
© Dan Kuta ,photocase.com
Streicht ein Besitzer von Amazons E-Book-Reader Textstellen auf dem Gerät an, legt sein Kindle diese persönlichen Markierungen in einer Datei ab. Steckt der Kindle im USB-Port des Linux-Rechners, saugt ein Perl-Skript die Daten ab, speichert sie in einer Datenbank und erlaubt später Volltext-Suchabfragen.
E-Books bilden immer mehr Eigenschaften von Büchern aus Papier nach: Der Käufer darf elektronische Bücher auf Amazons Kindle heutzutage nicht nur zeitweise an Freunde ausleihen, sondern auch Bookmarks im Text setzen (siehe Abbildung 1) und Passagen im digitalen Lesefutter anstreichen (Highlights oder Clippings). Praktischerweise schickt der Kindle diese Markierungen auch an einen zentralen Server, sodass sie dem User später auch auf anderen Lesegeräten zur Verfügung stehen.

Abbildung 1: Streicht der Leser Stellen im Text an, speichert der Kindle-Reader diese Markierungen in einer Textdatei und gibt sie auch an den zentralen Server weiter.
Eine kompakte Sammlung angestrichener Stellen aus verschiedensten Büchern hilft zudem nach Begriffen zu fahnden, von denen der Leser zwar weiß, dass er sie irgendwo markiert hat, sich aber nicht an den zugehörigen Buchtitel erinnern kann. In [2] schlägt ein Produktivitätsguru deswegen vor, die Highlights aus der personalisierten Kindle-Webseite auf Amazon.com mittels Cut&Paste zu extrahieren. Dieses Ansinnen lässt sich aber auch eleganter lösen: Der Kindle legt diese vom Nutzer generierten Informationen in einer Klartextdatei auf dem Dateisystem des Geräts ab, und die heute vorgestellten Perl-Skripte greifen sie einfach von dort ab, sobald der User seinen Kindle an den USB-Anschluss eines Linux-Rechners einstöpselt.
Aktion beim Einstöpseln
Nach dem Anschluss des Kindle an die USB-Buchse eines Ubuntu-Systems kommt zunächst der Dialog von Abbildung 2 hoch, der vorschlägt, den Kindle mittels des MP3-Spielers Rhythmbox oder anderer Applikationen anzusteuern. Eine weitere Auswahlmöglichkeit in der angezeigten Liste weist Ubuntu dazu an, nichts dergleichen zu tun, und ein Klick auf »Always perform this action« hält Ubuntu auch in Zukunft von derartigem Unsinn ab.

Abbildung 2: Dieses nervige Popup lässt sich durch die Auswahl von »Do Nothing« und »Always perform this action« zum Schweigen bringen.
Ubuntu mountet das Dateisystem des Kindle anschließend unter »/media/Kindle« . Abbildung 3 zeigt, dass die Datei mit den gespeicherten Highlight-Informationen im Ordner »documents« unter dem Kindle-Rootverzeichnis liegt und »My Clippings.txt« (mit Leerzeichen) heißt. Ein Blick hinein offenbart, dass es sich um Klartext handelt. Die einzelnen Einträge notieren zeilenorientiert und grenzen sich vom folgenden Eintrag durch eine Kette von »=« -Zeichen ab (Abbildung 4).
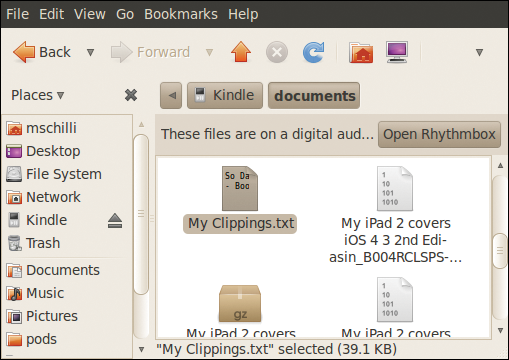
Abbildung 3: Die Datei »My Clippings.txt« im Ordner »documents« auf dem Kindle speichert die angestrichenen Stellen im Textformat.
In der Textdatei finden sich nicht nur markierte Textpassagen, sondern auch Lesezeichen und Randnotizen, die der Besitzer über die Kindle-Tastatur selbst eingegeben hat, beispielsweise um sich über entdeckte Druckfehler lustig zu machen oder den Buchinhalt besserwisserisch zu kommentieren.

Abbildung 4: Textstellen, die der Leser angestrichen hat, erscheinen in der Datei »My Clippings.txt« im Dateisystem des Kindle-Readers.
Formatpfriemelei
Zur maschinellen Umwandlung des Kindle-Klartextformats in Datenbankeinträge, die später auch Suchabfragen zulassen, dient das Modul »ClippingsParser.pm« in Listing 1. Es nimmt einen Filedeskriptor der Clippings-Datei auf dem Kindle entgegen, durchforstet dann das undokumentierte Format und gibt die Einzelheiten wie Buchtitel, Autor, Seite, Highlight-Datum und Highlight-Text an den Aufrufer zurück.
Listing 1
ClippingsParser.pm
01 ###########################################
02 package ClippingsParser;
03 ###########################################
04 # Mike Schilli, 2012 (m@perlmeister.com)
05 ###########################################
06 use strict;
07 use warnings;
08
09 ###########################################
10 sub new {
11 ###########################################
12 my( $class ) = @_;
13
14 bless {}, $class;
15 }
16
17 ###########################################
18 sub parse_fh {
19 ###########################################
20 my( $self, $fh, $callback ) = @_;
21
22 my $line_sep = "==========\r\n";
23 my $entry = "";
24 my $first = 1;
25
26 while( my $line = <$fh> ) {
27
28 if( $first ) {
29 $first = 0;
30 $line =~ s/^\W+//;
31 }
32
33 if( $line eq $line_sep ) {
34 $self->parse_entry( $entry,
35 $callback );
36 $entry = "";
37 } else {
38 $entry .= $line;
39 }
40 }
41 }
42
43 ###########################################
44 sub parse_entry {
45 ###########################################
46 my( $self, $entry, $callback ) = @_;
47
48 my( $head, $whence, $empty, $text ) =
49 split /\r\n/, $entry, 4;
50
51 # format error?
52 die "format error" if !defined $text;
53
54 $text =~ s/\r\n\Z//;
55
56 my( $title, $author ) =
57 ( $head =~ /^(.*) \((.*?)\)$/ );
58
59 # sometimes there's no author
60 if( !defined $author ) {
61 $author = "";
62 $title = $head;
63 }
64
65 my @whence = split /\s*\|\s*/, $whence;
66 my $when = pop @whence;
67 my $what = join "|", @whence;
68
69 my( $type, $loc ) =
70 ( $what =~ /^- (\w+) (.*)/ );
71
72 $callback->( $type, $loc, $author,
73 $title, $when, $text );
74 }
75
76 1;
Die Methode »parse_fh()« nimmt einen Filedeskriptor auf die geöffnete Textdatei und eine Codereferenz als Callback entgegen, den sie bei jedem gefundenen Eintrag anspringt. Die erste Zeile der Kindle-Datei kann vor dem ersten Eintrag am Zeilenanfang einige unlesbare Zeichen enthalten, die das Ersetzenkommando in Zeile 30 verschwinden lässt.
Entspricht der Inhalt der aktuell untersuchten Textzeile in Skriptzeile 33 nicht dem aus »=« -Zeichen zusammengesetzten Eintragstrenner, hängt Zeile 38 den Inhalt an die Variable »$entry« an. Stößt das Skript auf eine Trennzeile zwischen Einträgen, ruft Zeile 34 die Methode »parse_entry« auf und übergibt ihr die bislang aufgesammelten Textdaten und den Callback, der nach erfolgreicher Analyse anzuspringen ist.
In »parse_entry()« teilt der »split« -Befehl in Zeile 49 einen Eintrag in Überschrift (»$head« ), Buchseite und Erfassungsdatum (»$whence« ), eine Leerzeile und den markierten Text (»$text« ) auf. Da die Kindle-Datei das Windows-Format mit »\r\n« als Zeilentrenner verwendet, nutzt »split« diese Kombination im regulären Ausdruck in Zeile 49.
Listing 2
sqlite-setup.sh
01 file=highlights.sqlite 02 rm -f $file 03 04 sqlite3 $file <<EOT 05 CREATE VIRTUAL TABLE highlights USING FTS3 ( type TEXT, loc TEXT, 06 author TEXT, title TEXT, date TEXT, text TEXT ); 07 08 CREATE TABLE seen ( type TEXT, loc TEXT, title TEXT, 09 UNIQUE(type, loc, title) ); 10 EOT
Manche E-Books, etwa Wörterbücher, geben keine Autoren in Klammern hinter dem Titel an, also bleibt das Autorenfeld in Zeile 61 in diesem Fall leer. Das letzte, durch den Trenner »|« abgesonderte Feld in der zweiten Zeile mit den Location- und Seitenangaben enthält das Datum, an dem die Textstelle markiert oder das Lesezeichen gesetzt wurde. In den Zeilen 72 und 73 stehen alle Felder bereit und der Callback-Aufruf übergibt ihre Werte an die vom Hauptprogramm als Referenz hereingereichte Funktion.
Mit dem Parser-Modul ist es nun ein Leichtes, die Kindle-Daten umzumodeln und in ein Format zu überführen, das schnelle Abfragen gestattet. Damit der User später mit der Volltextsuche nach Begriffen in markierten Textabschnitten suchen kann, speist das Skript in Listing 3 die gefundenen Highlight-Daten in eine SQlite-Datenbank mit Volltext-Engine ein. Listing 2 zeigt, dass besondere »CREATE« -Kommandos mit dem Kommandozeilentool »sqlite3« notwendig sind, damit SQlite, das Datenbanken in flachen Binärdateien anlegt, die abgelegten Textdaten so indiziert, dass Suchabfragen nach mehreren Wörtern mit Google-Geschwindigkeit ablaufen.
Listing 3
kindle-connected
01 #!/usr/local/bin/perl -w
02 use strict;
03 use local::lib qw(/home/mschilli/perl5);
04 use Log::Log4perl qw(:easy);
05 use POSIX;
06 use DBI;
07
08 my $run_as = "mschilli";
09 my $clip_path =
10 "/media/Kindle/documents/My Clippings.txt";
11
12 BEGIN {
13 use FindBin qw($RealBin);
14 chdir $RealBin;
15 }
16 use ClippingsParser;
17
18 my $logfile = "/var/log/kindle.log";
19
20 Log::Log4perl->easy_init({
21 file => ">>$logfile",
22 level => $DEBUG,
23 });
24
25 my ( $name, $passwd, $uid, $gid ) =
26 getpwnam( $run_as);
27
28 chown $uid, $gid, $logfile or
29 LOGDIE "Cannot chown $logfile: $!";
30 chmod 0644, $logfile or
31 LOGDIE "Cannot chmod $logfile: $!";
32
33 POSIX::setuid( $uid );
34
35 my $pid = fork();
36 die "fork failed" if !defined $pid;
37 exit 0 if $pid; # parent
38
39 # wait until kindle root dir is mounted
40 for( 1..10) {
41 if( -f $clip_path) {
42 last;
43 } else {
44 DEBUG "Waiting for $clip_path";
45 sleep 5;
46 next;
47 }
48 }
49
50 LOGDIE "$clip_path not found"
51 if !-f $clip_path;
52
53 my $dbh = DBI->connect(
54 "dbi:SQLite:highlights.sqlite", "", "",
55 { RaiseError => 1, PrintError => 0 }
56 );
57
58 open my $fh, "<", $clip_path or
59 LOGDIE "Cannot open $clip_path ($!)";
60
61 my $cp = ClippingsParser->new();
62
63 my $items_added = 0;
64
65 $cp->parse_fh( $fh, sub {
66 my( $type, $loc, $author, $title,
67 $when, $text ) = @_;
68
69 my $sth = $dbh->prepare(
70 "INSERT INTO seen VALUES (?, ?, ?)");
71
72 eval {
73 $sth->execute( $type, $loc, $title );
74 };
75
76 return if $@; # most likely a dupe
77
78 $sth = $dbh->prepare( "INSERT INTO " .
79 "highlights VALUES (?, ?, ?, ?, ?, ?)");
80 $sth->execute( $type, $loc, $author,
81 $title, $when, $text );
82 $items_added++;
83 } );
84
85 INFO "$items_added items added";
86 close $fh;
Volltext oder Pattern-Match
SQL-Datenbanken erlauben im Normalmodus Suchkriterien wie »LIKE %begriff%« und kramen damit gemächlich Einträge hervor, deren Textspalten bestimmte Zeichenketten enthalten. Selbst wenn man von der schleppenden Geschwindigkeit absieht, zeigt sich noch ein weiterer Nachteil: Wer zum Beispiel nach Einträgen sucht, die die beiden Wörter “Perl” und “Data” irgendwo im Text verstreut enthalten, ist dies nur umständlich möglich. Eine Volltext-Engine hingegen spezialisiert sich auf derartige Abfragen und sucht grundsätzlich nur nach ganzen Wörtern. Auf der Suche nach “Data”, fände sie keine Einträge mit “Database”, sucht sie aber nach “Date Time”, findet sie alle Texte, die die Wörter “Date” und “Time” beliebig verstreut und in beliebiger Reihenfolge enthalten.
Damit SQlite eine Tabelle mit Volltextindex anlegt, fordert Listing 2 statt einer normalen Tabelle eine “Virtual Table” an, die mit »USING FTS3« Version 3 des “Full Text Search”-Plugins einsetzt. FTS3 liegt SQlite seit Version 3.5.0 im Jahr 2007 bei, und mit SQlite 3.7.4 kam im Jahr 2010 die Release FTS4 hinzu, die Verbesserungen der Performance, aber auch erhöhte Komplexität mit sich bringt [3].
Die Volltexttabelle lässt sich wie normale Tabellen auch mit »INSERT« -Aufrufen füllen und mit »SELECT« -Queries abfragen. Sie bietet zwei zusätzliche Funktionen: Erstens verfügt sie über ein virtuelle Spalte, deren Name mit dem Tabellennamen identisch ist und die sich bei Abfragen wie eine Zusammenfassung aller Tabellenspalten verhält. Im vorliegenden Fall liefert die »SELECT« -Bedingung
WHERE highlights MATCH(?)
alle Einträge, bei denen irgendeine Spalte auf den angegebenen »MATCH« -Operator anspricht.
Der zweite Unterschied ist der »MATCH« -Operator, der eine wortorientierte Volltextsuche implementiert. So sucht etwa »MATCH(“katze hund”)« nach Texten, die beide Wörter irgendwo und in beliebiger Reihenfolge enthalten, und ist außerdem schlau genug Groß- und Kleinschreibung zu ignorieren. Es lässt sich sogar ein Stemming einstellen, bei dem “katze” auch auf “katzen” passt.
Datenbankfutter
Listing 3 sorgt für das Auslesen der Clippings-Datei auf dem Kindle und das Auffüllen der SQlite-Datenbank auf dem Linux-Rechner. Damit es sowohl das Modul »ClippingsParser.pm« als auch die Datenbankdatei »highlights.sqlite« findet, die sich im selben Verzeichnis wie das Skript befinden, wechselt der »BEGIN« -Block ab Zeile 12 zunächst in das Verzeichnis, in dem das Skript steht.
In die Logdatei »/var/log/kindle.log« schreibt es, was es gerade treibt. Das erweist sich als besonders hilfreich beim Debuggen, falls das Skript im Hintergrund läuft. Und dies ist die Regel, später ruft es das Udev-System des Linux-Kernels automatisch auf, sobald der User den Kindle anschließt.
Dies erfordert auch, dass es sofort zurückkehrt und im Hintergrund weiterläuft, um dann die Clipping-Daten auszulesen und der Reihe nach in der Datenbank abzulegen. Hierzu setzt es in Zeile 35 einen Fork-Befehl ab und erzeugt einen Child-Prozess, der die anstehende Arbeit erledigt, während der Prozessvater sich verabschiedet. Da der Kernel das Skript als Root aufruft, setzt Zeile 33 mit dem Kommando »setuid« aus dem Posix-Modul die Rechte zurück auf den in Zeile 8 gesetzten User, um keine unnötigen Sicherheitslöcher aufzureißen.
Da das Kindle-Rootverzeichnis zum Zeitpunkt des Skriptstarts vielleicht noch gar nicht existiert, probiert die For-Schleife ab Zeile 40 zehnmal hintereinander, ob es die Clippings-Datei lesen kann. Falls nicht, wartet das Skript jeweils 4 Sekunden und startet einen neuen Versuch.
Keine alten Hüte
Schließt der User dasselbe Kindle-Gerät etliche Male hintereinander am Rechner an, stehen die meisten Einträge bereits in der Datenbank und blindes Kopieren würde zu unerwünschten Duplikaten führen, die die Datenbank nur unnötig aufschwemmen.
Um diese Dubletten zu verhindern, hat das Shellskript in Listing 2 vorher eine zweite (reale) Tabelle »seen« definiert, die mit einer »UNIQUE« -Anweisung festlegt, dass die Kombination aus »type« (also »Highlight« , »Bookmark« oder »Note« ), »loc« (Seitenangabe) und »title« (Buchtitel) eindeutig sein muss.
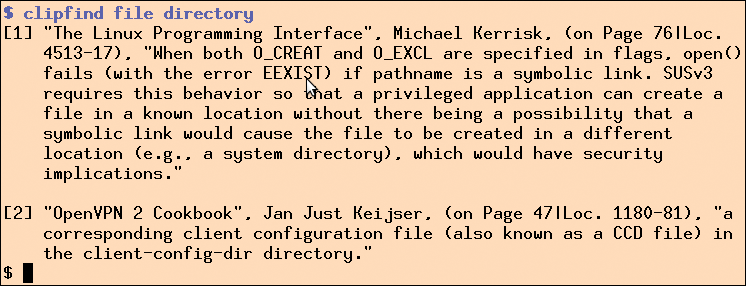
Abbildung 5: Die Volltextsuche »clipfind« gibt alle angestrichenen Textstellen aus, die sowohl das Wort »file« als auch das Wort »directory« enthalten.
Fügt nun Zeile 69 ungewollt einen dort bereits vorhandenen Record in die Tabelle »seen« ein, führt dies automatisch zu einem Fehler, denn das Datenbanksystem weigert sich strikt, ein Duplikat einzuspeisen. Das »eval« -Konstrukt in Zeile 72 fängt diesen Fehler ab, und die »if« -Bedingung in Zeile 76 kehrt in diesem Fehlerfall vorzeitig aus dem Callback zurück. Wenn der Eintrag hingegen noch nicht vorhanden ist, dann bereitet Zeile 78 pflichtschuldig einen neuen Eintrag vor und Zeile 80 führt ihn anschließend korrekt in die Datenbank ein.
Wer suchet, der findet
Listing 4 nimmt Suchanfragen entgegen, fieselt die passenden Einträge aus der Datenbank heraus und präsentiert sie in Form eines Literaturverzeichnisses. Abbildung 5 zeigt, wie »clipfind« Einträge sucht, die sowohl das Wort »file« als auch das Wort »directory« enthalten, und zwei Einträge zum Vorschein bringt. Der erste ist ein Absatz aus dem hervorragenden Linux-Buch “The Linux Programming Interface” von Michael Kerrisk, der zweite eine Passage aus dem “OpenVPN 2 Cookbook” von Jan Just Keijser.
Listing 4
clipfind
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Text::Wrap qw(fill);
04 use DBI;
05
06 BEGIN {
07 use FindBin qw($RealBin);
08 chdir $RealBin;
09 }
10
11 my $query = join " ", @ARGV;
12
13 my $dbh = DBI->connect(
14 "dbi:SQLite:highlights.sqlite", "", "",
15 { RaiseError => 1 } );
16
17 my $sth = $dbh->prepare(
18 "SELECT * FROM highlights " .
19 "WHERE type = 'Highlight' AND " .
20 "highlights MATCH(?)" );
21
22 $sth->execute( $query );
23
24 my $serial = 1;
25
26 while( my $ref =
27 $sth->fetchrow_hashref() ) {
28
29 my $output = "[$serial] " .
30 "\"$ref->{title}\", $ref->{author}, " .
31 "($ref->{loc}), \"$ref->{text}\"";
32
33 print fill("", " ", ($output)),
34 "\n\n";
35
36 $serial++;
37 }
Automatisch loslegen
Damit das Skript loslegt, wenn der User den Kindle einsteckt (Abbildung 6), stellt der Automatisierungsfachmann die »udev« -Regel (Listing 5) ins Verzeichnis »/etc/udev/rules.d« und ruft
Listing 5
99-kindle.rules
1 SUBSYSTEM=="usb", ACTION=="add", ENV{DEVTYPE}=="usb_device", ATTRS{idVendor}=="1949", ATTRS{idProduct}=="0004", RUN+="/home/mschilli/git/articles/kindle-highlights/eg/kindle-connected"

Abbildung 6: Mit dem USB-Stecker lässt sich der Kindle an eine Linux-Box anschließen.
sudo service udev restart
auf, um den »udev« -Service entsprechend auf die geänderte Konfiguration aufmerksam zu machen. Dabei erweist sich der Eintrag
ENV{DEVTYPE}=="usb_device"
als nützlich, denn er verhindert, dass der Handler in der »RUN« -Direktive vielfach angesprungen wird, weil ein frisch eingesteckter Kindle eine Reihe von Aktionen auslöst: Erst wird ein USB-Eintrag angelegt, dann eine Festplatte zugewiesen, danach eine Partition und weiterer Heckmeck. Jedes Mal die Clippings-Datei zu durchforsten wäre Verschwendung, abgesehen von der Systembelastung durch Parallelprozesse, die auf das Verzeichnis mit dem Kindle-Filesystem warten.
Eine weitere Möglichkeit, das Anschließen des Kindle abzufangen, wäre der in [4] vorgestellte Dämon, der sich auf den D-Bus des Linux-Systems setzt und den Mount-Event abfängt.
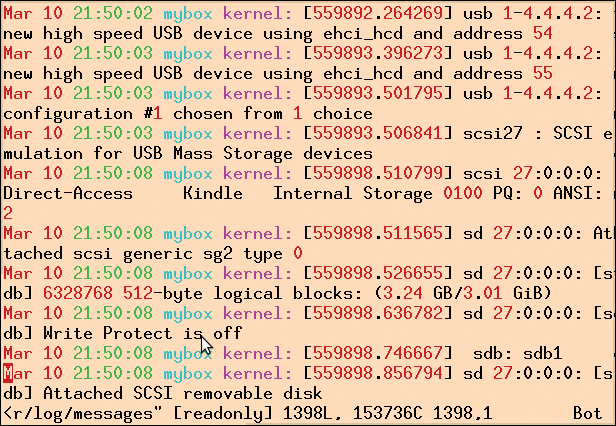
Abbildung 7: Beim Einstöpseln des Kindle in den Ubuntu-Rechner erscheinen Meldungen des USB-Subsystems in der Logdatei »/var/log/messages«.
Die in der »udev« -Regel angegebenen Werte für Vendor-ID und Product-ID finden Linux-Anwender heraus, indem sie, wie in der Abbildung 7 gezeigt, neue Einträge in der Datei »/var/log/messages« verfolgen, die dem Kindle zugewiesene Nummer im USB-Baum ausfindig machen (im Beispiel also 1-4.4.4-2) und anschließend im Verzeichnis »/sys/bus/usb« die entsprechenden Datei-Inhalte auslesen, wie es in Abbildung 8 gezeigt ist. Ab dann sollte aber alles automatisch funktionieren und die lokale Datenbank Kindle-Daten sofort beim Einstöpseln spiegeln.
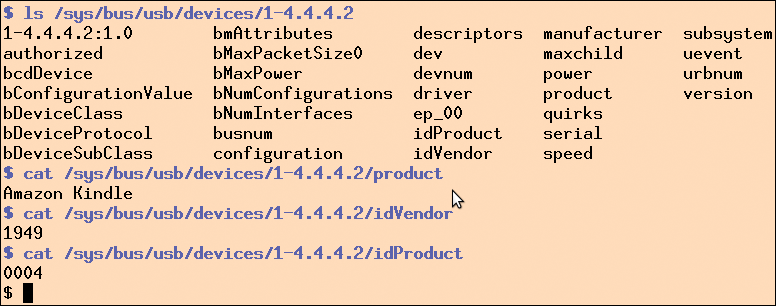
Abbildung 8: Das »/sys«-Verzeichnis offenbart die USB-Parameter des angeschlossenen Kindle-Readers.
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/plus/2012/05
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2012/05/Perl
- Michael Hyatt, “How to get your kindle highlights into Evernote”: http://michaelhyatt.com/how-to-get-your-kindle-highlights-into-evernote.html
- “SQlite FTS3 and FTS4 Extensions”:http://www.sqlite.org/fts3.html
- Michael Schilli, “Bus-Touristik”: Linux-Magazin 04/11, S. 110: https://www.linux-magazin.de/Heft-Abo/Ausgaben/2011/04/Bus-Touristik
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seinen seit 1997 erscheinenden Snapshots forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Ihre Fragen.





