
© gary718, 123RF.com
Mongo DB ist ein Musterexemplar unter den NoSQL-Datenbanken: Die Open-Source-Software hat zeitgemäße Features wie Replikation, Failover und Sharding bereits eingebaut. Der Autor setzt die Datenbank schon seit 2009 produktiv ein und breitet seinen Erfahrungsschatz aus.
Es gibt viele Datenbanken, die sich mit dem Etikett NoSQL schmücken. Dazu gehört auch die dokumentenorientierte Mongo DB. Der Hersteller 10gen versorgt die Open-Source-Software außerdem mit Enterprise-Support und bezeichnet sie als führende NoSQL-Datenbank [1]. Wer im Web nach Mongo DB sucht, findet allerdings ein breites Spektrum von Stimmen: Es reicht von fantastischen Behauptungen über die Skalierbarkeit der Datenbank [2] bis zu bitter enttäuschten Erwartungen [3].
Positive Erfahrungen
Das Unternehmen des Autors kann mehr als vier Jahre Erfahrung beim operativen Betrieb der Software vorweisen. Anfang 2009, noch vor der Mongo-DB-Release 1.0, hat es eine produktive Anwendung von MySQL auf die NoSQL-Datenbank umgestellt. Heute verarbeitet die Installation monatlich 20 TByte Daten. Dieser Artikel berät Umstiegswillige und vermittelt Erfahrungen aus der eigenen Betriebspraxis.
Ebenso wie MySQL, PostgreSQL und andere Datenbanken ist auch Mongo DB nicht an eine bestimmte Programmiersprache gebunden und kommuniziert über ein eigenes Protokoll mit den Anwendungen. Wie andere NoSQL-Datenbanken bietet Mongo DB zwar auch ein REST-API für den Zugriff über HTTP [4], doch Spezialtreiber bieten bessere Performance und eine sinnvolle Implementierung der Abfragesprache.
Offizielle Mongo-DB-Treiber [5] gibt es für zahlreiche Programmiersprachen, darunter C, C++, C#, Erlang, Java, Javascript, Node.js, Perl, PHP, Python und Ruby (Abbildung 1).
Abbildung 1: Für Mongo DB existieren zahlreiche Treiber und Clientbibliotheken in Programmiersprachen von C, Perl und PHP bis Erlang, Ruby und Scala.
Dass Mongo DB im Quelltext unter der AGPL vorliegt und offen spezifiziert ist, eröffnet zudem die Möglichkeit, eigene Clientsoftware zu programmieren. In der Regel sind die von 10gen unterstützten Treiber aber besser getestet, vor allem bei hohem Durchsatz. Support und Maintenance sind insbesondere im Produktiveinsatz wünschenswert.
Schemafrei mit Grenzen
Mongo DB ist schemafrei: Der Anwender braucht wie bei anderen NoSQL-Datenbanken vor ihrem Einsatz kein Schema festzulegen, was bei relationalen Datenbanken wie MySQL anfänglich oft einen großen Aufwand verursacht. Die Dokumente in Mongo DB bestehen schlicht aus Json-Code und lassen sich ad hoc verändern. Dabei dürfen sie Elemente wie Arrays oder Timestamps enthalten, ja sogar andere Dokumente [6].
Das bedeutet aber nicht, dass der Mongo-DB-Anwender sich keine Gedanken über die Gestaltung der Dokumente machen sollte. Besonders wenn diese an Umfang zunehmen, drohen Performance-Probleme. Fügt man neue Felder hinzu oder wächst die Größe (etwa die Summe der Feldnamen und -werte) eines Dokuments über den zugewiesenen Speicherplatz hinaus, speichert Mongo DB das Dokument an einer anderen Stelle der Datei.
Das beeinträchtigt allerdings die Performance, denn die Software muss die Daten neu schreiben – Updates an Ort und Stelle sind schneller. Geschieht das Neuschreiben häufig, passt Mongo DB automatisch ihren Padding-Faktor [7] an und räumt Dokumenten von Haus aus mehr Platz ein.
Wirtschaftliche Updates
Eine Methode, um sicherzustellen, dass die Datenbank die Aktualisierung ohne kostspielige Schreibvorgänge vornimmt, besteht darin, lediglich jene Felder, die man ändern möchte, anzugeben und möglichst Modifier zu verwenden. Anstatt ein komplettes neues Dokument zu schicken, ändert oder löscht das Statement nur einzelne Felder. Die folgende Query auf der »mongo« -Konsole (Abbildung 2) führt ein »cats« -Feld ein und füllt es mit »5« . Daneben aktualisiert sie den Inhalt des »hats« -Felds auf »2« :
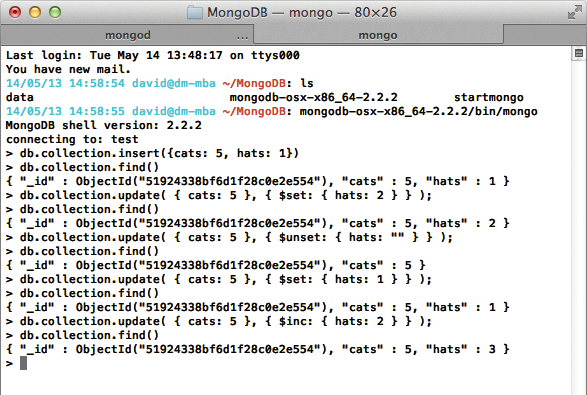
Abbildung 2: Mongo-Konsole: Gezielte Updates einzelner Felder mit »$set«, »$unset« und »$inc« schonen die Ressourcen.
db.collection.update( { cats: 5 },{ $set: { hats: 2 } } );
Statt das Feld »hats« auf einen neuen Wert zu setzen, könnte der Anwender es auch mit dem Modifier »$inc« inkrementieren. Angenommen der aktuelle Wert sei »1« , dann erhöht das folgende Kommando ihn um »2« auf »3« :
db.collection.update( { cats: 5 },{ $inc: { hats: 2 } } );
Das folgende Kommando entfernt das Feld »hats« aus dem Dokument:
db.collection.update( { cats: 5 },{ $unset: { hats: "" } } );
Diese Operationen sind effizienter sowohl bei der Kommunikation mit der Datenbank als auch bei Schreiben der Datei. Daneben kann selbst eine Änderung am Datentyp eines Felds Mongo DB veranlassen, die Datei neu zu schreiben. Das kann etwa durch eine Änderung von »(float)0.0« zu »(int)0« geschehen. Daher ist es wichtig, die Spezifikation von Bson [8], des von Mongo DB verwendeten binären Json-Formats, zu beachten.
Server Density, das Monitoringprodukt des Autors, verarbeitet Milliarden von Datensätzen, die beim Überwachen der Kundenserver und -Anwendungen anfallen. Damit die Kunden rechtzeitig Benachrichtigungen und Warnungen erhalten, muss das Monitoringsystem zuverlässig laufen. Zu diesem Zweck ist Replikation zwischen verschiedenen Rechenzentren erforderlich. Als der Autor noch MySQL einsetzte, war es schwierig, Replikation und Failover einzurichten.
Replica Sets
Mongo DB hat die Mittel dazu bereits eingebaut: Replica Sets. Dabei handelt es sich im Prinzip um ein Master-Slave-Setup, das aber ein Minimum von drei Knoten voraussetzt. Jeder Knoten kann in der Standardkonfiguration zum Master werden. Die Instanzen kommunizieren laufend über ein Heartbeat-Protokoll. Stellt das Set fest, dass der derzeitige Master ausgefallen ist, befördert es ein anderes Mitglied zum Chef. Das geschieht automatisch, auch die Clients ziehen mit. Der Admin hat die Wahl, ob er eine Fehlermeldung ausgeben möchte oder ob der Verbund einfach stillschweigend weiterarbeiten soll.
Die Einrichtung erfordert im Standardfall nur wenig Aufwand. Das Mongo-DB-Handbuch kennt aber noch weitere Optionen [9]. Der Admin kann
- definieren, welche Knoten Master werden und in welcher Reihenfolge,
- Knoten verbergen, sodass sie Kopien der Daten anlegen, aber nie Master werden,
- ohne oder mit minimaler Auswirkung auf das Set Knoten hinzufügen oder entfernen,
- einige Knoten so konfigurieren, dass ihr Datenbestand eine bestimmte Zeit hinter dem Master zurückbleibt (als Backup für gelöschte Datenbanken oder ähnliche Notfälle),
- kleine Knoten aufsetzen, die an der Mehrheitswahl des Masters teilnehmen, aber selbst keine Daten speichern (um bei Netzwerkproblemen eine Mehrheit zu gewährleisten).
In einem Master-Slave-Setup hält der Slave stets mit dem Datenbestand des Masters mit. Die Skalierung von Lesevorgängen aktiviert der Admin, indem er die Option »setSlaveOk« verwendet, die alle Clientbibliotheken kennen. Er veranlasst Mongo DB dazu, die Reads automatisch auf dem nächstliegenden Replica-Slave auszuführen. Die Laufzeit von Pings bestimmt, welcher das ist. Dessen Datenbestand kann dabei zeitweise vom Master abweichen, wenn er aufgrund von Latenz und Durchsatz in der Produktionsumgebung die jüngste Synchronisation noch nicht ausgeführt hat.
Konsistenz
Dieser Effekt lässt sich beim schreibenden Zugriff durch den so genannten Write Concern eindämmen. Dieser Wert beträgt standardmäßig 1, was bedeutet, dass der Schreibaufruf nicht zurückkehrt, bevor der Server das Schreiben nicht bestätigt hat. Um ein gewünschtes Maß an Replikation und Konsistenz zu gewährleisten, kann der Admin die Bestätigung durch n Slaves verlangen. Der Write Concern (Tabelle 1) kann eine Ganzzahl enthalten, das Keyword »majority« (Mehrheit) oder ein selbst definiertes Tag.
Tabelle 1
Write Concern
|
Wert |
Wirkung |
|---|---|
|
-1 |
Deaktiviert alle Bestätigungen und Fehlermeldungen |
|
Deaktiviert alle Bestätigungen, meldet aber Netzwerkfehler |
|
|
1 |
Aktiviert einfache Bestätigung des Schreibvorgangs (Standardeinstellung) |
|
n > 1 |
Verlangt Bestätigung, dass der Schreibvorgang n Mitglieder des Replica Set erreicht hat |
|
»majority« |
Verlangt Bestätigung, dass der Schreibvorgang die Mehrheit des Replica Set erreicht hat |
|
Tag-Name |
Selbst definierte Regel (siehe Lauftext) |
Dabei fordert jede Steigerung der Konsistenz Opfer in Sachen Performance [10], da das Warten auf die Schreibbestätigungen Zeit in Anspruch nimmt. Es ist wichtig zu verstehen, dass eine Bestätigung nicht mit dem erfolgreichen Schreiben gleichzusetzen ist. Sie bestätigt lediglich, dass der Knoten den Schreibauftrag angenommen hat.
Der nächste Schritt in der Verarbeitungskette ist das Eintragen in das lokale Mongo-DB-Journal des Knotens, in dem alle Schreibvorgänge landen, bevor sie schließlich auf der Festplatte ausgeführt werden. Erreicht ein Schreibauftrag das Journal, liegt er aber schon so gut wie auf der Platte.
Durch diese Verfahrensweise lassen sich unterschiedliche Stufen der Zuverlässigkeit umsetzen. Bei einer Logging-Anwendung mit hohem Durchsatz wäre es beispielsweise keine Katastrophe, wenn ein paar Schreibvorgänge auf der Strecke blieben – aber nur dann, wenn sie nicht die Konfiguration der Warnungen betreffen. Die flexibelste Konfiguration der Replikation ermöglichen Tags [11]. Zudem lassen sie sich in der Datenbank konfigurieren und bleiben damit sauber getrennt vom Anwendungscode.
Flexibel: Tagging
Als Beispiel soll ein Replica Set mit zwei Knoten in New York, zwei in San Francisco und einem bei einem beliebigen Cloudanbieter dienen (siehe Listing 1). Daneben sind zwei unterschiedliche Schreibmodi vorgesehen: Das Tag »veryImportant« verlangt, dass die Daten auf jeweils einen Knoten aller drei Standorte geschrieben werden, »sortOfImportant« verlangt nur zwei Standorte. Die Eingabe erfolgt auf der »mongo« -Konsole als Json-Query gegen die Replica-Set-Konfiguration.
Listing 1
Replica Set konfigurieren
01 {
02 _id : "someSet",
03 members : [
04 {_id : 0, host : "A", tags : {"dc": "ny"}},
05 {_id : 1, host : "B", tags : {"dc": "ny"}},
06 {_id : 2, host : "C", tags : {"dc": "sf"}},
07 {_id : 3, host : "D", tags : {"dc": "sf"}},
08 {_id : 4, host : "E", tags : {"dc": "cloud"}}
09 ]
10 settings : {
11 getLastErrorModes : {
12 veryImportant : {"dc" : 3},
13 sortOfImportant : {"dc" : 2}
14 }
15 }
16 }
Bei dieser Konfiguration würden die folgenden Statements einmal in New York, einmal in San Francisco und einmal in der Cloud geschrieben:
db.foo.insert({x:1})
db.runCommand({getLastError : 1, w : "veryImportant"})
Das ist zumindest das Eingabeformat für die Mongo-Konsole. Auch andere Treiber besitzen die gleiche Funktionalität, sodass der Entwickler die Methode »getLastError« in der Programmiersprache seiner Wahl aufrufen kann.
Sharding
Doch selbst mit schnellen Netzwerkverbindungen, viel RAM und Solid State Disks begrenzt am Ende die Leistungsfähigkeit des einzelnen Knotens die Mongo-DB-Performance. Es sei denn, der Admin setzt auf horizontale Skalierung und damit auf die Clustertechnik Sharding. Bei Mongo DB erfolgt das Sharding für die Anwendung transparent. Der Entwickler lässt den Client lediglich mit einem Routerprozess namens »mongos« kommunizieren statt direkt mit der Datenbank. Dieser verteilt die Daten auf die einzelnen Shards, denn er weiß, wo welche liegen. Unterstützt wird er von drei Konfigurationsservern, die Metadaten vorhalten.
Shard Key
Sharding ist oberhalb der Replica Sets angesiedelt, die einzelnen Knoten eines Set enthalten also die gleichen Daten. Jedes Shard besteht aus einem Replica Set, Mongo DB verteilt die Daten gleichmäßig über die Shards. Dabei verschiebt die Datenbank diese Stücke auch, um das Gleichgewicht zu gewährleisten.
Der Admin darf konfigurieren, was ein Shard ausmacht. Das tut er mit dem so genannten Shard Key, der die Daten aufteilen sollte, ohne Hotspots zu erzeugen. Verwendet er beispielsweise einen Timestamp als Shard Key, verteilen sich die Daten chronologisch über die Shards. Ruft die Anwendung aber beispielsweise die Daten des laufenden Tages am häufigsten ab, führt das zu Problemen, weil sie alle im selben Shard liegen. Ein besserer Schlüssel besitzt ein Zufallselement und entspricht keinem Muster der Anwendung. Die Mongo-DB-Dokumentation [12] vermittelt weitere Details.
Umsichtig administrieren
Sharding ermöglicht es, dem Cluster transparent weitere Shards hinzuzufügen, um den Speicherplatz zu vergrößern. Die Umverteilung der Daten erledigt die Software dabei automatisch. Das funktioniert, wenn der Admin die operativen Empfehlungen einhält und beispielsweise neue Shards schon frühzeitig einbindet. Ansonsten wird die Umverteilung der Dokumente zur Performance-Bremse. Bei einer Vergrößerung von zwei auf drei Shards beispielsweise muss Mongo DB ein ganzes Drittel des Datenbestands auf den neuen Teil umziehen.
Der Betrieb von NoSQL-Datenbanken folgt vertrauten Prinzipien: Großzügig bemessener Arbeitsspeicher und schnelle Festplatten bringen Performance. Dennoch gibt es Unterschiede, der Admin sollte sich wie in jede andere Technologie gründlich einarbeiten.
Dank ihrer Popularität ist Wissenswertes über Mongo DB weit verbreitet: Online-Artikel, Blogs und Mailinglisten sowie Konferenzen richten sich an Interessierte. Das macht die Software zu einer guten Wahl für viele Datenbankanwendungen. Mongo DB spielt ihre Stärken besonders im High-Performance-Einsatz aus. Dabei sollte man sich aber Gedanken über den Kompromiss zwischen Geschwindigkeit und Konsistenz machen. (mhu)
Infos
- Hersteller 10gen: http://www.10gen.com/leading-nosql-database
- Skalierbarkeits-Mythen: http://mongodb-is-web-scale.com
- Kritik an Mongo DB: http://blog.serverdensity.com/does-everyone-hate-mongodb/
- REST-API: http://docs.mongodb.org/ecosystem/tools/http-interfaces/
- Treiber: http://docs.mongodb.org/ecosystem/drivers/
- Dokumentenstruktur: http://docs.mongodb.org/manual/core/data-modeling/
- Padding-Faktor: http://tebros.com/2010/11/mongodb-paddingfactor-implications/
- Bson-Spezifikation: http://bsonspec.org
- Replikation: http://docs.mongodb.org/manual/replication/
- Performance: https://blog.serverdensity.com/mongodb-benchmarks/
- Replica-Tagging: http://docs.mongodb.org/manual/reference/replica-configuration/
- Sharding-Interna: http://docs.mongodb.org/manual/core/sharded-cluster-internals/
Der Autor

Der Brite David Mytton hat die “London MongoDB User Group” gegründet und war einer der Ersten, die die Datenbank produktiv einsetzten. Sein Unternehmen Server Density http://blog.serverdensity.com bietet ein SaaS-Tool für Infrastruktur-Provisioning und -Monitoring an.






