
Manche Zeitschriftenartikel gibt es einfach nicht online. Das Skript, um das es in dieser Ausgabe des Perl-Snapshots geht, archiviert die eingescannte Druckversion solcher Beiträge im PDF-Format und nutzt eine kleine Datenbank, um sie später wiederzufinden.
Ob ein gelungenes 100-Fragen-Interview im Magazin der “Süddeutschen Zeitung” oder eine Max-Goldt-Kolumne in der “Titanic”: Beide liest man immer wieder gerne und möchte sie vielleicht archivieren. Leider werden sie nicht online angeboten. Die alten Hefte aufzuheben lohnt auch nicht recht, denn eigentlich interessiert doch nur hier und da ein Artikel – ganze Zeitungen oder Zeitschriften liest nach zwei Jahren ohnehin kein Mensch mehr.
Viel praktischer als bergeweise Papier zu horten ist es deshalb, die interessanten Beiträge mit einem Scanner zu digitalisieren und als PDF auf Festplatte zu speichern. Damit der Archivar in der ständig wachsenden Bibliothek nicht den Überblick verliert, verwaltet das hier vorgestellte Perlskript »magsafe« die Dokumente in einer Datenbank.
Scannen und Packen
Zwei, drei Seiten sind schnell eingescannt, das hervorragende GUI-Programm Xsane aus dem Sane-Projekt[4] arbeitet über das Sane-Backend mit vielen Scannern zusammen. Sowohl der Epson-Fotoscanner als auch der HP-All-In-One-Officejet aus dem Perlmeister-Testlabor funktionieren problemlos unter Linux. Die Einzelseiten werden als Bilder im PNG-Format abgelegt. (Abbildung 1). Üblicherweise reichen 200 dpi, damit der Text lesbar bleibt und ein Drucker später gerade noch akzeptable Qualität produziert.

Abbildung 1: Xsane digitalisiert den Titanic-Artikel.
Das Convert-Utility fasst mehrere Seiten zu einem PDF-Dokument zusammen, dabei nutzt es einen aus[2] geklauten Trick: »convert -density 200 -quality 95 -resize “1600×1600>” *.png archive.pdf«. Der Aufruf sammelt alle im gegenwärtigen Verzeichnis liegenden PNG-Dateien ein und begrenzt sowohl Höhe als auch Breite auf 1600 Pixel. Kleinere Bilder bleiben wegen des Größer-als-Zeichens unverändert. Die Einzelseiten bündelt Convert zu einer mehrseitigen PDF-Datei mit 200 dpi Auflösung. Die PNGs werden für das PDF-Dokument zu JPG mit 95-prozentiger Qualität konvertiert.
Hat sich der zweiseitige Artikel von Max Goldt dann in die Datei »goldt.pdf« verwandelt, verfrachtet ihn folgender Aufruf ins Archiv:
magsafe -m Titanic -a "Max U Goldt" -t "Tropfen, Klingeln U und die üble Weiterleiterei" U -i 2005/03 -p 44 -d goldt.pdf
So entsteht ein Datensatz mit dem Namen der Zeitschrift (Titanic), dem Artikeltitel (Tropfen, Klingeln …), der Nummer der Ausgabe (2005/03) und der Startseite (44).
Leichte Datenbank
Die Daten liegen in einer echten Datenbank mit SQL-Abfragemöglichkeit. Der Datenbankmotor SQLite[3] kam im Perl-Snapshot schon öfter zum Einsatz, denn er ermöglicht eine sehr einfache Installation. Wie der Abschnitt “Installation” am Schluss des Artikels zeigt, sind lediglich ein paar CPAN-Module zu laden, das Skript erledigt den Rest. Der Anwender muss keine Datenbank oder Tabelle einrichten.
Das PDF-Dokument selbst liegt allerdings nicht in der Datenbank. Es landet stattdessen in einem Verzeichnis, das alle Dokumente unter fortlaufend nummerierten Dateinamen aufnimmt (Muster: »000001«, »000002« und so weiter). War die Datenbank bislang leer, hat der Befehl oben nun ein neues Dokument »000001« erzeugt, das die PDF-Datei »goldt.pdf« enthält.
Als zweiter Datensatz wandert ein 100-Fragen-Interview von Moritz von Uslar mit Ralph Lauren aus einer-SZ-Magazin-Ausgabe des Jahrgangs 2004 ins Artikelarchiv:
magsafe -m "SZ Magazin" -t "100 Fragen an Ralph Lauren" -i 2004/37 -p 56 -d lauren.pdf
Wie man sieht, dürfen die Angaben zum Autor entfallen. Sie sind in manchen Fällen nicht bekannt, etwa bei Agenturmeldungen, wie sie Tageszeitungen veröffentlichen.
Auf Nachfrage
Wenn der Benutzer »magsafe« ohne Parameter aufruft, dann fragt ihn das Skript interaktiv nach den fehlenden Angaben zum Beitrag:
$ magsafe [1] New [2] Titanic [3] SZ Magazin Magazine [1]>
Da schon zwei Zeitschriften eingetragen sind, sucht »magsafe« deren Titel raus und gibt sie anschließend in einem nummerierten Menü vor. Wer eine bisher noch nicht erfasste Zeitschrift eingeben möchte, wählt einfach die Menü-Option »1« und tippt den Namen der neuen Publikation ein:
Magazine [1]> 1 Enter Magazine Name []> Der Spiegel Document []> ...
Das mit der Option »-d« (oder interaktiv) angegebene PDF-Dokument kopiert »magsafe« in ein Verzeichnis, das intern fest konfiguriert ist. Die einzelnen Dateien darin sind – wie erwähnt – der Reihe nach nummeriert. Die Zuordnung zum jeweils enthaltenen PDF merkt sich die Datenbank.
Der Vorteil einer Datenbank ist natürlich, dass sie sich besonders schnell und leicht durchsuchen lässt. Bei der Zeitschriftendatenbank, die in der Datei »scanned_docs.dat« liegt, geht das auf der Kommandozeile mit dem Abfrage-Utility »sqlite3« und dem guten alten SQL:
$ sqlite3 scanned_docs.dat sqlite> SELECT * from doc where title like '%Ralph%' 2|100 Fragen an Ralph U Lauren||2|56|2004/37 CTRL-D $
Diese Methode wäre freilich noch etwas umständlich, daher bietet »magsafe« eine Art vereinfachter Abfragesprache an: Hinter dem Parameter »-s« erwartet es einen Suchstring im Format: » Feld:Pattern Feld:Pattern …«
Alle Artikel, deren Titel das Wort »Ralph« enthalten, fördert »magsafe -s title:Ralph« zutage. Das Skript formt daraus hinter den Kulissen eine SQL-Abfrage ähnlich der oben gezeigten, nachdem es den Suchbegriff in Prozentzeichen eingepackt hat.
Wer sich aber beispielsweise für alle Artikel interessiert, die im Jahre 2005 erschienen sind, also im Feld »issue« den String »2005« enthalten, gibt »-s issue:2005« ein. Kommen auf diese Weise zu viele Treffer zustande, beschränkt eine zusätzliche »mag:«-Klausel die Abfrage »-s “issue:2005 mag:Titanic”« auf alle Artikel aus der Titanic.
Abstrakte Datenbank
Die von »magsafe« verwendete Datenbankabstraktion Class::DBI kam schon einige Male im Snapshot vor. Doch heute geht es sogar noch einfacher: Das Modul Class::DBI::Loader vereinfacht die Klassendefinition von Class::DBI noch zusätzlich, indem es einfach das Layout der Datenbanktabellen analysiert und daraus die Abstraktionsklassen und deren Beziehungen erzeugt.
Listing 1 zeigt die Implementierung. Das Modul Get- opt::Std verarbeitet die vielen Kommandozeilenoptionen, die »magsafe« versteht. Zeile 21 sucht nach »-a«, »-m«, »-t« und so weiter. Die Doppelpunkte im Formatstring der »getopts«-Funktion bestimmen, dass den Optionen je ein Parameter folgt. Deren Werte legt »getopts« im Hash »%o« zur späteren Verarbeitung ab. Zeile 23 prüft, ob das Dokumentenverzeichnis zumin- dest leer existiert und beschreibbar ist. Falls nicht, sollte es vor einem neuerlichen Programmstart angelegt werden.
Tabellenlayout
Die in Zeile 26 aufgerufene Funktion »db_init()« sorgt anschließend dafür, dass der Benutzer sich niemals mit den Details der Datenbank herumschlagen muss. Existiert noch keine Datenbank, legt »db_init()« sie ab Zeile 108 mit einigen SQL-Befehlen an. Abbildung 2 zeigt das Schema. Die Tabelle »doc« enthält für jedes abgespeicherte Dokument eine Zeile. Neben dem Titel des jeweiligen Artikels, dem Autor, der Ausgabe und der Seitennummer steht dort auch der Name der Publikation, aus der er extrahiert wurde.
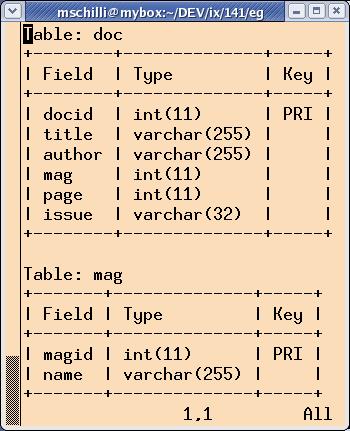
Abbildung 2: Die Daten der Artikel-PDFs landen in diesen beiden Tabellen der Archiv-Datenbank.
Da die meisten Leute nur eine begrenzte Anzahl von Printmedien lesen, diese aber jeden Monat, wäre es schlechtes Datenbankdesign, den vollständigen Zeitschriftentitel in jede Zeile hineinzuschreiben. Auf diese Weise entstünden Redundanzen, die etliche bekannte Probleme nach sich ziehen können. Außerdem würde dadurch unnötig Platz verschwendet. Aus diesem Grund steht in der Tabelle »doc« im Feld »mag« eine numerische ID, die auf eine Zeile der Tabelle »mag« verweist, die neben der gleichen ID den ausgeschriebenen Zeitschriftentitel enthält.
Keys koppeln Tabellen
Die Tabellendefinitionen ab Zeile 109 folgen dem SQL-Standard. Die Zeile »mag INT REFERENCES mag« zeigt an, dass die »mag«-Spalte auf die Tabelle »mag« verweist, um die oben erläuterte Beziehung zwischen Zeitschriften-ID und -Titel herzustellen.
Die ersten Spalten beider Tabellen sind numerische IDs, die als Primary Keys markiert sind. Der in Zeile 28 aufgerufene Konstruktor der Klasse »Class:: DBI::Loader« erwartet sie, um den Objekten, die Tabellenzeilen repräsentieren, eindeutige IDs zuweisen zu können. Neu angelegten Objekten gibt er automatisch noch nicht vergebene IDs, indem er den höchsten bisher vergebenen Wert um eins hochzählt. Die Zeile »namespace => “Scanned::DB”« im Konstruktoraufruf des Datenbank- Loaders bestimmt, dass alle Klassen zur Tabellenabstraktion im Namensraum »Scanned::DB« erscheinen.
Nach dem Aufruf von »Class::DBI::Loader->new()« holt die Methode »find_ class()«, wie in den Zeilen 36 und 37 vorgeführt, Objekte hervor, die die Tabellen repräsentieren. Hierzu nehmen sie den Tabellennamen als Argument entgegen. »$docdb«, ein Objekt vom Typ »Scanned::DB::Doc« weist auf die Dokumententabelle »doc«, »$magdb« vom Typ »Scanned::DB::Mag« auf die Zeitschriftentabelle »mag«. Damit die Objekte nicht nur die Standard-Queries von »Class::DBI« beherrschen, sondern auch etwas kompliziertere WHERE-Klauseln, verwendet der Parameter »additional_ classes« in Zeile 31 zusätzlich »Class:: DBI::AbstractSearch«.
Steuern per Kommando
Das Flag »relationships« in Zeile 33 weist »Class::DBI::Loader« an, die Beziehungen zwischen den Tabellen »doc« und »mag« zu analysieren und zu verdrahten. Wegen der oben erwähnten »REFERENCES«-Klausel begreift es dabei sofort, dass die Spalte »mag« in der Tabelle »doc« nur ein so genannter Foreign Key ist, der auf die Tabelle »mag« verweist. Die objektorientierte Datenbankabstraktion wird dann Methoden bereitstellen, mit denen man schnell auf beide Tabellen zugreifen kann.
Ab Zeile 41 verarbeitet das Skript Kommandozeilenparameter. Ist »-s« nicht gesetzt, sucht der Benutzer nicht nach einem Datenbankeintrag, sondern möchte einen neuen hinzufügen. Die Zeilen 42 bis 47 nehmen die Werte der verschiedenen Optionen wie Titel, Autor, Dokument, Zeitschrift, Seite und Ausgabe entgegen. Falls eine oder mehrere nicht gesetzt sind, holt die Funktion »ask()« aus dem Modul »Sysadm::Install« diese Werte interaktiv beim Benutzer ab. Nur das Autorenfeld ist optional und wird deshalb nicht mit abgefragt.
Neue und bekannte Titel
Die Auswahl der Zeitschrift ist etwas komplizierter und erfolgt mit Hilfe der ab Zeile 130 definierten Funktion »mag _pick«. Dort holt die Methode »retrieve_all()« des Datentabellenobjekts »$magsdb« alle bisher eingegebenen Zeilen der »mag«-Tabelle ein. Die zurückgelieferten Zeilenobjekte bieten Methoden an, um zu den Werten für die einzelnen Felder des Datensatzes zu gelangen: »$obj->name()« gibt so den Namen der Zeitschrift zurück, der im Feld »name« der Tabelle »mag« liegt.
Falls »$picked« noch nicht gesetzt ist, also keine Kommandozeilenoption für den Zeitschriftennamen vorliegt, lässt Zeile 138 den Benutzer mit »pick()« (ebenfalls aus »Sysadm::Install«) per Menü einen Namen aussuchen. Wählt der aber den ersten, »New« betitelten Eintrag, macht Zeile 140 die Auswahl wieder ungültig. Ab Zeile 144 hat der Benutzer Gelegenheit, den Namen einer neuen Zeitschrift einzugeben, der beim nächsten Mal in der Auswahlliste erscheinen wird. Die Methode »find_or_ create()« erzeugt dann in der Tabelle »mag« entweder einen neuen Zeitschrifteneintrag oder findet den zum angegebenen Namen passenden.
Neu eingetragene oder bereits bestehende Zeitschriften repräsentiert die Variable »$mag« in Zeile 42. Weil »Class::DBI::Loader« vorher ganze Arbeit geleistet hat und wegen des »relationships«-Flag auch die Beziehungen zwischen den Tabellen »doc« und »mag« analysiert hat, kann Zeile 49 einfach »$mag->add _to_docs()« aufrufen, um einen Artikel in die Tabelle »doc« einzufügen. Deren »mag«-Spalte verweist dann auf den Eintrag der Zeitschrift in der »mag«-Tabelle. Die Methode »add_to_docs()« des Zeitschriftenobjekts ist nicht explizit in »magsafe« definiert. Sie entsteht automatisch in der Datenbankabstraktion, sobald die Beziehung zwischen den Tabellen feststeht.
Um das aktuelle PDF-Dokument in das Dokumentenverzeichnis zu kopieren, ruft »magsafe« in Zeile 56 die CP-Funktion aus Sysadm::Install auf. Den vollständigen zukünftigen Pfad der Datei ermittelt die ab Zeile 93 definierte Funktion »docpath()«, die lediglich die ihr übergebene ID in einen sechsstelligen Integerwert mit führenden Nullen umwandelt und an den Pfad zum Dokumentenverzeichnis anhängt.
Einfacher als SQL
Liegt eine Suchabfrage vor, iteriert Zeile 62 über alle durch Leerzeichen getrennten »feld:pattern«-Paare, die »magsafe« mit dem Parameter »-s« hereingereicht bekommen hat. Zeile 64 spaltet den Feldnamen vom gesuchten Wert ab. Ist der Feldname »mag«, sucht Zeile 67 erst nach einer passenden Zeitschrift, indem sie den Suchwert in Prozentzeichen einrankt und eine Suchabfrage mit »search _like()« in der Tabelle »mag« startet. Sie kann keine, ein oder mehrere Magazin-Objekte in »@mags« zurückliefern. Deren »id()«-Methode fördert die Magazin-IDs hervor, sodass Zeile 70 im Hash »%search« das Wertepaar »mag => [$id1, $id2, …]« ablegt. »$id1«, »$id2« und so weiter sind die numerischen IDs für die passenden Zeitschriften, der Hasheintrag unter »”mag”« weist auf eine Referenz eines Arrays, der sie alle als Elemente enthält.
Freie Suche
Spezifiziert der Benutzer hingegen eine Suchabfrage mit einer Bedingung, die sich auf ein anderes Feld als »mag« bezieht, tritt der »else«-Zweig ab Zeile 72 in Kraft. Der Suchbegriff wird, in Prozentzeichen eingeschlossen, unter dem Feldnamen im Hash »%search« abgespeichert. Der Inhalt des Hash entspricht nun genau jenem Format, das die in Zeile 77 aufgerufene Methode »search_ where()« der Dokumententabelle erwartet. Sie liefert alle Zeilen, auf die alle im Hash angegebenen Bedingungen passen. Da ein zusätzlicher optionaler Hash noch den Compare-Parameter »cmp« auf »”like”« setzt, sucht »search_where()« nicht nach wörtlich genau passenden Einträgen, sondern nach Pattern, deren Wildcards gemäß dem SQL-Standard mit »%« zu schreiben sind.
Trefferliste
Der »print«-Befehl in Zeile 80 wird wegen des nachgestellten »for @objs« für jedes gefundene Objekt aufgerufen. Er fasst alle Spalten eines gefundenen Tabelleneintrags zusammen und gibt sie formatiert aus. Den Pfad zum PDF- Dokument setzt wieder die bereits erwähnte Funktion »docpath()« zusammen. Wenn die Suchabfrage keine Treffer erzielt, gibt Zeile 89 »No Entries« auf Stderr aus.
Zu beachten ist, dass SQLite Strings als UTF-8 erwartet, mit Umlauten im ISO-8859-1-Format kommt es also nicht zurecht. Ob die Eingabe der Kommandozeilenparameter mit UTF8- oder ISO-8859-1-Kodierung erfolgt, hängt aber ganz von dem lokal betriebenen Terminal ab. Viele neuere Linux-Distributionen haben bereits UTF-8-Terminals, die älteren fahren typischerweise mit ISO-8859-1. Einen Hinweis darauf gibt üblicherweise die Environment-Variable »LANG«: Enthält sie den Namensbestandteil »UTF-8«, dann ist auch das UTF-8-Format einsetzbar.
Umlautkonverter
Das Skript lässt sich an die äußeren Bedingungen anpassen: Ist die Variable »$UTF8_TERM« in Zeile 13 auf einen wahren Wert gesetzt, interpretiert das Skript alle Benutzereingaben als UTF-8 und nimmt keine Umkodierung vor. Ist »$UTF8_TERM« hingegen »0«, vermutet »magsafe«, dass Benutzereingaben im Format ISO-8859-1 erfolgen, und wandelt alle in UTF-8 um, bevor sie in die Datenbank wandern.
Für etwaige Umwandlungen zieht das Skript das Iconv-Modul vom CPAN heran. Zeile 15 erzeugt ein Objekt vom Typ »Text::Iconv« für die Transformation von ISO-8859-1 nach UTF-8. Zudem aktiviert es dessen Methode »raise_error()« mit »1«, damit etwaige Fehler sofort eine Exception werfen. Die Methode »convert()« wandelt ihr übergebene Strings von der einen in die andere Kodierung um. Eine andere Methode wäre das Encode-Modul, jedenfalls für alle, die mindestens Perl 5.8.x fahren.
Installation
Für die Datenbankabstraktion benötigt das Skript verschiedene Module, nämlich DBI, Class::DBI, Class::DBI::SQLite, Class::DBI::AbstractSearch und DBD::SQLite, die allesamt im CPAN-Archiv zu finden sind. Außerdem kommen noch Text::Iconv und Sysadm::Install zum Einsatz. Sie lassen sich aber ebenso problemlos interaktiv in einer CPAN-Shell installieren.
Wer den Commandline-Client »sqlite3« benutzen möchte, um manuell mit SQL-Befehlen in der Datenbank herumzuschnüffeln, lädt sich am besten den Source-Tarball von[3] herunter, kompiliert und installiert ihn. Frühere Versionen (SQLite 1 oder SQLite 2) funktionieren nicht, da DBD::SQLite zurzeit auf SQLite 3 aufbaut und Datenbanken, die ältere SQLite-Versionen erzeugt haben, mit der neuesten Version nicht mehr kompatibel sind.
Das Kommandozeilentool der 3er Version heißt »sqlite3«, im Gegensatz zu den Tools früherer Versionen, die einfach nur »sqlite« heißen. Aber Achtung: Wer bereits SQLite-Datenbanken für die eine oder andere Anwendung mit früheren Versionen des Moduls DBD::SQLite verwendet (wie zum Beispiel die aus[5]) und diese weiterhin benutzen möchte, sollte sie vor dem Upgrade in das neue Format überführen.
Das gelingt mit dem folgenden simplen Einzeiler: »sqlite OLD.DB .dump | sqlite3 NEW.DB«. Liegt das Modul DBD::SQLite nämlich in der neuesten Version vor, kann es Datenbanken, die mit früheren Versionen erzeugt wurden, nicht mehr lesen.
Startvorbereitungen
Das Dokumentenverzeichnis initialisiert die Variable »$DOC_DIR« in Zeile 19. Dieses Verzeichnis sollte der Anwender vor dem ersten Start anlegen und dessen Zugriffsrechte so einstellen, dass es für das Skript beschreibbar ist. Der Rest geschieht dann automatisch: SQLite erzeugt selbstständig die Datenbank in der Datei »scanned_docs.dat« (der Dateiname stammt aus Zeile 11) und richtet sich die beiden Tabellen ein.
Die interessantesten Artikel ausgelesener Zeitschriften scannen gewitzte Leser ab jetzt flugs ein und werfen das Heft anschließend in den Altpapiercontainer – und freuen sich über den so hinzugewonnenen Wohnraum. (jcb)
|
Infos |
|---|
|
[1] Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2005/05/Perl] [2] Sid Steward, “PDF Hacks”: O\’Reilly 2004 [3] SQLite Homepage: [http://www.sqlite.org] [4] Homepage des Sane-Projekts: [5] M. Schilli, “Trainierter DJ”: Linux-Magazin 07/04: [https://www.linux-magazin.de/Artikel/ausgabe/2004/07/perl/perl.html] |
|
Der |
|---|
|
Michael Schilli arbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat “Goto Perl 5” (deutsch) und “Perl Power” (englisch) für Addison-Wesley geschrieben und ist unter [mschilli@perlmeister.com] zu erreichen. Seine Homepage: [http://perlmeister.com]
|

|
Listing 1: |
|---|
001 #!/usr/bin/perl -w
002
003 use strict;
004
005 use DBI;
006 use Class::DBI::Loader;
007 use Sysadm::Install qw(:all);
008 use Getopt::Std;
009 use Text::Iconv;
010
011 my $DB_NAME = "scanned_docs.dat";
012 my $DSN = "dbi:SQLite:$DB_NAME";
013 my $UTF8_TERM = 0;
014
015 my $cv = Text::Iconv->new(
016 "Latin1", "utf8");
017 $cv->raise_error(1);
018
019 my $DOC_DIR = "/ms1/DOCS";
020
021 getopts("a:m:t:i:p:d:s:", my %o);
022
023 die "$DOC_DIR not ready" if
024 !-d $DOC_DIR or !-w $DOC_DIR;
025
026 db_init($DSN) unless -e $DB_NAME;
027
028 my $loader = Class::DBI::Loader->new(
029 dsn => $DSN,
030 namespace => "Scanned::DB",
031 additional_classes =>
032 qw(Class::DBI::AbstractSearch),
033 relationships => 1,
034 );
035
036 my $docdb = $loader->find_class("doc");
037 my $magdb = $loader->find_class("mag");
038
039 my @objs = ();
040
041 if(! exists $o{s}) {
042 my $mag = mag_pick($magdb, $o{m});
043 my $doc = $o{d} || ask "Document", "";
044 my $author = $o{a} || "";
045 my $title = $o{t} || ask "Title", "";
046 my $page = $o{p} || ask "Page", "";
047 my $issue = $o{i} || ask "Issue", "";
048
049 my $id = $mag->add_to_docs({
050 map { $UTF8_TERM ? $_ : $cv->convert($_) }
051 title => $title,
052 page => $page,
053 issue => $issue,
054 author => $author});
055
056 cp $doc, docpath($id);
057 exit 0;
058 }
059
060 my %search = ();
061
062 for (split ' ', $o{s}) {
063
064 my($field, $expr) = split /:/, $_;
065
066 if($field eq "mag") {
067 my @mags = $magdb->search_like(
068 name => "%$expr%");
069
070 $search{$field} = [
071 map { $_->id() } @mags];
072 } else {
073 $search{$field} = "%$expr%";
074 }
075 }
076
077 @objs = $docdb->search_where(%search, {cmp => "like"});
078
079 if(@objs) {
080 print join(", ",
081 '"' . $_->title() . '"' ,
082 $_->author() || "Unknown",
083 $_->mag()->name(),
084 $_->issue(),
085 $_->page(),
086 docpath($_->docid())),
087 "n" for @objs;
088 } else {
089 print STDERR "No entriesn";
090 }
091
092 ###########################################
093 sub docpath {
094 ###########################################
095 my($id) = @_;
096
097 return sprintf "%s/%06d",
098 $DOC_DIR, $id;
099 }
100
101 ###########################################
102 sub db_init {
103 ###########################################
104 my($dsn) = @_;
105
106 my $dbh = DBI->connect($dsn, "", "");
107
108 $dbh->do(q{
109 CREATE TABLE doc (
110 docid INTEGER
111 PRIMARY KEY,
112 title VARCHAR(255),
113 author VARCHAR(255),
114 mag INT REFERENCES mag,
115 page INT,
116 issue VARCHAR(32)
117 );
118 });
119
120 $dbh->do(q{
121 CREATE TABLE mag (
122 magid INTEGER
123 PRIMARY KEY,
124 name VARCHAR(255)
125 )
126 });
127 }
128
129 ###########################################
130 sub mag_pick {
131 ###########################################
132 my($magsdb, $picked) = @_;
133
134 my @mags = map { $_->name() }
135 $magsdb->retrieve_all();
136
137 if(@mags and !$picked) {
138 $picked = pick "Magazine",
139 ["New", @mags], 1;
140 undef $picked if $picked eq "New";
141 }
142
143 if(!$picked) {
144 $picked = ask
145 "Enter Magazine Name", "";
146 }
147
148 $picked = $UTF8_TERM ? $picked :
149 $cv->convert($picked);
150
151 my $mag = $magsdb->find_or_create(
152 {name => $picked});
153 return $mag;
154 }
|





