
© Ivan Kmit, 123RF.com
Die auf Apache Lucene basierende Volltext-Suchengine Elasticsearch findet zügig Ausdrücke selbst in enorm großen Textsammlungen. Anhand eines Referenzbildes wühlt sie mit ein paar Tricks sogar Fotos aus der Kiste, die jemand in der Gegend geschossen hat.
Auf der Suche nach einer Suchmaschine zum schnellen Durchforsten von Logdateien stieß ich neulich auf Elasticsearch [2], eine auf Apache Lucene basierende Volltextsuche mit allerhand Extras. Auf der Downloadseite bietet das Open-Source-Projekt neben dem üblichen Tarball auch ein Debian-Paket an. Die bei Redaktionsschluss aktuelle Pre-Release-Version 1.0.0.RC2 findet mit »sudo dpkg –install *.deb« ohne Probleme den Weg in jedes Ubuntu. Praktischerweise liegt dem Debian-Paket ein Bootskript bei, mit dem Root von der Kommandozeile per
# /etc/init.d/elasticsearch start
den Elasticsearch-Server auf dem voreingestellten Port 9200 in Gang setzt.
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/2014/04/plus
Polyglott oder Perl
Die meisten Praxis-Tutorials aus dem Web nutzen die REST-Schnittstelle, um mit dem Server über HTTP zu kommunizieren. Abbildung 1 zeigt einen »GET« -Request auf den laufenden Server, der den Status anzeigt.
Zum Einfüttern von Daten und fürs spätere Abfragen gibt es eine Reihe von REST-Clients in mehreren Sprachen. Offizieller Perl-Client darf sich das CPAN-Modul Elasticsearch nennen. Zu beachten ist allerdings, dass Elasticsearch (aktuelle Version 1.03, [3]) der Nachfolger des veralteten Moduls »ElasticSearch« (großes S, [4]) ist. Zweifellos eine äußerst unglückliche Namenswahl des CPAN-Autors, schon allein weil die alte Version auf dem CPAN liegen geblieben ist und bei Suchabfragen auf http://search.cpan.org vor der neuen hochploppt.
Als nutzbringende Beispielanwendung für eine Elasticsearch-Volltextsuche identifiziere ich die Stichwortsuche in allen bislang im Linux-Magazin erschienenen Perl-Snapshots. Die Manuskripte der über 200 Artikel dieser Reihe finden sich in einem Git-Repository unter meinem Homeverzeichnis, das Skript in Listing 1 übermittelt alle rekursiv gefundenen Textdateien über die REST-Schnittstelle an den laufenden Elasticsearch-Server zur Indizierung. Der Aufruf
$ fs-index ~/git/articles
dauerte erst einige Minuten, ein zweiter Aufruf mit angewärmtem Plattencache lief dann innerhalb von 30 Sekunden durch. Eine anschließende Suche nach dem Wort “Balkon” zeigt Ergebnisse in Bruchteilen einer Sekunde:
$ fs-search balkon /home/mschilli/git/articles/water/t.pnd /home/mschilli/git/articles/gimp/t.pnd
Die im Index gefundenen Dateien offenbaren, dass ich das Wort “Balkon” bislang nur in zwei Ausgaben verwendet habe: Einmal im Juli 2008 in einem Artikel über Perls Schnittstelle zum Foto-Editor Gimp, der ein von meinem Balkon aus geschossenes Foto manipulierte [5], und einmal im März 2007, als der Perl-Snapshot die automatische Bewässerungsanlage für meine Balkonpflanzen ins gleißende Licht der Öffentlichkeit rückte [6].
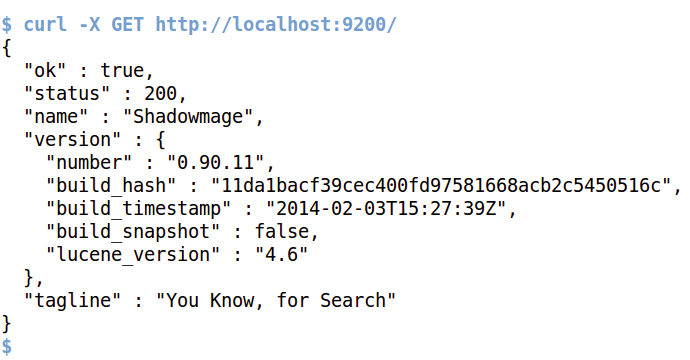
Abbildung 1: Nach dem Starten des Daemon antwortet dieser auf dem Port 9200 auf API-Anfragen.
Listing 1
fs-index
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Elasticsearch;
04 use File::Find;
05 use Sysadm::Install qw( slurp );
06
07 my $idx = "fs";
08
09 my( $base ) = @ARGV;
10 die "usage: $0 basedir" if !defined $base;
11
12 my $es = Elasticsearch->new( );
13 eval { $es->indices->delete( index => $idx ) };
14
15 find sub {
16 my $file = $File::Find::name;
17 return if ! -f $file;
18 return if ! -T $file;
19 return if -s $file > 100_000;
20 my $content = slurp $file;
21
22 $es->index(
23 index => $idx,
24 type => 'text',
25 body => {
26 content => $content,
27 file => $file,
28 }
29 );
30 print "Added $file\n";
31 }, $base;
Stets unscharfe Suche per Stemming
Es zeigt sich weiter, dass Elasticsearch Groß- und Kleinschreibung ignoriert und von sich aus Begriffe einer Stammform-Reduktion unterzieht (Stemming): Eine Suche nach “Pflanze” liefert nämlich die gleichen Ergebnisse wie oben, obwohl in den Textdateien ausschließlich von “Balkonpflanzen” die Rede ist. Allerdings begreift das Analysetool nicht, dass “Balkone” die Mehrzahl von “Balkon” ist, und liefert in diesem Fall keine Treffer. Leider treibt es Elasticsearch manchmal zu weit mit der unscharfen Suche und präsentiert Fundstücke, die keine sind, weil Wörter mit der gleichen Zeichenfolge beginnen. Abgesehen davon findet die Suchfunktion jede Nadel im Heuhaufen, und das zügig.
Das »fs-index« -Skript in Listing 1 nimmt in Zeile 9 das ihm von der Kommandozeile übergebene Suchverzeichnis entgegen und ruft den Konstruktor der Klasse »Elasticsearch« auf. Falls Suchabfragen einmal nicht das gewünschte Ergebnis bringen, lässt sich der Konstruktor mit
my $es = Elasticsearch->new(
trace_to => ['File','log']
);
dazu überreden, in der Logdatei »log« alle an den Elasticsearch-Server abgesetzten Befehle im Curl-Format auszuspucken. Per Cut&Paste kann der davon überraschte Entwickler den Vorgang Schritt für Schritt nachvollziehen.
Elasticsearch speichert die Daten einer Applikation unter einem Index, den die Zeile 7 mit »fs« (wie File System) benennt. Falls schon Daten vorliegen, löscht die Methode »delete()« ihn in Zeile 13. Die umwickelnde »eval« -Anweisung fängt etwaige Fehler stillschweigend ab, beispielsweise wenn der Index noch gar nicht existiert, weil es sich um den allerersten Aufruf von »fs-index« handelt.
Zu große und Binärdateien müssen draußen bleiben
Die Funktion »find()« aus dem Modul File::Find wühlt sich ab Zeile 15 durch die Verzeichnisse auf der Festplatte, beginnend bei dem auf der Kommandozeile übergebenen Startverzeichnis. Gefundene Binärdateien ignoriert Zeile 18, genau wie alles außen vor bleibt, was keine richtige Datei oder größer als 100 000 Bytes ist. Die Funktion »slurp()« aus dem CPAN-Modul Sysadm::Install überträgt dann den Inhalt würdiger Dateien in den Speicher, den die Methode »index()« in Zeile 22 unter dem Schlüssel »content« in die Datenbank füttert. Der Name der Datei gelangt unter dem Eintrag »file« ebenfalls dorthin.
Lokales Klein-Google mit vielen Query-Formaten
Später findet das Skript in Listing 2 Dateien zu vorgegebenen Stichworten, ähnlich wie dies die Suchmaschinen des Internets tun. Wenn ich dieses Skript per »fs-search ‘*’« aufrufe, passt darauf jedes Dokument im Index. (Die einfachen Anführungszeichen verhindern, dass die Unix-Shell sich des Metazeichens »*« bemächtigt und in einen Glob auf das lokale Verzeichnis verwandelt.) Jedenfalls liefert Elasticsearch auf »fs-search ‘*’« hin zehn mehr oder minder zufällige Ergebnisse zurück, denn unkonfiguriert ist die maximale Trefferzahl auf 10 eingestellt. Ein etwas später vorgestelltes Skript ändert diesen Wert auf 100 ab.
Die in Zeile 12 aufgerufene Methode »search()« nimmt den Namen des Suchindex, unter dem die Daten liegen (wieder »fs« ) und im »body« -Teil der Anfrage den Query-String entgegen. Aus der Dokumentation [2] ist zu entnehmen, dass Elasticsearch offenbar eine ganze Reihe historisch gewachsener Query-Formate versteht, was die etwas absurd anmutende Verschachtelung »query/query_string/query« notwendig macht.
Als Ergebnis der Erkundungsmission kommt eine Referenz auf ein Array von Treffern zurück, über das die For-Schleife in den Zeilen 20 und 21 iteriert und jeweils den ebenfalls übermittelten Eintrag zum archivierten Dateinamen in Richtung Terminal sendet.
Listing 2
fs-search
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Elasticsearch;
04
05 my $idx = "fs";
06
07 my( $query ) = @ARGV;
08 die "usage: $0 query" if !defined $query;
09
10 my $es = Elasticsearch->new( );
11
12 my $results = $es->search(
13 index => $idx,
14 body => {
15 query => {
16 query_string => {
17 query => $query } } }
18 );
19
20 for my $result (
21 @{ $results->{ hits }->{ hits } } ) {
22
23 print $result->{ _source }->{ file },
24 "\n";
25 }
Suche in GPS-Bilderdaten
Elasticsearch hat aber noch mehr drauf. Zum Beispiel erweitert der so genannte Geo Distance Filter [7] die klassische Volltextsuche um eine interessante Facette. Wer den Filter installiert und zu jedem Dokument passende Geodaten speichert, dem zeigt die Suchengine genau jene Einträge, die sich in einem bestimmten Umkreis befinden. Das ist zum Beispiel dann von Nutzen, wenn man übermüdet mit seinem Mobiltelefon herumirrt und ein offenes 5-Sterne-Restaurant sucht.
Da mein iPhone 5 wie jedes andere Smartphone zu jedem geschossenen Bild die Geodaten im Exif-Header der Jpeg-Datei ablegt, bietet sich eine Suche an, die zu einem vorgegebenen Bild im Fotoalbum des Telefons (“Gallery”) jene Bilder heraussucht, die ich im 1-Kilometer-Radius dazu geschossen habe. Die Abbildung 2 zeigt zum Beispiel ein Foto des neu gebauten östlichen Bogens der Bay Bridge [8] bei mir zu Hause in San Francisco. Auf einem Fuß- und Radweg kann ich seit letztem Jahr dort bis zur Mitte der neuen Brücke laufen.
Abbildung 3 listet die Ausgabe des Kommandos »exiftags« des vom Telefon auf den Linux-Rechner übertragenen Fotos auf. Fast ganz unten steht dort, dass das Bild an einer Geo-Location mit 37° 48.87′ nördlicher Breite und 122° 21.55′ westlicher Länge geschossen wurde.

Abbildung 2: Ein per iPhone geschossenes Bild der neuen Bay Bridge.
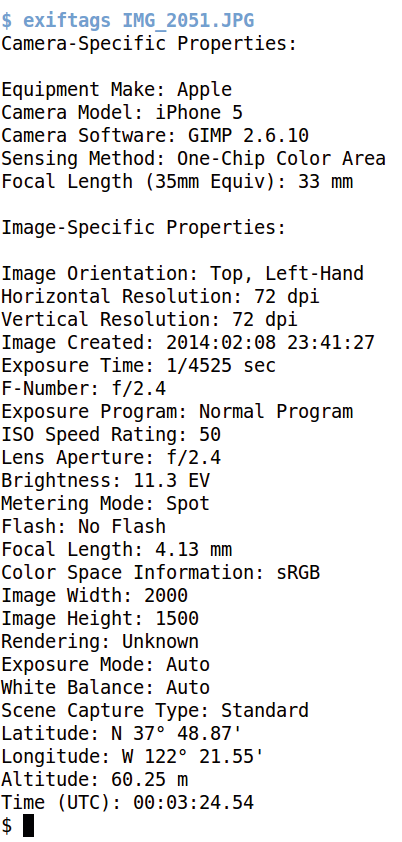
Abbildung 3: Die GPS-Daten des iPhone-Fotos stehen mit 37° 48.87′ nördlicher Breite und 122° 21.55′ westlicher Länge im Exif-Header der Bilddatei.
Moderner Sextant
Die Funktion »photo_latlon()« in Listing 3 liest diese Werte mit dem CPAN-Modul Image::EXIF aus und rechnet sie mit »dm2decimal()« aus dem Modul Geo::Coordinates::DecimalDegrees in Fließkommawerte um. Der reguläre Ausdruck ab Zeile 47 sucht in den Geodaten nach einem Buchstaben (N oder S für nördliche beziehungsweise südliche Breite, W oder E für westliche oder östliche Länge) gefolgt von der numerischen Gradangabe und dem in UTF-8 kodierten Gradsymbol. Nach einem oder mehreren Leerzeichen folgt die Minutenangabe.
So wird aus N 37° 48.87′ der Wert »37.816« und aus W 122° 21.55′ die negative Fließkommazahl »-122.3555« . Google Maps bestätigt in Abbildung 4, dass der talentierte Fotograf beim Auslösen der Kamera tatsächlich in der Mitte der San Francisco Bay auf der Bay Bridge stand. Um herauszufinden, ob im Fotoalbum mehr Bilder liegen, die in einem Umkreis von einem Kilometer aufgenommen wurden, speichert »photo-index« in Listing 4 alle Fotos im Verzeichnis »~/iphone« auf dem eigenen Elasticsearch-Server.
Listing 3
IPhonePicGeo.pm
01 ###########################################
02 package IPhonePicGeo;
03 # Extract decimal GPS location from Photo
04 # Mike Schilli, 2014 (m@perlmeister.com)
05 ###########################################
06 use Image::EXIF;
07 use Geo::Coordinates::DecimalDegrees;
08
09 ###########################################
10 sub photo_latlon {
11 ###########################################
12 my( $pic ) = @_;
13
14 my $exif = Image::EXIF->new();
15 $exif->file_name( $pic );
16 my $info = $exif->get_image_info();
17
18 return if !exists $info->{ Latitude };
19
20 my( $head, $d, $m ) = loc_parse(
21 $info->{ Latitude } );
22 if( $head eq "S" ) {
23 $d = -$d;
24 }
25 my $lat = dm2decimal( $d, $m );
26
27 ( $head, $d, $m ) = loc_parse(
28 $info->{ Longitude } );
29 if( $head eq "W" ) {
30 $d = -$d;
31 }
32 my $lon = dm2decimal( $d, $m );
33
34 return( $lat, $lon );
35 }
36
37 ###########################################
38 sub loc_parse {
39 ###########################################
40 my( $field ) = @_;
41
42 return if !defined $field;
43
44 # Latitude: N 37° 25.16'
45 # Longitude: W 122° 1.53'
46 my( $head, $d, $m ) =
47 ( $field =~ /^(\w) # heading
48 \s+
49 (\d+) # degrees
50 . # degree symbol
51 \s+
52 ([\d.]+) # minutes
53 /x );
54
55 return( $head, $d, $m );
56 }
57
58 1;
Listing 4
photo-index
01 #!/usr/local/bin/perl -w
02 use strict;
03 use File::Find;
04 use Elasticsearch;
05 use IPhonePicGeo;
06
07 my $idx = "photos";
08 my $dir = glob "~/iphone";
09
10 my $es = Elasticsearch->new( );
11
12 eval { # Delete existing index if present
13 $es->indices->delete( index => $idx ) };
14
15 $es->indices->create(
16 index => $idx,
17 body => {
18 mappings => {
19 photo => {
20 properties => {
21 Location => {
22 type => "geo_point" } } } } }
23 );
24
25 find sub {
26 my $pic = $File::Find::name;
27
28 return if ! -f $pic;
29 return if $pic !~ /.jpg$/i;
30
31 my( $lat, $lon ) =
32 IPhonePicGeo::photo_latlon( $pic );
33 return if !defined $lat;
34
35 $es->index(
36 index => $idx,
37 type => "photo",
38 body => {
39 file => $pic,
40 Location => [ $lat, $lon ],
41 },
42 );
43
44 print "Added: $pic ($lat/$lon)\n";
45
46 }, $dir;
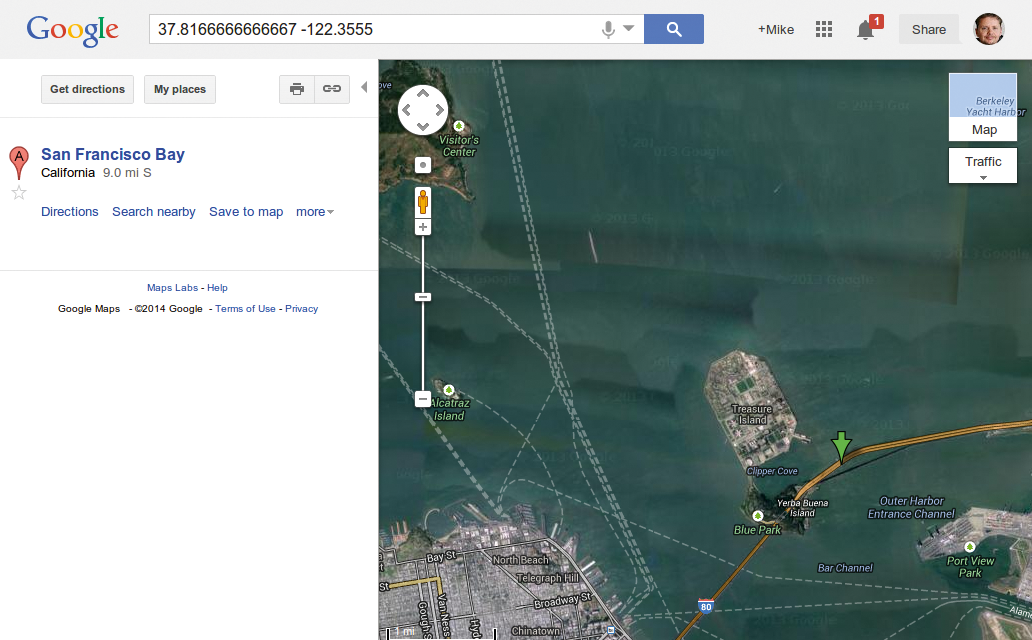
37.816, -122.3555« befindet sich tatsächlich auf der Bay Bridge bei San Francisco.” width=”300″ height=”186″ />
Abbildung 4: Der GeopunktSchöne Gegend
Die Funktion »find()« wühlt sich auch rekursiv durch Unterverzeichnisse. Damit die Suchengine die Geodaten Abfrageperformance-optimiert speichert, ist so genanntes Mapping erforderlich: Zu dem im Index »photos« verwendeten Dokumenttyp »photo« definiert das »create()« -Kommando ab Zeile 15 eine »geo_point« -Property namens »Location« . Die Dokumentation auf [7] ist in diesem Punkt übrigens veraltet und beschreibt ein nicht mehr funktionierendes Mapping. Listing 4 habe ich hingegen erfolgreich mit Elasticsearch 1.0.0 RC2 getestet.
Von den gefundenen Jpeg-Bildern extrahiert Zeile 32 mit dem Modul »IPhonePicGeo« aus Listing 3 die Geodaten und schiebt sie samt Dateinamen im »Body« -Teil der »index()« -Methode ab Zeile 35 in die elastische Datenbank.
Nachdem die Daten aller Fotos archiviert sind, sucht das Skript in Listing 5 Bilder, die ich in einem Kilometer Entfernung zu einem auf der Kommandozeile übergebenen Referenzfoto geknipst habe. Hierzu ermittelt es die Geodaten des Referenzbildes und schickt dann mit dem Query »match_all()« eine Anfrage ab, die alle gespeicherten Bilder zurückliefert. Zeile 23 setzt einen Filter, der die »geo_distance« auf 1 Kilometer limitiert. Zudem vergrößert der Parameter »size« die Maximalzahl der Treffer auf 100.
Zurück kommt eine Liste von Fotos aus der spezifizierten Umgebung, deren Dateinamen die For-Schleife ab Zeile 34 ans Ende eines Array schiebt. Abschließend ruft die »system()« -Funktion in Zeile 40 die Applikation »eog« (Eye of Gnome) auf, die alle Treffer als Thumbnails anzeigt (Abbildung 5). Durch sie darf der User nun nach Herzenslust klicken.
Listing 5
photo-gps-match
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Elasticsearch;
04 use IPhonePicGeo;
05
06 my $idx = "photos";
07
08 my( $pic ) = @ARGV;
09 die "usage: $0 pic" if !defined $pic;
10
11 my( $lat, $lon ) =
12 IPhonePicGeo::photo_latlon( $pic );
13
14 my $es = Elasticsearch->new( );
15
16 my $results = $es->search(
17 index => $idx,
18 size => 100,
19 body => {
20 query => {
21 match_all => {},
22 },
23 filter => {
24 geo_distance => {
25 distance => "1km",
26 "Location" => [ $lat, $lon ],
27 }
28 }
29 }
30 );
31
32 my @files = ();
33
34 for my $result (
35 @{ $results->{ hits }->{ hits } } ) {
36 push @files,
37 $result->{ _source }->{ file };
38 }
39
40 system "eog", @files;
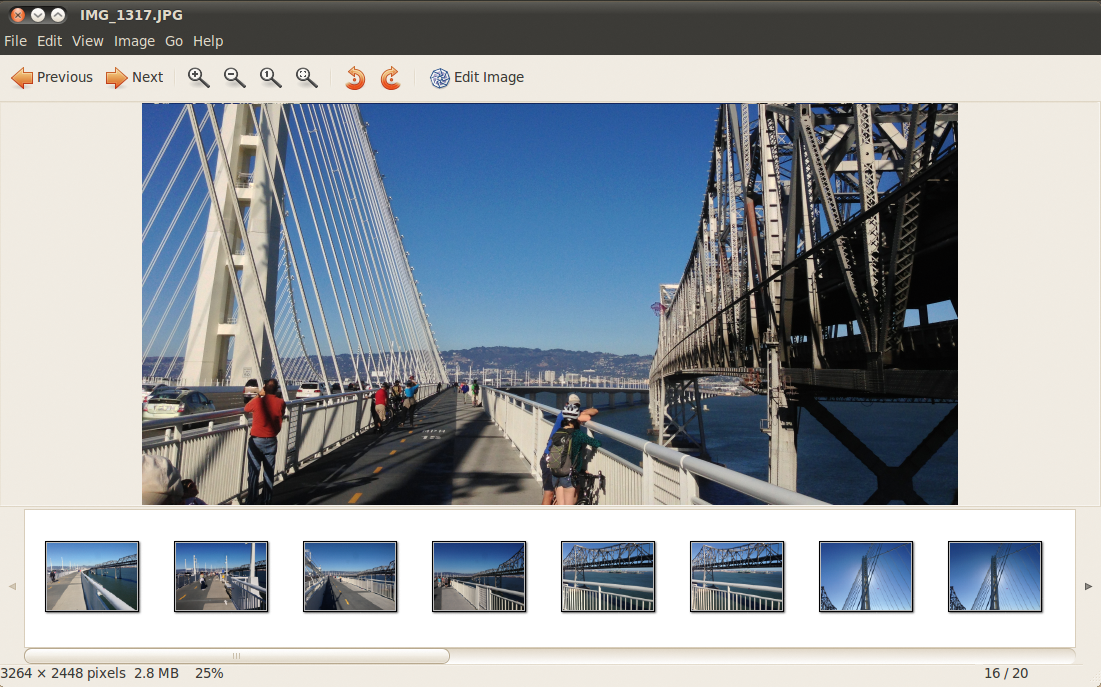
Abbildung 5: In einem Kilometer Umkreis findet Elasticsearch weitere Bilder von der Bay Bridge und stellt sie als Thumbnails für den Nutzer bereit.
Keine Limits
Die Geofunktion ist nur eine von vielen Plugin-ähnlichen Erweiterungen des Elasticsearch-Servers, eines praktischen Werkzeugs, das einfach zu installieren und zu betreiben ist. Außerdem skaliert er praktisch unendlich, denn der Admin kann bei ansteigender Datenmenge die Indexe auf so viele weitere Apache-Lucene-Shards verteilen, bis wieder alle Analysen performant ablaufen.
Zu Elasticsearch existieren Papier- und elektronische Bücher, von denen ich leider keines so richtig empfehlen kann. Aber das Tutorial [9] hilft gewissenhaft weiter und auf Stackoverflow.com beantworten Freiwillige offene Fragen.
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2014/04/Perl
- Download-Seite von Elasticsearch: http://www.elasticsearch.org/overview/elkdownloads/
- »Elasticsearch-1.03« : http://search.cpan.org/~drtech/Elasticsearch-1.03/
- »ElasticSearch-0.66« : http://search.cpan.org/~drtech/ElasticSearch-0.66/
- Michael Schilli, “Kartentrick”: https://www.linux-magazin.de/Ausgaben/2008/08/Kartentrick
- Michael Schilli, “Der Mörder ist nimmer der Gärtner”: https://www.linux-magazin.de/Ausgaben/2007/03/Der-Moerder-ist-nimmer-der-Gaertner
- Elasticsearch Geo Distance Filter: http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-geo-distance-filter.html
- Michael Schilli, “Die neue Bay Bridge über die San Francisco Bay ist endlich fertig”: http://usarundbrief.com/103/p1.html
- Elasticsearch-Tutorial: http://joelabrahamsson.com/elasticsearch-101/
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





