
Ein CUPS (Common Unix Printing System) verbirgt seine komplexe Architektur so geschickt vor seinen Clients, dass die Installation eines Druckers mit dem KDE- oder CUPS-Assistenten kaum von der an einem Windows-Rechner zu unterscheiden ist.
CUPS als IPP-basiertes (Internet Printing Protocol,[1]) Server-Drucksystem für Linux-Clients bringt Vorteile: Zum einen unterstützt CUPS [2] neben allen Postscript-(Laser-)Druckern viele Tintenstahler, zum anderen ermöglicht der zentraler CUPS-Server eine Benutzerauthentifizierung, das Verschlüsseln von Druckdaten sowie das Beliefern der Clients mit Druckerspezifika. Zudem ist es in der Lage, die Druckertreiber zentral an die Clients zu verteilen.
Der folgende Beitrag demonstriert dem Systemadministrator eine effiziente CUPS-Konfiguration für ein typisches Büroszenario, das beispielsweise einen Postscript-Laser als Abteilungsdrucker sowie einen Tintenstrahler für den Präsentationsdruck ausmacht.
CUPS-Basics
In der CUPS-Begriffswelt ist jeder Host, der lokal einen Drucker nebst zugehörigem Treiber installiert hat und unmittelbar mit einem Ausgabegerät kommuniziert, ein Server. Die Funktion eines Druckertreibers bei Linux/CUPS umfasst die gesamte Aufbereitung der Druckjobs mit Filtern. Dazu verwaltet CUPS pro Gerät eine PPD-Beschreibungsdatei, die alle Gerätespezifika und deren Ansteuerung enthält, sowie ein Backend, das die Jobs über ein Protokoll versendet.
Rechner, die die Dienste eines CUPS-Servers über ein nicht-lokales Backend in Anspruch nehmen, sind Clients. Die Architektur von CUPS ähnelt der von Webservern, genauer: einem HTTP-Server mit IPP-Erweiterungen auf Port 631. Die Konfigurationsdatei »/etc/cups/cupsd.conf« ahmt auch die Apache-Konfigurationsdatei nach, denn das Internet Printing Protocol fußt auf HTTP 1.1 [1]. Basiswissen über den Kdeprint-Assistenten, das CUPS-Webinterface und die Architektur vermitteln[3],[4] und[5].
Server richtig dimensioniert
Sind viele Clients mit Druckdiensten zu versorgen, muss das CUPS-System der Last entsprechend ausgelegt sein. Der Server braucht zusätzlich Ressourcen, wenn er die Druckdaten der Clients aufbereiten soll und Treiber und Filter verwaltet muss. Mit Linux-Clients ist das der Normalfall. Im homogenen CUPS-Betrieb braucht der Admin kaum Installationsschritte an den Clients vorzunehmen. Anders ist das, wenn Windows-Clients ins Spiel kommen: Dann arbeitet CUPS eng mit Samba zusammen und ermöglicht es den Clients, ihre Druckertreiber vom Server zu installieren, was aber die Administration komplexer gestaltet und Ressourcen auf dem CUPS-Server bindet.[6]
Im Szenario für diesen Artikel stellt ein Abteilungs-Laserdrucker (im Folgenden ein Minolta-QMS) als echter Postscript-Drucker keine zusätzliche Anforderung, da die Raster-Engine des Geräts die Aufbereitung der Druckdaten selbst bewerkstelligt. Der CUPS-Server benötigt lediglich ausreichend Festplattenplatz zum Spoolen. Bei Nicht-Postscript-Druckern – so beim Farb-Tintenstrahler – übernehmen CUPS und Ghostscript die Aufbereitung der eingehenden Daten.
Der Ghostscript-RIP beansprucht unter Umständen einiges an Prozessorzeit, Arbeitsspeicher und Plattenplatz. Die Rasterdaten einer A3-Farbseite von Sechs-Farben-Tintenstrahldruckern erreichen mühelos 50 MByte. Da der CUPS-Server diese Leistung für alle Clients erbringen muss, sollte er großzügig dimensioniert sein. In größeren Umgebungen lassen sich CUPS-Server clustern und bieten so ein Load-Sharing oder Failover.
CUPS-Installation
Für den harten Netzwerkbetrieb ist es empfehlenswert, sich nicht mit der Default-Konfiguration der Linux-Distribution zu begnügen, sondern sich die aktuelle Version von[2] zu holen. Die Versionen jünger als 1.1.17 bringen zudem generische Postscript-Treiber für Windows-9x/NT/XP-Clients mit.
Zuvor ist der Admin gut beraten, ältere Drucksysteme wie Lprold oder Lprng zu deinstallieren. CUPS ersetzt bei der Installation existierende Kommandos und Dateien wie »printcap«, »lp«, »lpr«, »lpq«, »lpc«, »lpadmin« durch eigene. Im Anschluss an das Auspacken des CUPS-Archivs, etwa mit
tar xvzf cups-1.1.18.tar.gz
kann im CUPS-Verzeichnis das mitgelieferte Installationsskript
./cups.install
mit Root-Rechten aufgerufen werden. (Das CUPS-Deinstallationsskript heißt »cups.remove«.) Die Installation mit »cups.install« ist auch insofern von Vorteil, da sie ältere CUPS-Konfigurationsdateien (etwa CUPS 1.1.15 bei SuSE 8.1) nicht überschreibt. Vielmehr erzeugt sie zunächst die neue Konfiguration als »cupsd.conf.N« neben der alten. Letztere muss der Admin daher erst sichern und die neue dann umbenennen.
Basiskonfiguration
Zur Konfiguration enthält CUPS mehrere Werkzeuge: ein Kommandozeilen-Tool, das Webinterface und das Kdeprint-Kontrollfeldmodul »kups«. Für das geschilderte Szenario ist es sinnvoll, die Basiskonfiguration mit einem grafischen Konfigurationswerkzeug vorzunehmen. Speziellere Anpassungen erfolgen anschließend in der CUPS-Konfigurationsdatei. Das Einrichten neuer Drucker mit Hilfe des CUPS-Drucker- oder Klassen-Assistenten ist bekannt:[3],[4],[5]. Wichtiger für den Netzwerkdruck ist die Konfiguration des CUPS-Servers selbst, sie erfordert Administratorrechte. Der Assistent startet aus der Iconleiste des Kdeprint-Kontrollfeld-Moduls.
Um den CUPS-Server für den hier vorgesehenen Einsatzzweck anzupassen, sind die einzelnen Konfigurationsmodule der Reihe nach abzuarbeiten. Beim Vergeben des CUPS-Server-Namens in dem Modul »Server« ist es ratsam, die Default-Einstellung »localhost« mit einem sinnvollen Namen zu überschreiben. Außerdem sollte an dieser Stelle die E-Mail-Adresse des CUPS-Administrators eingetragen werden.
Das Feld »Classification« vermerkt den »Classification-Level«, etwa »vertraulich«. Ein abweichender Pfad zur BSD-Konfigurationsdatei »printcap« kann dann genauso eingetragen werden wie das Printcap-Format – bei Linux-Systemen normalerweise »BSD«. Im »Netzwerk«-Modul sollte der Admin »Hostname-Lookups« aktivieren. Hier kann er auch die zulässige Anzahl von Clients und die maximale Druckjob-Größe angeben. Angesichts des Profi-Anspruchs der Aufgabenstellung sollte er von der zweiten Möglichkeit Gebrauch machen und die Vorgabe »Unlimited« überschreiben.
Das Feld »Listen to« vergibt den CUPS-TCP-Port. Aus Sicherheitsgründen ist es empfehlenswert, nicht die Vorgabe zu verwenden. Die Schaltfläche »Hinzufügen« versetzt den Admin in die Lage, einen weiteren CUPS-(Relay-)Server mit Name/Adresse und Port in die Konfiguration aufzunehmen, um ein Failover-Szenario zu realisieren (Abbildung 1). Die Verbindung zum entfernten Server kann über SSL gesichert sein.
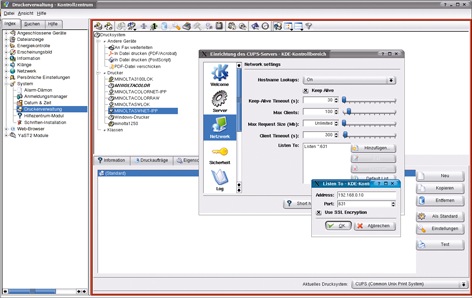
Abbildung 1: Die Schaltfläche »Hinzufügen« versetzt den Admin in die Lage, einen weiteren CUPS- (Relay-)Server in die Konfiguration aufzunehmen. Deren Verbindung kann über SSL gesichert sein.
Wichtig für das behandelte Beispiel ist das Modul »Sicherheit«, wo zunächst die Pfade für die SSL-Zertifikate und -Schlüssel zu prüfen sind. Außerdem lassen sich die CUPS-Locations (siehe unten) anpassen. Locations sind alle Verzeichnisse, die der CUPS-Server exportiert – ähnlich den Verzeichnissen eines Webservers ausgehend vom Document-Root. Jede Location ist gezielt mit Zugriffsrechten einstellbar.
Das Modul »Log« konfiguriert die CUPS-relevanten Log-Verzeichnisse. Auch die zulässige Größe der Logfiles ist hier begrenzbar. Den Loglevel sollte der Admin anfangs von »General Information« auf »Debug-Information« hochsetzen. Das Modul »Druckaufträge« begrenzt die Maximalzahl an Jobs sowie die Jobanzahl pro Drucker beziehungsweise pro User, um den Ressourcenverbrauch des CUPS-Servers zu steuern.
Im Modul »Filter« sollte der Bediener den RIP-Cache vergrößern, falls der Tintenstrahldrucker größere Druckaufträge zu verarbeiten hat. Das Modul »Verzeichnisse« ist wichtig, will man mit unterschiedlichen CUPS-Versionen experimentieren. Denn hier besteht die Möglichkeit, die von der CUPS-Basisinstallation verwendeten Verzeichnisse anzupassen.
|
Tipp |
|---|
|
Die CUPS-Konfigurationsdatei kann zahlreiche Einstellungen, Optionen und IPP-Parameter aufnehmen, die das grafische CUPS-Konfigurationsprogrammen nicht beherrscht. Auch über die Kommandozeile sind IPP-Parameter zugänglich, die sich nicht in den CUPS-GUI-Werkzeugen widerspiegeln. Systemadministratoren tun darum gut daran, sich in der Dokumentation zu informieren. |
Browsing und Broadcasting
Ein wesentlicher Vorteil von IPP gegenüber dem LPD-Protokoll ist sein Browsing, das den Clients das Auffinden von Printressourcen ermöglicht: Die CUPS-Hosts veröffentlichen im LAN automatisch Druckressource-Listen. Alle Hosts kommunizieren dazu permanent im LAN miteinander über den IPP-Port 631 (frei konfigurierbar). Da die aktuellen CUPS-Versionen die Browsing-Parameter recht restriktiv vorbelegen, gelingt es aber erst nach zähem Basteln, den Netzwerkdruck in einer homogenen Linux-Client-Landschaft aufzubauen.
Das wichtige Modul »Durchsuchen« steuert das Browsing des Servers (Abbildung 2). Sobald der Admin das Browsing bei einem Host durch die Checkbox »Use Browsing« einschaltet, sendet der in Zeitintervallen per UDP-Broadcasts seinen Namen und gegebenenfalls Zusatzinfos sowie einige Status-Bits der lokal angeschlossenen Drucker. In der Datei »cupsd.conf« heißt der korrespondierende Parameter »Browsing On«.
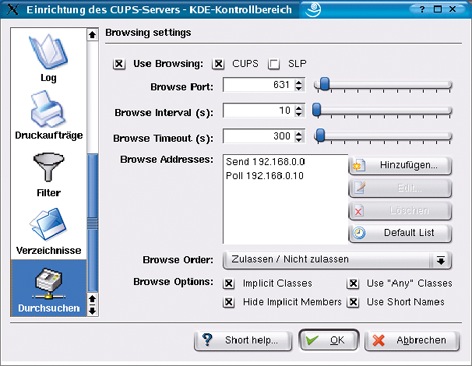
Abbildung 2: Das Modul »Durchsuchen« steuert das Browsing des Servers.
Der Browse-Port ist normalerweise identisch mit dem CUPS-Port. Das Intervall der UDP-Rundrufe ist von 30 Sekunden auf einen kleineren Wert kürzbar, wenn dazu genügend Ressourcen zur Verfügung stehen, denn jeder Broadcast belastet das Netz. Die »cupsd.conf« stellt diese Zeitabstände mit der Direktive »BrowseIntervall Sekunden« ein.
Die Arbeit mit den beiden Parametern »BrowseAddress« und »BrowseOrder« hat das Ziel, den Browse-Bereich auf das Subnetz der eigenen Abteilung zu beschränken, um unnötige Broadcast-Versuche in die Außenwelt oder Druckversuche (und Angriffe) von anderen Abteilungen und von draußen zu vereiteln. Achtung: Ältere CUPS-Versionen browsen per Default (»255.255.255.255«) an alle Netze aller Host-Routen! Daher neigen die Voreinstellungen der CUPS-Versionen kleiner als 1.1.14 dazu, zyklisch Dial-up-Verbindungen zum Internet-Provider aufzubauen, nur um die Broadcast-Aufforderung des CUPS-Daemon zu beantworten.
Alle CUPS-Daemons beobachten permanent den Port 631, um die Broadcast-Informationen der Server aufzufangen und in ihrem Cache abzulegen. Dabei kann der Admin die Gültigkeitsdauer der gecachten Informationen mit »Browse Timeout« etwa auf fünf Minuten (also 300 Sekunden) beschränken.
Laut TCP/IP-Spezifikation funktionieren Broadcasts nur lokal; daher schaffen es die Browsing-Informationen auch nur bis zum nächsten Router oder Gateway. Dass ein Linux-Desktop nur die Browse-Informationen des zuständigen CUPS-Servers benutzt, ist mit den Parametern »BrowseAllow« und »BrowseDeny« in Kombination mit »BrowseOrder AllowDeny« erzwingbar.
Polling
Im Gegensatz zum Browsing, bei dem der CUPS-Server die Ressource-Informationen aktiv publiziert, geht das Polling vom Client aus. Er fordert aktiv die Druckerlisten vom Server an. Polling ist eine sinnvolle Alternative zum bequemeren Browsing, wenn der CUPS-Server bereits stark ausgelastet ist, denn das Browsing fordert den Server merklich.
Beim Polling liefert der Server seine Liste nur aus, wenn eine Anforderung vom Client eingeht. Dazu ist der Client für Polling-Betrieb zu konfigurieren: In der CUPS-Verwaltung klickt man im Modul »Durchsuchen« auf »Hinzufügen« und wählt, sobald sich das »Browse Adress«-Dialogfeld öffnet, im »Typ«-Listenfeld »Poll« und trägt im Feld »Von« den Namen des CUPS-Servers ein. Das Feld »An« bleibt inaktiv (Abbildung 3).
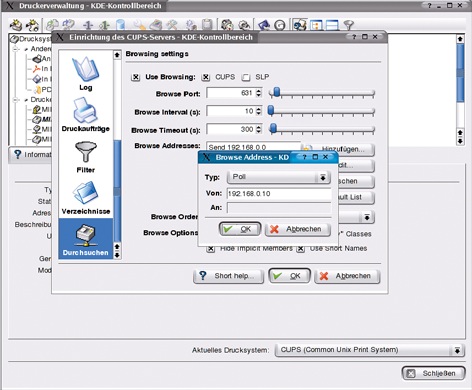
Abbildung 3: Polling: Sobald sich das »Browse Adress«-Dialogfeld öffnet, wählt man im »Typ«-Listenfeld »Poll« und trägt den Namen des CUPS-Servers ein.
Nun besorgt sich der Client eine aktuelle Browse-Liste beim spezifizierten Server, sobald ein Druckauftrag ansteht. Browsing und Polling sind so elementar, dass es ratsam ist, sich mit Funktion und den Parametern umfänglich zu befassen. Das Lastverhalten des Servers und der Administrationskomfort sind davon abhängig.
Backends und Rechte
Ist der CUPS-Servers fertig konfiguriert, kann sich jeder CUPS-Client im Netz mit dessen Druckern verbinden. Das klappt freilich nur bei entsprechender Berechtigung. Beim ersten Versuch zeigt sich nämlich, dass der CUPS-Server in der Default-Konfiguration keine Drucker-Locations über das Netz freigibt.
CUPS kennt sowohl Benutzer- als auch Host/Client-Berechtigungen. Außerdem lassen sich die Browse-Listen wie gezeigt einschränken. Hier ist die Kenntnis des Admin gefragt. Anders beim Einrichten des Druck-Clients: Auf dem muss lediglich der CUPS-Druckereinrichtungs-Assistent aufgerufen werden.
Protokolle satt
Zum Verbinden des CUPS-Druckers sind im Einrichtungsassistenten zahlreiche Schnittstellen und Protokolle wählbar, neben parallel, seriell und USB für lokale Verbindungen stehen die Netzwerkprotokolle IPP, LPD, HP Jet Direct, SMB und andere. Die korrekte Einstellung für das vorgegebene Szenario ist »CUPS-Server (IPP/HTTP) auf Fremdrechner«.
An dieser Stelle führen die Sicherheitsrestriktionen der CUPS-Standardinstallation dazu, dass die Location »Alle Drucker« nicht per URI adressierbar ist und folglich kein Drucker des CUPS-Servers in der Browse-Liste auftaucht. Erst nachdem die Locations freigegeben sind (»All Printer / Alle Drucker«), lässt sich der Remote-Drucker lokalisieren (siehe weiter unten).
Hierzu sind nach dem Authentifizieren als Administrator (oder Gast) Name und Port des entfernten CUPS-Servers anzugeben (Abbildung 4 und 5). Nun ist der Drucker in der Browse-Liste des CUPS-Servers wählbar, sofern die Location des betreffenden Druckers (was sicherer ist) beziehungsweise »Alle Drucker« am Server zugriffsberechtigt geschaltet ist.
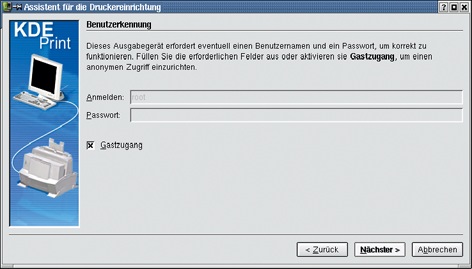
Abbildung 4 und 5: Um die Locations des CUPS-Servers vom Client aus freigeben zu können, sind nach dem Authentifizieren als Administrator (beziehungsweise als Gast) Name und Port des entfernten CUPS-Servers anzugeben.
Der nächsten Schritt im Assistenten bestimmt den Treiber. Einer der großen Vorteile von CUPS ist, dass Client-seitig auf Wunsch kein Treiber erforderlich ist, da schon der CUPS-Server mit den zugehörigen Treibern ausgestattet ist. Es genügt die Einstellung »Rohdaten-Drucker«. Wenn zur besseren Lastverteilung erwünscht, lässt sich aber auch ein Druckertreiber am Client installieren.
Sind auf den beteiligten CUPS-Rechnern Browsing und Polling aktiv, gerät die Browse-Liste schnell unübersichtlich: Manche Drucker tauchen dann als lokaler Drucker auf, aber auch als Netzwerkdrucker des entfernten CUPS-Servers, der sich als Client mit diesem Drucker verbunden hat und umgekehrt. Doch bleiben die Netzwerkdrucker von lokalen Druckern dank eines Symbols unterscheidbar.
Berechtigungen und Locations
Wie jeder Webserver verwaltet auch der CUPS-Daemon verschiedene reale und virtuelle Ressourcen, die dabei Locations heißen. Die Locations einer CUPS-Standardinstallation sind:
/admin/ /printers/ /printers/Druckername /printers/Druckername.ppd /jobs/ /classes/ /classes/Klassenname
Der Client kann Locations direkt per Browser ansprechen, indem der URI-Pfad zum CUPS-Server-Wurzelverzeichnis um die Bezeichnung der Location ergänzt wird. Über die Standard-Location »admin« ist so das bekannte CUPS-Web-Administrations-Frontend zu erreichen:
http://Servername:631/admin/
In analoger Weise lässt sich (prinzipiell) gezielt ein Drucker administrieren, beispielsweise:
http://thales:631/printers/MINOLTACOLOR
Wie beim Druckereinrichtungs-Assistenten des Clients zeigt sich allerdings, dass per Default die Berechtigung fehlt, die Location zu betreten. (Nur die Locations »Basis« und »Verwaltung« werden immer exportiert.) Das ändert sich erst durch das Hinzufügen der Location – im Beispiel: »Drucker MINOLTACOLOR« – ins Modul »Sicherheit« der CUPS-Server-Administration. Das zugehörige Dialog-Feld richtet auch Sicherheitsmerkmale wie Authentifikation, Encryption oder ACLs ein (Abbildung 6).
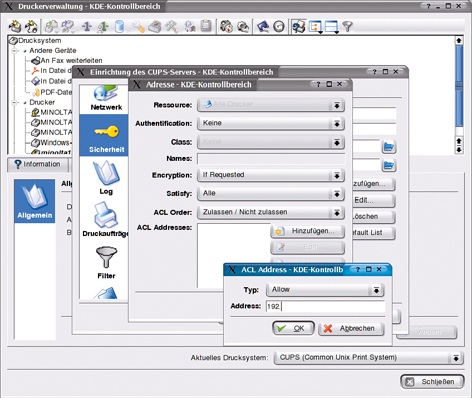
Abbildung 6: Das Administrationsmodul eines CUPS-Servers listet die ACLs auf, wenn man bei einer Location die »Edit«-Schaltfläche betätigt.
Das Hinzufügen der Location »Alle Drucker« oder (meist besser) die namentliche Freigabe wie »Drucker MINOLTACOLOR« ist somit für den Netzwerkdruck obligatorisch. Nun ist der Drucker problemlos über die genannte URI adressierbar und steht auch bei der Backendauswahl im CUPS-Druckereinrichtungs-Assistenten auf dem Client zur Wahl.
Authentifizierung, Verschlüsselung und Logfiles
Ein IPP-Server wie CUPS erlaubt es (wie jeder HTTP-Server) dem Admin, Zutrittsberechtigungen zu den einzelnen Locations differenziert zu vergeben. Die eben mit wenigen Handgriffen im Modul »Sicherheit« geänderten Zugriffsrechte (siehe oben und Abbildung 6) spiegeln die »AuthType«-Direktiven in der Konfigurationsdatei wider: »AuthType None« bedeutet den Verzicht auf jede Authentifizierung und »AuthType Basic« aktiviert die HTTP-Basismethode.
Zusätzlich lässt sich der Zugriff auf CUPS-Locations wie Drucker und Klassen von der Art und Herkunft des Benutzers abhängig machen. Dazu dienen die aus der Apache-Konfiguration bekannten Direktiven »AllowFrom« und »DenyFrom« mit der Auswertungsreihenfolge »Order Allow,Deny« beziehungsweise »Order Deny,Allow«. Das CUPS-Server-Administrationsmodul listet diese ACLs, wenn man bei einer Location die »Edit«-Schaltfläche betätigt. Bei den Direktiven »All«, »None«, »Host-Name«, »IP-Adresse« und »Domain-Name« ist der Platzhalter »*« erlaubt.
Sobald weiter entfernt stehende Clients auf den CUPS-Server zugreifen, ist noch die Verschlüsselung der Druckjobs wichtig. CUPS unterstützt das asymmetrische Verschlüsselungsverfahren TLS (Transport Layer Security), das von Netscapes SSL3 (Secure Socket Layer Version 3) abgeleitet ist.
Für den Admin besonders praktisch ist der Umstand, dass ein CUPS-Server über jede einzelne verarbeitete Druckseite detailliert Buch führt. Die zugehörige Logdatei ist »/var/log/cups/page_log«. Dort hat jeder Eintrag die Form:
Druckername Benutzer Job-Nr. [Datum+Uhrzeit] Seiten-Nummer Auflage
Die Datei kann der Systemverantwortliche beliebig auswerten.
Fazit
CUPS macht nicht nur das Drucken unter Linux für Heimanwender einfacher, es gibt auch dem Administrator eines Netzes mit Linux-Desktops ein Instrument in die Hand, über das die Clients verwaltungsarm alle Abteilungsdrucker benutzen können. Dabei greift die Berechtigungssteuerung.
Außerdem ist CUPS dank IPP komfortabel administrierbar und lässt sich im Cluster betreiben. Dank der Zusammenarbeit mit Ghostscript laufen zahllose Drucker unter Linux auch ohne Zutun der Herstellers klaglos. Am überzeugendsten sind aber die Browsing- und Broadcasting-Eigenschaften dieser IPP-Implementierung. (jk)
|
Infos |
|---|
|
[1] Informationen über das Internet Printing Protocol: [http://www.pwg.org/ipp/] [2] CUPS-Homepage und Download: [http://www.cups.org/software.html] [3] CUPS-Dokumentation: [http://www.cups.org/documentation.html] [4] CUPS-FAQ von Kurt Pfeifle: [http://www.danka.de/printpro/faq.html] [5] U. Wolf, “Druck-O-Matic – Das Common Printing System”: Linux-Magazin 09/01, S. 48 [6] J. Apel, “Druckverteiler – Drucken mit Samba”: Linux-Magazin 02/03, S. 42 |






