
© Kurhan, 123RF
Alle Wege führen in die Cloud, doch nicht wenige davon sind steinig und schwer: Wie Admins ein komplettes Setup unfallfrei in die Cloud verlagern und wie ein konventionelles Setup Cloud-Vorteile nutzt.
Cloud Computing hat die IT revolutioniert, und das wiederum führt dazu, dass sich bei Dienstleistern und Kunden allmählich die Prioritäten verschieben. Das geht schon bei den klassischen Hostern los, die immer stärker zu Plattformanbietern werden und Server nicht mehr für einzelne Kunden betreiben.
Das setzt sich fort bei den vielen Startups und kleineren Dienstleistern, die nun zum Zuge kommen, weil sich der Auftraggeber eher aus der Fülle bedient, als sich wie früher an einen Monopolisten zu binden. Und das endet bei Kunden, die immer stärker Ansätze wie Serverless http://1 nutzen und komplett aufhören selbst Infrastruktur zu betreiben.
Hardware ist mühsam
Für den Verzicht auf eigene Hardware gibt es aus Kundensicht ja auch gute Gründe: Die Wartung sowie der Betrieb eigener Hardware ist eine lästige, kostenintensive Aufgabe. Wer diese Arbeit einem Plattformanbieter überträgt, erschlägt mehrere Fliegen mit einer Klappe: Er wird die Assets im Rechenzentrum los, erspart sich zu einem erheblichen Teil Papierkram, und nicht selten sind Clouds auch noch günstiger, weil der Anbieter die Einsparungen, die er durch effiziente Prozesse erlangt hat, an seine Kunden durchreicht.
Aber einen Schönheitsfehler hat die Sache: Der Umzug von echtem Blech in die Cloud ist kein Selbstläufer. Wer sich den coolen Admin vorstellt, der mit einem Drink in der Hand in seiner Kommandozentrale sitzt und seinen Apps beim Umzug in die Cloud zuschaut, der verkennt die Realität. Die Migration in eine Cloudumgebung ist eine mühsame Angelegenheit. Viele Fettnäpfchen warten nur darauf, dass der Admin hineintritt.
Worauf Admins im Detail achten, wenn sie in die Cloud umziehen, zeigt dieser Artikel. So viel sei schon an dieser Stelle verraten: Meist ist es eben nicht ausreichend, einfach VMs in der Cloud anzulegen und Daten in diese zu kopieren (Abbildungen 1 und 2).
Abbildung 2: Die Nutzung von Clouds ist nicht komplex, wohl aber der Umzug eines nicht auf die Cloud ausgelegten Workloads.

Abbildung 1: Der Umstieg von echtem Blech auf VMs in der Cloud gestaltet sich in vielen Fällen schwierig.
Cloud-Dienstleistungen
Eine moderne Cloud bietet ihren Kunden viele Arten von Diensten. Klassisches Infrastructure as a Service (IaaS) bietet Admins virtuelle Systeme in Form von VMs oder Containern, in denen diese wie auch auf einem physischen Host ihre Dienste nach Belieben ausrollen. Der Vorteil: Fast alle Workloads, die zuvor auf physischen Servern liefen, lassen sich in eine IaaS-Umgebung verschieben.
Dennoch sind einige Punkte zu beachten. Wer bisher etwa einen Hochverfügbarkeitscluster betrieb, muss in einer Cloud umdenken: Pacemaker & Co., die auf das Prinzip einer Service-IP setzen, die im Falle eines Ausfalls einfach auf einen anderen Host umzieht, sind in Clouds nur schwer zu realisieren.
Hinzu kommt, dass IaaS die Vorteile von Cloudumgebungen nur bedingt nutzen kann. Clouds bieten heute schließlich viel mehr Funktionalität: Platform as a Service, Serverless Computing und verschiedene andere As-a-Service-Angebote sind darauf ausgelegt, dem Admin das Leben zu erleichtern. Im Rahmen des Umzugs in die Cloud spielen solche Dienste fast zwangsläufig eine Rolle.
Die zentrale Frage, um die Admins sich eingangs kümmern sollten, ist die nach der verfügbaren Zeit. Es ist nämlich ein erheblicher Unterschied, ob für den Umzug in die Wolke Zeit zum Planen zur Verfügung steht – oder ob der Umzug Hals über Kopf über die Bühne gehen muss, weil etwa RZ-Verträge auslaufen, die der Nutzer nicht mehr verlängern möchte. Natürlich ist die Variante für die Eiligen die deutlich komplexere.
Im Folgenden zeigt der Artikel zunächst Mittel und Wege, um von klassischen Hosted-Setups hin zu IaaS zu kommen. Danach dreht er sich um die Frage, wie sich die Dienste einer Cloud nutzen lassen, um das Setup besser zu machen. Am Ende geht der Artikel auch auf Design-Prinzipien für jene ein, die sich den Luxus leisten können, auf einer grünen Wiese zu beginnen.
Zuerst Ausgangslage erfassen
Gegeben sei also eine Situation, in der ein Unternehmen seinen kompletten Workload in die Cloud verlagern möchte. Bisher betrieb es die Applikation auf gemieteten Servern bei einem Standard-Hoster. In solchen Szenarien kommt es oft vor, dass der Admin unter Zeitdruck eine falsche Entscheidung trifft.
Aus der Not heraus fängt er an, einen direkten Umzug zu planen – zunächst wird aus den aktuell laufenden Systemen ein Festplattenabbild, das er im Anschluss als Image in die Cloud lädt, und schließlich startet er eine neue VM mit eben jenem Image. Klingt gut – warum dieser Ansatz dennoch in den meisten Fällen nicht funktioniert, verrät der Kasten “Warum der direkte Umzug schwierig ist”.
Warum der direkte Umzug schwierig ist
Wer seine Applikation noch auf echtem Blech oder in selbst gehosteten VMs auf Basis von KVM oder Xen betreibt, denkt vielleicht darüber nach, einfach Abbilder von diesen VMs zu bauen und diese direkt in der Cloud zu nutzen. Was wie eine gute Idee klingt, führt in Wirklichkeit meist zu Problemen und zu erheblichem Zeitverlust – aus technischen wie praktischen Gründen.
Zunächst gilt: Public Clouds wie AWS oder Azure sowie private Clouds etwa auf Basis von Open Stack erwarten bestimmte Formate für Volumes oder OS-Abbilder. Zudem existieren in Clouds meist ungeschriebene Gesetze, die festlegen, wie bestimmte Arbeitsschritte funktionieren. Wer sein statisches System etwa mit einer festen IP-Adresse versorgt hat, müsste das ändern, wenn die Applikationen in die Cloud umziehen sollen. Denn die Vergabe von IP-Adressen geschieht in Clouds ausschließlich per DHCP, damit das virtuelle Netz über die Cloud selbst verwalt- und steuerbar bleibt.
Clouds erwarten auch das Tool »cloud-init« in VMs, das auf einem klassischen physischen oder virtuellen System gar nicht vorhanden ist. Hinzu gesellen sich diverse Probleme beim Zugriff auf Festplatten, die je nach Distribution unterschiedlich benannt sind, unterschiedliche Pfade haben oder auf eigenartige Weise per »/etc/fstab« angesteuert werden.
Die Menge an Fallstricken ist dabei gigantisch: Wer eine bestehende VM tatsächlich in ein Image für eine Cloud umbauen möchte, wird dafür viel Arbeit und Zeit sowie Mühe brauchen – und am Ende trotzdem mit hoher Wahrscheinlichkeit kein ganz zufriedenstellendes Resultat erhalten (Abbildung 3).
Abbildung 3: In Clouds funktioniert vieles anders – ein gutes Beispiel etwa ist »cloud-init«, das viel Systemkonfiguration erledigt und die Daten dafür direkt von den Cloud-APIs bekommt.
Selbst dann, wenn der direkte Umzug in die Cloud gelingt, hat man hinterher wahrscheinlich eine hochgradig spezifische virtuelle Maschine, die an diversen Stellen manuell modifiziert worden ist. Damit widerspricht sie aber dem Cloud-Mantra “Automatisierung zuerst” und ist auch nicht ohne Weiteres wieder reproduzierbar. In den meisten Fällen lohnt es sich daher nicht, ein vorhandenes System so zu konvertieren, dass man es auf Biegen und Brechen in der Cloud betreiben kann.
Stattdessen tut der Admin gut daran, seinen Workflow an die Cloud anzupassen. Schritt 1 ist bei diesem Vorgehen eine Bestandsaufnahme: Der Admin verschafft sich einen Überblick, welche Systeme zu seiner Umgebung gehören. Das gelingt freilich am besten, wenn es ein DCIM-System (Data Center Infrastructure Management) wie etwa Netbox http://2 gibt, das entsprechende Infos per Mausklick liefert.
Gerade in konventionellen Setups, die historisch gewachsen sind, fehlen solche Informationssysteme aber oft. Dann bleibt nur Handarbeit übrig. Je besser der Admin das bestehende Setup erfasst, desto geringer ist jedenfalls die Gefahr, beim Umzug in eine Cloud zu scheitern.
Wie gut ist die Automatisierung?
Steht fest, was alles in die Cloud muss, stellt sich im nächsten Schritt die Frage, wie man das bestehende Setup in einer Cloud hochzieht. Setups mit hohem Automatisierungsgrad machen das viel leichter als ihre nicht automatisierten Verwandten: Betriebssystem-Abbilder stehen in den gängigen Clouds schließlich für alle relevanten Linux-Betriebssysteme zur Verfügung. Wer also eine Reihe von VMs startet und seine bereits fertige Automation auf diese loslässt, muss sich nur noch Gedanken um die Migration seiner bestehenden Daten machen – ist mit der Arbeit ansonsten aber fertig.
Ist der Automatisierungsgrad hingegen gering, wie das in konventionellen Umgebungen oft der Fall ist, gerät die Sache kniffliger. Wenn die Zeit drängt, wird der Admin kaum Gelegenheit haben, Automation schnell noch in das bestehende Setup einzubauen – das ist dann eine Aufgabe, die nach der Migration im Zuge der Optimierung für die Cloud ansteht. Hat der Admin es mit einem wenig automatisierten Setup zu tun, umfasst auch in einer Cloud der erste Schritt klassische Handarbeit.
Egal ob händisch oder automatisiert: Im nächsten Schritt des Umzuges legt der Admin idealerweise eine virtuelle Umgebung in seinem Bereich der Cloud an, die dem bestehenden Setup in Art, Umfang und Leistungsfähigkeit entspricht.
Cloud-Unterschiede
Wer bestehende Setups migriert, sollte allerdings auch dabei an die vielen kleinen Unterschiede zwischen Clouds und normalen Umgebungen denken. Da ist die weiter oben bereits erwähnte Netzwerkkonfiguration: Die fußt in Clouds auf DHCP; die statische Vergabe von IPs in VMs ist mit etwas Bastelei zwar auch machbar, verhindert jedoch das Verwalten virtueller Netze über die APIs der Cloud. Denn von einer statisch konfigurierten IP in einer VM weiß die Cloud ja erst mal nichts.
Knifflig ist in Clouds das Thema Hochverfügbarkeit. Außerhalb von Clouds wird dafür ja oft ein Cluster-Manager bemüht – etwa Pacemaker. Wer Daten redundant halten möchte, nutzt dafür regelmäßig geteilten Speicher mit Raid oder Software-Lösungen wie DRBD. Der Speicher-Teil ist in Clouds leicht zu realisieren: Die meisten Clouds bieten einen Volume-Dienst an, der in sich bereits redundant ist.
Indem der Admin die relevanten Daten also auf einem Volume ablegt, das sich bei Bedarf beliebig an VMs anhängen lässt, erschlägt er diesen Teil des Problems effektiv.
Schwieriger ist die Frage, wie sich typische Dienste, etwa eine Datenbank, hochverfügbar einrichten lassen. Denn die Kombination aus Pacemaker und Corosync, die IP-Adressen hin- und herschwenken, lässt sich in Amazons AWS gar nicht nutzen: Die zusätzliche IP ist für andere VMs im selben Subnetz nicht sichtbar, wenn sie nicht per AWS-API einem System fest zugewiesen ist.
Das allerdings widerspricht der Idee der umschwenkbaren IP-Adresse. Und der Ansatz, Pacemaker direkt mit dem AWS-API reden zu lassen, ist eine solche Bastellösung, dass sie bis jetzt noch niemand ernsthaft betrachtet oder gar implementiert hat.
Wer also Hochverfügbarkeit in Clouds realisieren möchte, setzt dazu fast zwangsläufig auf die Cloud-spezifischen Werkzeuge der jeweiligen Umgebung. Am Beispiel AWS lässt sich dank einer Anleitung im Netz [3] nachvollziehen, wie das aussehen kann. Dort erläutert der Autor des Howto, wie er AWS-Bordmittel nutzt, um eine schwenkbare Maria-DB-Instanz mit Hochverfügbarkeit zu erhalten.
Wie Daten in die Cloud kommen
Ganz ohne die Technik der Cloudumgebung wird sich übrigens auch die Frage kaum beantworten lassen, wie vorhandene Daten ihren Weg in die Cloud finden. Was wie eine triviale Aufgabe klingt, kann zur echten Stolperfalle werden – wie komplex der Vorgang tatsächlich ist, hängt auch davon ab, wie viele Daten tatsächlich zu übertragen sind.
Hat die Kundendatenbank beispielsweise nur wenige Gigabyte, wird es kein großes Problem sein, sie im Rahmen eines Wartungsfensters einmalig von A nach B zu kopieren. Ist der Umfang der Daten hingegen größer, macht das andere Maßnahmen nötig. Das Problem besteht ja gerade darin, dass die Daten sich nach der Synchronisation vom alten ins neue Setup auf der alten Seite nicht mehr verändern dürfen.
Einen Ausweg aus dem Dilemma bietet möglicherweise der Betrieb einer Datenbank im Zielsetup als Slave der noch produktiven Datenbank. Die meisten Cloudanbieter haben mittlerweile eine VPN-as-a-Service-Funktion, die es erlaubt, sich per VPN mit dem virtuellen Netz der virtuellen Umgebung in der Cloud zu verbinden. Der eigene Client verhält sich dann so, als sei er auch eine VM. Verbindet der Admin das alte Netz sowie das neue Netz auf diese Weise miteinander, kann im neuen Netz etwa eine Instanz von Maria DB im Slave-Modus laufen, die Updates vom Master erhält.
Dieser Ansatz löst auch das Problem, dass das neue Setup im Moment, in dem die Umschaltung erfolgt, nicht die aktuellsten Daten hat. Wer die Daten auf althergebrachte Art von A nach B händisch kopiert, müsste vor dem Go-Live von B jedenfalls eine erneute Synchronisierung anstoßen, um die letzten Daten zu kopieren, die sich nach der letzten Synchronisation noch geändert haben.
Nicht ganz so leicht ist die Antwort auf die Frage, wie klassische Assets wie Bilddateien ihren Weg in die Cloud finden und wie der Admin sein Setup so baut, dass anschließend alle nötigen Systeme Zugriff darauf haben. Klar: Wer bisher auf NFS gesetzt hat, kann auch in der Cloud einen NFS-Server aufsetzen und ihn die Asset-Daten hosten lassen.
Bleibt noch das Kopier-Problem: Wer ohnehin ein virtuelles VPN aufsetzt, nutzt Werkzeuge wie Rsync und legt inkrementelle Backups an. Wenn Quell- und Zielsystem irgendwie ins Netz kommen und zumindest eines von beiden eine öffentliche IP hat, lässt sich Rsync in den meisten Fällen auch per SSH nutzen. Dann ist aber wie bei der Datenbank eine finale Synchronisation notwendig.
Planung für den D-Day
Apropos Umschaltung: Benötigte Wartungsfenster plant der Administrator idealerweise im Voraus. Und ganz wichtig ist die Antwort auf die Frage, wie er dafür sorgt, dass Kunden ab einem bestimmten Zeitpunkt zum neuen und nicht mehr zu dem alten System geleitet werden. Das geht gewissermaßen ad hoc mit Protokollen wie BGP, was allerdings ein komplexes Netzwerksetup bedingt – und Zugriff auf Teile der Cloud, auf die man zumindest in großen Public Clouds keinen Zugriff hat.
Der DNS-basierte Ansatz ist besser: Zunächst reduziert der Admin in diesem die TTL seiner Host-Einträge oder zumindest jener Einträge, die beim Umzug eine Rolle spielen. Ist der Umschaltzeitpunkt samt Wartungsfenster gekommen, stellt er die DNS-Einträge entsprechend um. Durch die kürzere TTL holen sich die Nameserver, die die eigenen Kunden benutzen, beim nächsten Zugriff die neuen DNS-Daten – fertig ist der Lack.
Zwar gibt es DNS-Server, welche die TTL-Einstellung von Domains ignorieren. Der größte Teil der Kundschaft dürfte auf diese Weise aber zufriedenzustellen sein.
Cloud-Vorteile nutzen
Ist der Umstieg in die Cloud geglückt, knallen zunächst die Sektkorken. Wer wie beschrieben jedoch ein Setup ins Wolkenkuckucksheim umsiedelt, sieht sich im Anschluss mit einigen weiteren Aufgaben konfrontiert. Der Grund: Das Setup ist zwar innerhalb der Ziel-Cloud lauffähig. Doch an vielen Ecken bieten zumindest die öffentlichen Clouds zusätzliche Funktionen an, die den Betrieb einer virtuellen Umgebung viel einfacher machen.
Datenbanken sind dafür ein perfektes Beispiel: Jede Public Cloud bietet in irgendeiner Form einen Database-as-a-Service-Dienst an. Das ist im Grunde SaaS: Der Admin startet nicht eine virtuelle Maschine und zieht in dieser händisch eine Datenbank hoch. Stattdessen teilt er der Cloud per entsprechender API-Schnittstelle nur noch die Eckdaten der benötigten Datenbank mit – etwa: »MariaDB, Root-Passwort ‘admin’, hochverfügbar«. Die Cloud kümmert sich dann um den Rest.
Zwar läuft auch bei einem solchen Konstrukt am Ende eine reguläre VM, doch die konfiguriert die Cloudumgebung automatisch so, wie es der Admin festgelegt hat. Der verwaltet entsprechend nicht mehr jene VM als logische Größe, seine Einheit ist die Datenbank per se. Je nach Cloud-Implementierung ist dabei eine Vielzahl praktischer Funktionen verfügbar – etwa ein Backup per Klick, Snapshots oder das Anlegen von Benutzern in der Datenbank per Cloud-API.
Dass dieser Ansatz flexibler ist als die Pflege einer VM mit eingebauter Datenbank, liegt auf der Hand. Hinzu kommt noch, dass der Admin sich um Fragen wie Datenhaltung und Systempflege der VM nicht kümmern muss – bei Bedarf lässt sich in den meisten Clouds eine neue DBaaS-Instanz starten, an die vorhandene Daten angeklemmt werden.
Der Plan, verschiedene AaS-Angebot der gewählten Cloud zu nutzen, bezieht sich nicht nur auf offensichtliche Komponenten wie Datenbanken. Regelmäßig ist es eine gute Idee, sich die Möglichkeiten der jeweiligen Cloud mal im Detail anzusehen – denn Platform-as-a-Service-Angebote finden sich mittlerweile auch fast überall (Abbildung 4).
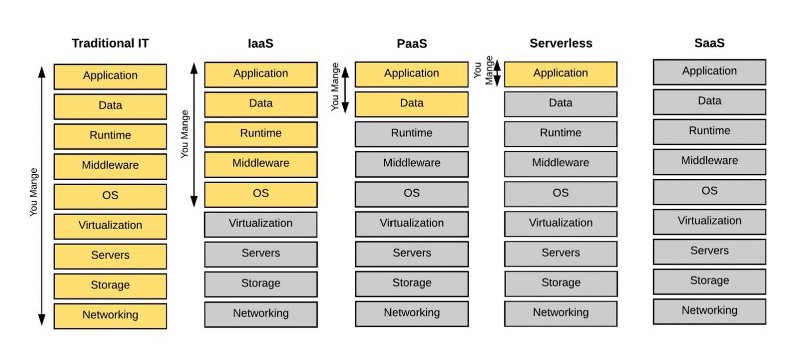
Abbildung 4: Verschiedene Betriebsmodelle in der Cloud bereiten dem Admin die Qual der Wahl. Es gilt: Je komfortabler der Betriebsmodus aus Kundensicht gelingt, desto größer ist der implizite Kontrollverlust.
Wer etwa einen Webserver braucht, um eine PHP- oder Go-Anwendung für seine Webumgebung zu betreiben, kann natürlich einen Fuhrpark aus Apache-VMs sowie entsprechender Konfiguration betreiben. Oder er übergibt diese Aufgabe an die PaaS-Komponente der jeweiligen Cloud: Die nimmt die zu betreibende Applikation beispielsweise als Tarball entgegen und rollt eine entsprechende VM aus, in der die Applikation dann läuft.
Der Vorteil: Die PaaS-Komponenten der Clouds sind oft mit pfiffigen Zusatzfunktionen wie einer automatischen Lastüberwachung ausgestattet, die bei Bedarf zusätzliche Instanzen der Applikation startet. Das funktioniert freilich nur dann, wenn der Admin auf die Load-Balancer-Funktion der jeweiligen Cloud zurückgreift – was sowieso dringend empfohlen sei. Denn auch LBaaS nimmt dem Admin aktiv Arbeit ab.
In Summe gilt: Alles was IaaS-Komponenten aus dem Setup tilgt, sollte der Admin in Erwägung ziehen. Je weniger klassische VMs er verwalten muss, desto leichter wird es, das Setup zu warten (Abbildung 5).
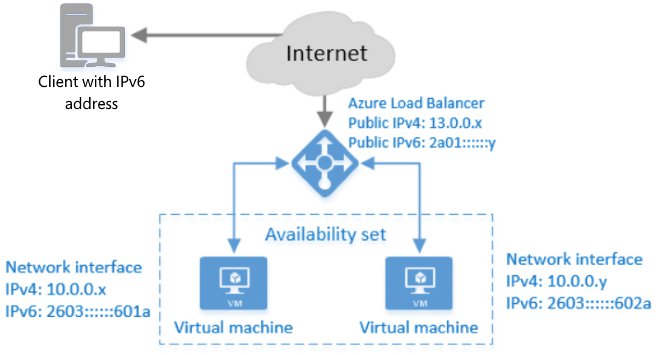
Abbildung 5: Clouddienste wie dynamisch konfigurierbare Load Balancer erleichtern dem Admin das Leben erheblich.
Das i-Tüpfelchen ist Orchestrierung: Wer diverse AaS-Angebote einer Cloud so kombiniert, dass sie zusammenspielen, und zudem seine IaaS-Komponenten sinnvoll automatisiert, bündelt am Ende per Orchestrierung alle Kräfte. Eine komplette virtuelle Umgebung mit allen benötigten Komponenten lässt sich dann mit Hilfe eines Orchestration-Template in wenigen Minuten aufsetzen.
Orchestrierte Umgebungen dieser Art nutzen die Vorteile, die Clouds liefern, gut aus: Sie erstellen virtuelle Netze und virtuelle Speichergeräte gleich zusammen mit den jeweiligen VMs.
Alles neu
Wer die bisher beschriebenen Ratschläge beim Umzug in die Cloud beherzigt, bekommt ein vielseitiges und auf die Cloud ausgelegtes Setup – das aber etwas Arbeit bedingt und am Ende noch immer nicht ganz perfekt adaptiert ist.
Wohl dem, der eine Umgebung gleich für den Betrieb in einer Cloud vorbereiten kann. Viele Unternehmen verstehen den Umzug in eine Cloudumgebung als willkommene Gelegenheit, alte Zöpfe radikal abzuschneiden. Das bedeutet nicht selten, sich von alter Software komplett zu trennen, wenn sie nicht zu den typischen Cloud-Mantras passt.
Zur Erinnerung: “Cloud Ready” bedeutet eigentlich, dass eine Anwendung für den Betrieb in einer Cloud mit ihren diversem AaS-Angeboten und APIs gemacht ist. Das impliziert verschiedene Details, die das Design der Anwendungen stark betreffen. Wichtiger Faktor ist etwa die Aufteilung einer Applikation in Microservices.
Es gilt die Regel: Pro Aufgabe eine Komponente. Das bringt im alltäglichen Betrieb viel Flexibilität und macht es auch einfach, die einzelnen Komponenten in Container zu verpacken und sie etwa im Rahmen eines Kubernetes-Clusters zu betreiben. Der kann schließlich auch eine Public Cloud sein.
Klar muss aber auch sein: Wer diesen Ansatz wählt, entscheidet sich für einen Marathon und nicht für einen Sprint. Insbesondere in den Szenarien, in denen Funktionalität in die Cloud wandern soll, die aktuell von steinalter Software realisiert wird, kann ein entsprechender Rewrite viel Zeit kosten.
Im Gegenzug erhält man ein perfekt an die Bedürfnisse von Clouds angepasstes Produkt, das klassischen “Cloud Ready”-Maßstäben folgt und diverse Probleme vermeidet, die beim Umzug konventioneller Software in die Cloud auftreten. Wer etwa auf Microdienste setzt und standardisierte APIs auf REST-Basis nutzt, um einzelne Komponenten seiner App miteinander kommunizieren zu lassen, umgeht viele Probleme im Hinblick auf Hochverfügbarkeit von vornherein.
Fazit
Egal, ob man sich den Luxus leistet, eine Applikation für die Cloud neu zu schreiben, oder bestehende Workloads in die Cloud übersiedelt: Die meisten Umgebungen lassen sich in Clouds gut betreiben. Wer perfekte “Cloud Readiness” will, kommt um einen Rewrite der Applikation selten herum, kann dabei aber eine neue Anwendung auf Basis modernster Standards schaffen, die der Cloud wie angegossen passt.
Wer das nicht kann, hat aber auch keinen Grund zur Panik: Konventionelle Applikationen lassen sich mit einigen Tricks und Kniffen in Clouds gut betreiben. Wichtig ist dabei allerdings, dass der Admin die Cloud als Verbündeten betrachtet und nicht als einen Gegner, um den er möglichst effizient herumarbeiten muss.
Auch wenn es um den Betrieb klassischer Workloads geht, sollte man verschiedene moderne Features der Ziel-Cloud keinesfalls außer Acht lassen – sondern sie im Gegenteil besser aktiv nutzen.
Infos
-
Schwerpunkt Serverless: Linux-Magazin 11/18, S. 20 ff.
-
Hochverfügbarkeit in AWS: http://www.linuxclustering.net/2016/03/21/step-by-step-how-to-configure-a-linux-failover-cluster-in-amazon-ec2-without-shared-storage-amazon-aws-sanless-cluster/
Der Autor

In seiner Freizeit Debian-Entwickler arbeitet Martin Gerhard Loschwitz beruflich als Telekom Public Cloud Architect bei T-Systems und beschäftigt sich beruflich vorrangig mit Themen wie Open Stack, Ceph und Kubernetes.






