
© gromovataya, 123RF.com
Moderne Dateisysteme mit eingebauter Deduplizierung erkennen doppelt zu speichernde Blöcke und schreiben sie nur ein Mal auf die Platte. Das spart Platz und könnte sogar Geschwindigkeitsvorteile bringen.
Deduplizierung nennt man Mechanismen, die Daten-Redundanzen großen Ausmaßes dazu nutzen, um Speicherplatz zu sparen – eine gute Sache angesichts stetig anschwellender Datenmengen allerorten. Am weitesten verbreitet ist Deduplizierung derzeit bei Backupsystemen [1], sie kommt zunehmend aber auch auf Fileservern zum Einsatz.
Kritiker dagegen sagen, der Aufwand lohne wegen fallender Festplattenpreise nicht. Das Argument ist für den einzelnen PC betrachtet durchaus diskutabel. Auf die IT eines Unternehmens bezogen, ist allerdings anzumerken, dass sich der Erweiterungsaufwand nicht auf den Einbau weiterer Festplatten beschränkt: Es bedarf weiteren Speichers für Backup-Generationen sowie Admins und Software, die den erweiterten Storage verwalten. Außerdem können Platten, die man vermeidet, auch nicht ausfallen.
Es gibt darum genug Gründe, sich mit Entvielfältigung zu befassen. Dieser Artikel jedenfalls tut es, zumal Linux Admins eine Gruppe von Dateisystemen aufs Tablett legt, die Deduplizierung auf ihrer Featureliste stehen haben.
Doppeltes an der Quelle
Es gibt mehrere Spielarten von Deduplizierung. Man kann Daten an der Quelle, also in der Anwendung, deduplizieren oder am Ziel, auf dem Datenträger. Erstere Methode besitzt den charmanten Nebeneffekt, die Übertragungskanäle zu entlasten – egal ob es sich um das Netzwerk oder die SATA- beziehungsweise SAS-Verbindungen handelt. Dazu muss sich die Applikation aber selbst ums Deduplizieren kümmern.
Das klappt bei den Programmgattungen ganz hervorragend, deren Funktionsweise sowieso in Richtung Deduplikation geht wie Versionskontrollsysteme, Backup-Software oder Virtualisierungen, die alle tendenziell die Hauptdaten nur ein Mal ablegen und anfallende Varianten als Diffs speichern. Die technische Basis dahinter ist Copy-on-Write. Es steckt übrigens hinter vielen anderen Features, die Speichersysteme kennen, wie Snapshots, Schattenkopien oder Versionierung. Wenn Deduplizierung nur das vielfache Speichern ganzer Dateien verhindern soll, spricht man auch vom Single Instance Storage, SIS.
Ein großes Potenzial fürs Deduplizieren besitzt übrigens Groupware: Wenn Benutzer A eine Mail mit Anhängen an Benutzer B, C, D und so weiter schickt, braucht der Server alle Inhalte eigentlich nur in einfacher Ausführung in seinem Mailstore vorzuhalten.
IT-geschichtlich betrachtet war das Platzsparen bereits auf Großrechnern früherer Tage mit ihren autarken Speichersystemen en vogue. Sie vermochten schon komplette Datenbestände zu klonen. Intern legten sie dazu einen neuen Satz Zeiger auf diese Daten an und täuschten die Verdoppelung der Nutzdaten-Menge nur vor. Spätere Änderungen an den Daten speicherten sie einfach getrennt davon.
Das Ziel ist das Ziel
Die zweitbeste Variante ist das Deduplizieren am Ziel, also am Speichort. Dateisysteme und damit die Testkandidaten dieses Artikels gehören in diese Schublade. Anders als bei Deduplikation an der Quelle weiß das Ziel zunächst nichts über die nichts über die Struktur der Daten, die es speichern soll. Es muss sie folglich analysieren, was einerseits weniger effektiv und andererseits rechenaufwändig ist. Andererseits eignet sich die Methode für Daten jeder Art.
Auch von der Deduplikation am Ziel gibt es zwei Varianten: Online und offline. Die Begriffe sind etwas verwirrend. Gemeint ist, ob bereits während des Schreibvorgangs dedupliziert wird oder nicht. Es während des Schreibens zu tun besitzt den Vorzug, dass es auch gleich erledigt ist und so von vornherein klar feststeht, wie viel Platz das Speichern erfordert.
Allerdings geht dies heftig zu Lasten der Gesamtperformance, denn noch vor dem Schreiben auf den Datenträger muss die Deduplizier-Engine permanent die Hashes errechnen und mit denen vorhandener Blöcke vergleichen. Das erfordert CPU-Leistung und die Möglichlkeit, große Teile der Datenbank im RAM vorzuhalten, in denen sich der Deduplizierer merkt, welche Teile der Daten bereits auf der Festplatte vorliegen.
Offline arbeitende Deduplizierer schreiben dagegen mit maximaler Geschwindigkeit auf das Medium und deduplizieren erst später. Hauptnachteil ist hier, dass die Platzersparnis erst im Nachgang erreicht wird. Das führt unter anderem zu dem Effekt, dass der Benutzer den Inhalt eines gut gefüllten Volumes nicht auf ein gleich großes zweites Volume kopieren kann, eben weil das Zielmedium anfangs die rohen Daten aufnehmen muss.
Anders als Komprimierung
Deduplizierung ist leicht mit Kompression zu verwechseln, und in der Tat gibt es das gemeinsame Ziel, die Datenmenge zu verringern. Bei Kompression durchsucht ein Algorithmus die Daten eines Blocks nach wiederkehrenden Mustern. Anschließend ersetzt er häufig auftretende, lange Muster durch kurze und selten auftretende durch lange. Das reduziert Speicherplatz und nutzt dabei auch kleine Sparmöglichkeiten. Dem stehen als Nachteil der hohe Rechenleistungsbedarf und die Tatsache gegenüber, dass Dubletten kompletter Dateien oder ganzer Ketten von Datenblöcken nicht oder kaum entvielfältigt werden.
Ziel-Deduplikation dagegen sucht mit Hilfe von Hashes nach ganzen Speicherblöcken, die mehrfach auftreten, um sie nur einmal zu speichern. Dabei ist es egal, ob die Dubletten zur selben oder zu verschiedenen Dateien gehören. Die Kunst liegt nun darin, geeignete Blockgrößen oder Chunks zu finden, die maximale Ergebnisse liefern, ohne dabei zu viel CPU-Zeit beim Berechnen der Hashes zu verbraten.
Deduplizierung erzeugt also nicht aus einer großen ein kleine Datei, es ändert nur die Art und Weise sie zu speichern (Abbildung 1). Dabei ist von allergrößter Wichtigkeit, dass die Metainformationen über das Wie niemals beschädigt werden. Erwischt es die Tracking-Datenbank doch, gehen Daten verloren.
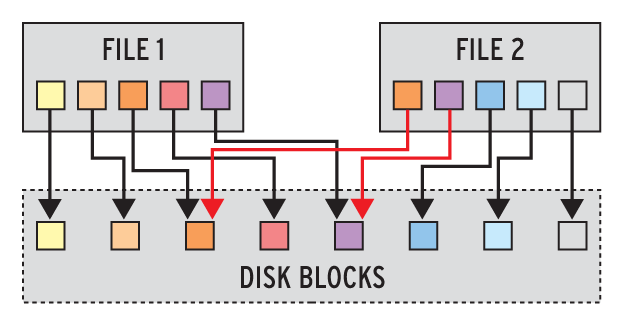
Abbildung 1: Deduplikation speichert doppelte Blöcke in Dateien nur einmal auf dem Datenträger.
Wirksamkeit ist nicht vorhersagbar
Noch viel schwieriger als bei der Datenkompression ist es, die Effektivität von Deduplizierungsmaßnahmen vorherzusagen, da die Abhängigkeit von den zu bearbeitenden Daten und deren Redundanzen extrem ist. Hier muss der Anwender wohl oder übel selbst anhand seiner Realdaten testen. Handelt es sich um Binärdaten, oder gibt es verschiedene Generationen von ansonsten ähnlichen Daten? Perfekt deduplizierbar sind etwa Vollbackups – weshalb die Technik hier auch so weit verbreitet ist. Alle Daten, die keiner seit dem letzten Backup angefasst hat, sind Dubletten und eignen sich ideal zum Entvielfältigen.
Das Linux-Magazin hat drei Dateisysteme einem simulierten Praxis-Kurztest unterzogen (siehe Kasten “So haben wir getestet”). Ins Rennen gingen ZFS, Btr-FS und das Less-FS. Ihre Konzepte und ihr Reifegrad sind denkbar unterschiedlich, was auch der Test offenbart.
So haben wir getestet
Basis für die Messungen war ein nagelneuer Minitower von Fujitsu, ein Esprimo P910 D3162 mit Intel i5-3470. Vier Kerne mit 3,2 GHz, die über 8 GByte RAM gebieten. Als Festplatte diente eine 500 GByte fassende Western Digital WD5000KS mit SATA-II. Da das Testsystem mit nur einer Platte ausgestattet war, liefen Lesen und Schreiben über dasselbe Interface, was die Messergebnisse in ihrer Relation praktisch nicht beeinflussen konnte.
Neben den Partitionen für ein Linux Mint 13 LTS (Cinnamon, 64 Bit) und dessen Swapspace richteten die Tester drei Partitionen mit 150 GByte ein. Eine trug die zusammengestellten Testdaten (auf Ext 4), die anderen beiden waren die Zielpartitionen, formatiert mit den zu bewertenden Dateisystemen.
Es war nötig, den Kernel manuell auf 3.11.0.14 zu erneuern, um File-Locking-Mechanismen für Bedup zu erhalten. Mit dem originalen Kern erkannte Bedup die Btr-FS-Laufwerke nicht. ZFS haben die Tester als Paket einfach per Synaptic installiert und den Pool mit dem Parameter »dedup« eingerichtet. Für Btr-FS holten sie manuell das Bedup-Paket ins System.
Die Tests kopierten skriptgesteuert einzelne Verzeichnisse mit verschiedenen Arten von Realdateien:
- Movie: 169 kaum komprimierbare Dateien mit TV-Transportstromaufnahmen und 68?830?516 KByte Gesamtgröße,
- Bilder: 123 788 Jpeg-Dateien mit 49?864?136 KByte Gesamtgröße, die einzeln nicht komprimierbar waren, aber viele Dateien-Doubletten enthielten,
- Text: Kernel mit 1?337?727 Linux-Kernel-Sourcedateien mit 17?390?984 KByte Gesamtgröße, die sich hervorragend (10:1) komprimieren lassen und zusätzlich teils mehrfach redundant platziert wurden, um den Deduplizierern Chancen einzuräumen.
Die Deduplizierbarkeit eigener Nutzdaten kann der Anwender versuchen grob in dieses Dreier-Raster und deren ermittelten Ergebnisse (Abbildung 3) einzuordnen. Zum Vergleich von Deduplizierung zu klassischer Komprimierung haben die Tester noch eine Referenzmessung mit den Daten per Zip absolviert.
Abgesehen vom instabilen Less-FS absolvierten die Tester die Kopiervorgänge in drei Durchläufen: Einen von einer nicht-deduplizierenden Partition (Ext 4) auf die mit dem deduplizierenden Testkandidaten, einen von Testkandidat zu Testkandidat (doppelt dedupliziert) und einen von der Kandidaten- auf die Ext-4-Partition. Abbildung 3 zeigt die drei Messungen als direkte Nachbarschaft von drei Balken.
ZFS
Der erste Kandidat, ZFS [2], gilt auf die Gesamfunktionen bezogen als das derzeit ausgereifteste Dateisystem neuer Prägung. Ursprünglich von Sun (später Oracle) entwickelt für Solaris als Speichersystem der Zukunft (daher der Name Zettabyte Filesystem: das sind 1021 oder 270 Bytes), ist es in mehreren Implementierungen für Linux verfügbar.
Da aber die Lizenz nicht GPL-kompatibel ist, wird ZFS möglicherweise nie Teil des offziellen Kernel und erfüllt Teile seiner Funktionen vom Userspace aus. Dennoch ist der Funktionsumfang so gewaltig, dass man ohne Übertreibung von einem eigenen kleinen ZFS-Universum sprechen darf [3, 4]. ZFS ist nicht nur ein Dateisystem, sondern auch Logical Volume Manager und Software-Raid – und dazu noch prüfsummenüberwacht. Zudem wartet ZFS mit vielen Tools auf, etwa mit »zdb« , dem ZFS-Debugger. Der ist sehr mächtig und dient dazu, unter Anleitung eines Admins Statistiken zu erheben und Fehler zu erkennen. Für die meisten Alltagsprobleme, so die Dokumentation, verhält sich ZFS als selbstheilend.
ZFS macht den Job des Deduplizierens sehr, sehr gründlich – auf Blockebene, voreingestellt sind 128 KByte. Allerdings geht dies in den Standardeinstellungen schwer auf die Performance wie der Vergleich der Datendurchsätze in Abbildung 3 zeigt. Im Bestfall verliert sie drei Fünftel Durchsatz, im schlimmsten Fall, viele kleine Dateien, sogar acht Neuntel. Gerade im Verhältnis zu Ext 4, das den nicht-deduplizierenden Standardfall eines Fileservers simuliert, erweist sich ZFS als ausgesprochen lahm.
Andererseits: Nach Less-FS, das aber mit Stabilitätsproblemen kämpft, spart ZFS beim Deduplizieren den meisten Platz (Abbildung 2). In der Praxis lässt sich das gefahrlos nutzen: Da ZFS online dedupliziert, kann man in eine solche Partition Gigabyte um Gigabyte hineinkopieren, ohne dass zeitverzögert unerwartete Effekte passieren. Die Tester haben spaßeshalber den Movie-Ordner mit 65 GByte ein zweites Mal in das ZFS-Ziel kopiert, und danach waren immer noch 22 GByte frei – das Dateisystem konnte die neuen Daten fast komplett deduplizieren. Leider profitiert die Performance von den statistisch selteneren Plattenzugriffen nicht, wie schon erläuert. Der Verwaltungsaufwand beim Deduplizieren scheint merklich größer als anfangs gedacht.
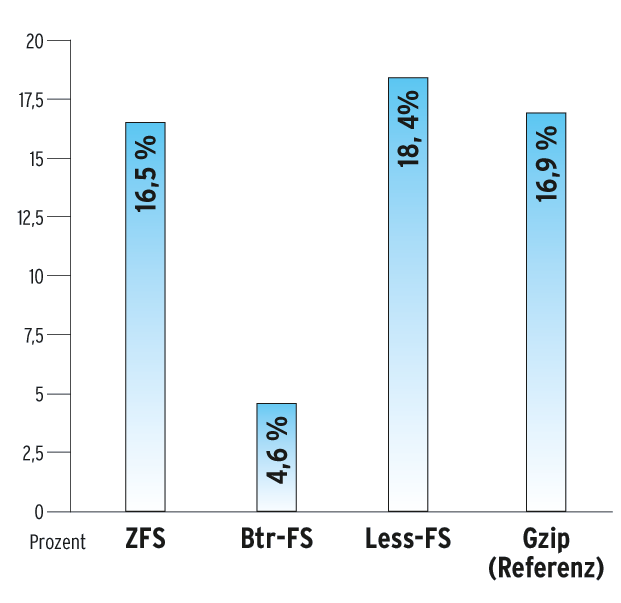
Abbildung 2: Eingesparter Platz
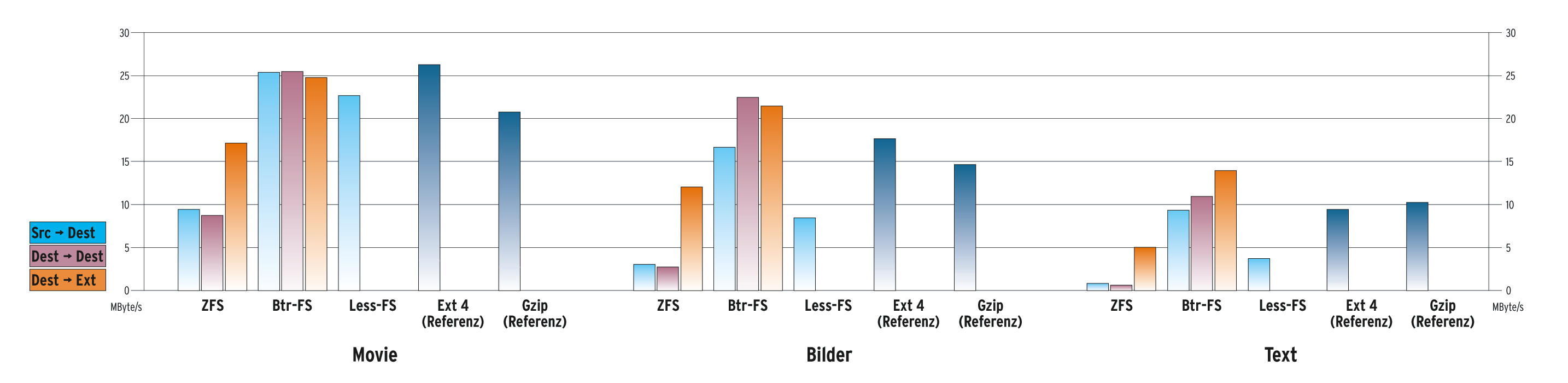
Abbildung 3: Erzielte Durchsätze mit drei Datenarten
Btr-FS
Eigentlich B-Tree Filesystem, meist aber “Better Eff Ess” ausgesprochen, kommt Btr-FS [5] bei Linux Mint 13 Maya LTS gleich von Haus aus und im anwendungsbereiten Zustand mit. Die Entwicklung begann 2007 durch Oracle, und sollte von Anfang an, anders als Suns ZFS, Linux bedienen. Es gibt auch kein Lizenzproblem, da Btr-FS unter GPL steht. Folglich ist es längst in den Vanilla-Kernel integriert, was der Performance zu Gute kommt. Nett ist, dass es einen Konverter gibt, der ein Laufwerk mit Ext 3 oder Ext 4 nach Btr-FS wandeln kann. Hinzu kommen einige Tools zum Prüfen aber auch Reparieren des Dateisystems.
Btr-FS strebt ähnliche Ziele an wie ZFS: Copy-on-Write, Prüfsummen, Schnappschüsse, dynamische erzeugte Inodes, integriertes Raid. Mit der B-Baum-Struktur übernimmt es auch ein Feature von XFS, das einst Silicon Graphics für das hauseigene Irix entwickelt hatte.
Allerdings gilt das Dateisystem nach wie vor als experimentell. Die Deduplizierung ist im Test nicht im Umfang der Mint-Distribution, die Tester installierten das Feature über den in [5] beschriebenen Mechanismus nach. Die erste Messung (von der Quelle zum ersten Ziel) ist daher ohne Deduplizierung. Wird von Ziel 1 auf Ziel 2 kopiert, ist das zweite Ziel auch erst einmal nicht dedupliziert. Der Vorgang dauerte genauso lange wie beim ersten Ziel.
Das Btr-FS-Dedupliziertool Bedup erwies sich als ausgesprochen performant, mit wenigen Minuten Laufzeit (zwei Drittel der zirka 6 Minuten waren für den Scan, ein Drittel für das Deduplizieren). Das liegt allerdings auch an der Defaulteinstellung, in der Bedup nur Dateien bearbeitet, die größer als 8 MByte sind. Der Admin kann diesen Wert senken, dann bricht aber der Datendurchsatz ein. Die Kehrseite der wirklich guten Performance ist ein maues Deduplizierergebnis: Btr-FS lässt die allermeisten Kernel-Source-Dateien und auch viele Jpegs (ihrer Größe wegen) beim Deduplizieren aus. So spart es nur ein Drittel des Platzes gegenüber ZFS ein.
Less-FS
Mark Ruijters Less-FS [6] verhält sich in vielerlei Hinsicht anders als die beiden anderen Kandidaten. Als Fuse-System legt es sich transparent über das Filesystem. Der Admin definiert also nicht eine Partition als Less-FS und mountet sie dann, sondern er definiert eine Datenbank, die die Daten tragen soll, und weist dieser dann einen Mountpunkt zu.
Will er eine Partition und nicht das ganze Filesystem einsetzen, so muss er die Datenbank in diese Partition legen, die er normal (mit Ext) formatiert. Dann erzeugt der Admin die Datenbank und definiert einen Einhängepunkt. Die genaue Prozedur beschreibt ein Linux-User-Artikel [7]. Wichtig ist, dass man die Datei »/etc/lessfs.cfg« bearbeitet und die Datenbank passend verlegt.
Ruijters, der Autor von Less-FS, möchte von seiner bisherigen Exoten-Datenbank Tokyo Cabinet weg. Derzeit ist diese aber noch die Default, weshalb der Test auch damit gelaufen ist. Tipp: Die »lessfs.cfg« ist ein wenig chaotisch aufgebaut und weist einige Doppler auf. Am besten zieht man sich eine Beispieldatei aus dem Tar-Archiv des Beispiels für Tokyo Cabinet und korrigiert nur den Speicherort der Datenbank. Wer hier schlampig arbeitet, dessen Less-FS verabschiedet sich kommentar- und fehlermeldungslos.
Die Performancewerte von Less-FS sind in Ordnung und liegen zwischen einem reinen Kopieren auf Btr-FS mit nachgelagerter Deduplizierung und vor ZFS. In der Kategorie eingesparter Plattenplatz kauft Less-FS sogar dem Platzhirsch ZFS den Schneid ab (um zehn Prozent bessere Einsparung).
Das Wunderkind zeigte im Test aber eine dunkle Seite: Der Versuch, die umfangreichen Testdaten von einem Less-FS in ein anderes Less-FS zu kopieren, quittierte das System reproduzierbar mit einen Aufhänger mitten im »cp -R« . Anschließend ließ sich weder der »cp« -Prozess killen noch ein ordentlicher Umount bewerkstelligen. Schlimmer noch: Nach einem Reboot waren beide Less-Filesysteme, also Ziel und sogar die Quelle, zerstört.
Weitere Tests ergaben, dass sich diese Zerstörung selbst zwar vermeiden lässt, wenn man das Less-FS nach dem Beschreiben umountet und den Rechner bootet, damit wirklich alle Schreibvorgänge commited sind. Aber das Auslesen des Volume klappt dann immer noch nicht. Das Fehlen von Selbstheilungs- oder Reparaturmechanismen setzt dem Effekt die Krone auf.
Ein Gegentest mit nur 4 GByte Daten verlief völlig reibungslos – entweder hat Less-FS in der aktuellen Version 1.7.0 ein Problem mit der Anzahl Dateien oder der Gesamtgröße. Beides ist für eine Infrastruktur nicht tragbar. Trotz einer umfangreichen Diskussion mit dem Less-FS-Programmierer Mark Ruijters ließ sich das Problem bis zum Redaktionssschluss dieser Ausgabe nicht beheben.
Wertung und Fazit
Online-Deduplizierung frisst mächtig Performance und will gut überlegt sein. Offline-Deduplizierung ist jedoch nur in abgegrenzten Einsatzbereichen wirklich leistungsfähig. Wer jedoch den Schwellwert zu niedrig ansetzt, ruiniert schnell den Hauptvorteil der Offline-Deduplizierer: ihren geringen Leistungsverlust. Da das Ganze zudem von der Struktur der zu speichernden Daten dominiert ist, sollte jeder vorab eigene Tests durchführen.
Beim Test im Rahmen dieses Artikels erwies sich Less-FS als instabil und bot zugleich keine Reparaturmöglichkeiten an, um beschädigte Datenbanken zu reparieren – eine tödliche Kombination. Eigentlich sind Journals schon seit so langer Zeit Standard. Hier muss vor dem Einsatz in einem produktiven Bereich gewarnt werden. Es hat Potenzial, aber noch ist dieses Dateisystem zu experimentell.
Offiziell gilt das auch für Btr-FS. Das Filesystem selbst ist schon sehr stabil – nicht jedoch der Deduplizierer, der offline arbeitet. Btr-FS profitiert davon, nicht wie ZFS über Fuse laufen zu müssen. Gleichwohl zeichnete ZFS im Testfeld das erwachsenste Bild von sich.
Wer im Produktivbetrieb Deduplizieren will, sollte sich noch eines Umstandes bewusst werden: Verringerte Redundanz geht grundsätzlich mit einem gewissen Verlust von Sicherheit einher (siehe Kasten “Datensicherheit”).
Ratsam erscheint daher, je nach Inhalt der zu speichernden Daten eine Misch-Strategie zu fahren, bestehend aus Deduplizerung und klassischer Komprimierung. Letztere ist bei vielen kleinen Dateien wirksamer. Komprimieren können moderne Dateisystem sowieso schon länger, sodass man sich den Umweg über Zip und Co. sparen kann.
Oder man entscheidet sich, einfach mit dem Mehrverbrauch an Festplatten zu leben. Alternativen bilden ein NAS oder SAN, die gegebenenfalls eigene proprietäre Deduplikationstechniken anwenden, für die dann aber der Anbieter das SLA unterschreiben muss.
Datensicherheit
Deduplizierende Dateisysteme bergen zwei Gefahren: Das Verringern von Redundanz bedeutet immer eine Erhöhung des Risikos eines Datenverlustes. Die Frage ist, auf welchem Niveau sich das abspielt, und ob ein solches Risiko noch im annehmbaren Bereich liegt.
Gegen direkte Beschädigungen des Filesystems beziehungsweise der damit verbundenen Datenbank hilft, wie immer, eine ordentliche Backup-Strategie. Der Admin muss dabei aber beachten, dass ein Vollbackup aus einem deduplizierten Filesystem unter Umständen den mehrfachen Platz verbraucht als das zu sichernde Volume belegt hat.
Gegen die zweite Gefahr hilft allerdings keinerlei Backup. Deduplizierende Filesystems erkennen doppelte Verwendung von Datenblöcken anhand von Hashes. Auch wenn es statistisch ein äußerst seltenes Ereignis ist, Hash-Kollisionen – ausgelöst dadurch, dass zwei unterschiedliche Datenblöcke den gleichen Hash erzeugen – sind möglich. Sofern ein deduplizierendes Filesystem nicht mit besonders sicheren Algorithmen oder zusätzlichen Kontrollen arbeitet, so können hier Daten verloren gehen. Perfiderweise hilft dagegen ein Backup nicht; es sein denn, man backupt die Daten bevor das Dateisystem sie dedupliziert.
Auch hier muss jeder abwägen, ob er das Risiko eingehen kann. Die Autoren deduplizierender Filesystems behaupten, das Risiko eines Datenverlusts durch Kollision läge unterhalb des Risikos, Daten durch Hardwareausfall zu verlieren. Ob dies stimmt, lässt sich nicht prüfen.
Infos
- Jens-Christoph Brendel, “Das neue Feature Deduplizierung bei SEP sesam”: Admin-Magazin 01/14, S. 30
- ZFS: http://zfsonlinux.org
- Hans-Peter Merkel, Markus Feilner, “Erste Begegnung zwischen dem Linux-Kernel und ZFS”: Linux-Magazin 02/11, S. 86
- Stefan G. Weichinger, “Workshop: Rechner mit LUKS und ZFS on Linux komplett verschlüsseln”: Linux-Magazin 01/13, S, 62
- Btr-FS: http://btrfs.wiki.kernel.org
- Less-FS: http://www.lessfs.com/wordpress/
- Tim Schürmann, “Schrumpfkur”: Linux User 11/10, S. 78, http://www.linux-com-munity.de/Internal/Artikel/Print-Artikel/LinuxUser/2010/11/Das-deduplizierende-Dateisystem-LessFS/
Der Autor

Oliver Kluge ist ITIL-geprüft und zertifizierter Qualitätsmanagementbeauftragter und -Auditor (QMB/QMA) nach ISO 9001. Er ist verantwortlich für das technische Qualitätsmanagement in der IT des Flughafens München und leitet dort das Testlabor. Er arbeitet auch als Problem Manager und berät IT-Abteilungen anderer Flughäfen in vielen Ländern der Welt. Kluge hat Informatik studiert, war Redakteur bei großen PC-Zeitschriften und 2001 beim Linux-Magazin Leiter des damaligen Competence Center Hardware.





