30 );
31 print "Added $file\n";
32 }, $base;
Die »find()« -Funktion ab der Zeile 17 aus dem Perl beiliegenden Modul File::Find arbeitet sich anschließend rekursiv durch alle Dateien unterhalb des angegebenen Verzeichnisses, wechselt im nutzerdefinierten Callback hinter den Kulissen mit »chdir« dorthin und setzt den Namen der aktuell bearbeiteten Datei in der Variablen »$_« .
Füttern von Geschlürftem
Die Methode »index()« in Zeile 23 fügt mit »content« den mit »slurp()« aus dem Fundus des CPAN-Moduls Sysadm::Install geschlürften Textinhalt der Datei sowie den Dateinamen unter »file« in den Index der Suchmaschine ein. Da die Dateinamen gemäß dem Inhalt des jeweiligen Blogeintrags gewählt sind (zum Beispiel »ab-in-die-redwoods.txt« ), braucht die Suchfunktion später bei Treffern nur den Dateinamen auszugeben. Die Fütterfunktion »index()« legt auch gleich einen neuen Index an, falls der noch nicht existiert, und definiert außer seinem Namen (»blog« ) auch noch einen »type« mit dem Wert »text« , was im Elasticsearch-Jargon nichts anderes ist als eine beliebig benannte Unterabteilung im Index.
Mehr von dem, bitte!
Das Einspeisen der Daten in Elasticsearch dauerte auf meinem Linux-Desktop pro zirka 2 KByte großer Textdatei etwa eine Zehntelsekunde, sodass dies bei 877 Blogeinträgen schon ordentlich an meiner Geduld zehrte. Dagegen verlief das Einspeisen auf meinem Laptop mit flotter Solid-State-Disk und ordentlich Arbeitsspeicher um ein Vielfaches schneller, da war dann bereits in 10 Sekunden alles erledigt.
Installation des Elasticsearch-Servers
Der Elasticsearch-Server ist mit folgenden Handgriffen rasch auf dem Desktoprechner oder in einer virtuellen Maschine installiert:
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java7-installerjava -version wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.1.deb sudo dpkg -i *.deb sudo /etc/init.d/elasticsearch start
Ist der Index fertig, können die Abfragen starten. Die Ausgabe des Kommandos »mlt-search« in Abbildung 3 zeigt, dass Listing 4 zu einem Beitrag über das amerikanische Krankenkassensystem als passende Artikel wenig überraschend als ersten Treffer denselben Artikel wiederfindet, aber zudem auch einigermaßen erstaunliche Ergebnisse, wie einen Beitrag über den Besuch eines Schießstands in South San Francisco. Die Ergebnisse kommen in Sekundenbruchteilen zum Vorschein, sodass die Funktion also durchaus auch auf einer gut besuchten Website ihren Platz hat.
Listing 4
mlt-search
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Search::Elasticsearch;
04 use Sysadm::Install qw( slurp ) ;
05
06 my $idx = "blog";
07
08 my( $doc ) = @ARGV;
09 die "usage: $0 doc" if !defined $doc;
10
11 my $es = Search::Elasticsearch->new( );
12
13 my $results = $es->search(
14 index => $idx,
15 body => {
16 query => {
17 more_like_this => {
18 like_text =>
19 slurp( $doc, { utf8 => 1 } ),
20 min_term_freq => 5,
21 max_query_terms => 20,
22 }
23 }
24 }
25 );
26
27 for my $result (
28 @{ $results->{ hits }->{ hits } } ) {
29
30 print $result->{ _source }->{ file },
31 "\n";
32 }
Listing 4 nimmt auf der Kommandozeile den Pfad einer Textdatei in Empfang und liest diese Datei mit »slurp« unter Beibehaltung der »utf8« -Kodierung ein. Sie schickt deren Inhalt ab Zeile 13 mittels der Methode »search()« in einer Query an den Elasticsearch-Server und klaubt dann aus dem als Json zurückkommenden Ergebnis die Namen der Dateien aus den Treffern mit vergleichbaren Inhalten.
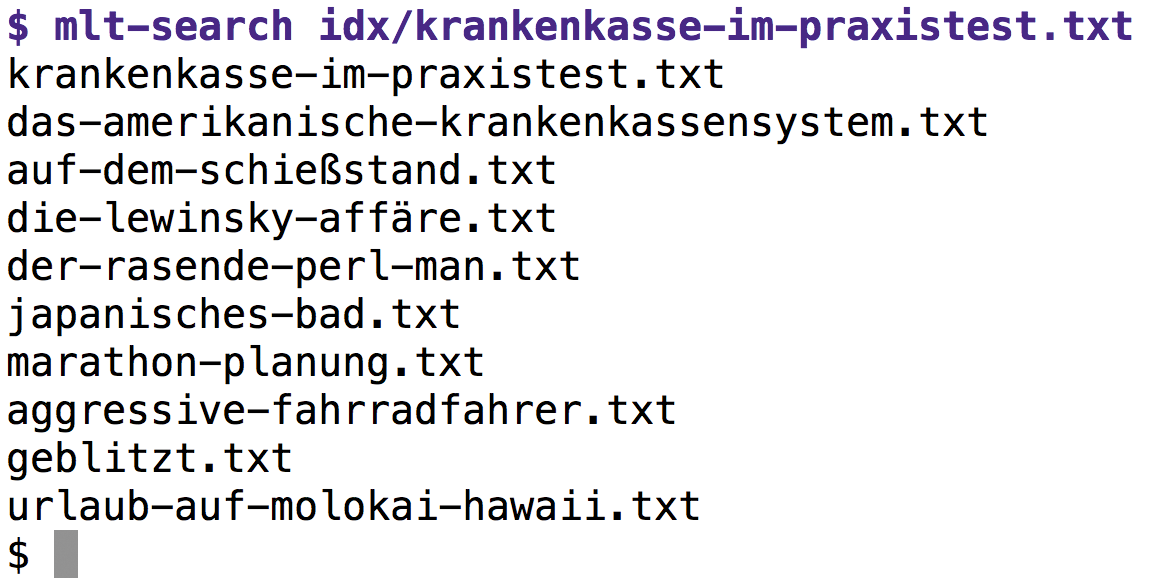
Abbildung 3: Zu einem Blogeintrag über das amerikanische Krankenkassensystem findet Elasticsearch auch passende Artikel.
Feinjustierung
Bei der Funktion »more_like_this« gibt der Parameter »min_term_freq« eine Schwelle für die Selektion eines Wortes im Referenzdokument an. Steht »min_term_freq« auf dem Defaultwert »2« , muss ein Wort dort mindestens zweimal vorkommen, um es in die Liste der Wörter zu schaffen, mit denen später andere Dokumente verglichen werden. Der zweite Parameter »max_query_terms« ist die Maximalzahl der Wörter aus dem Originaldokument, die der Algorithmus auswählt, um sie später zu einer Query zusammenzufassen.
Wer sich über weitere Methoden der Feinjustierung einer Suchmaschine informieren möchte, dem sei das O’Reilly-Buch [2] empfohlen, das mit Beispielen die Handhabung von Elasticsearch erklärt, Tipps zum Skalieren in Clustern gibt und auch einen Blick hinter die Kulissen wirft, wo die Suchengine Apache Lucene ihr Wesen treibt.
Online PLUS
Im Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/Ausgaben/2015/11/plus
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2015/11/Perl
- Clinton Gormley, Zachary Tong, “Elasticsearch: The Definitive Guide”: O’Reilly, 2015
- Michael Schilli, “Elastische Treffer”: Linux-Magazin 04/2014: https://www.linux-magazin.de/Ausgaben/2014/04/Perl-Snapshot
- Tf-idf-Maß: https://de.wikipedia.org/wiki/Tf-idf-Ma%C3%9F
- More Like This Query: https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-mlt-query.html
Der Autor

Michael Schilli arbeitet als Software Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





